DBUnitでテストデータを追加後にデータ検索メソッドのテストを実施してみた
DB接続に関するテストをJUnitで実施するには、DBUnitというツールを利用すると、テストメソッドを実行する前に、データを追加したり削除したりすることができる。
今回は、追加用データをXMLとCSVそれぞれで準備し、準備したデータを追加後に、データ検索メソッドの実行を確認するJUnitのテストを実行してみたので、そのサンプルプログラムを共有する。
前提条件
下記記事の実装が完了していること。

作成したサンプルプログラムの内容
作成したサンプルプログラムの構成は以下の通り。
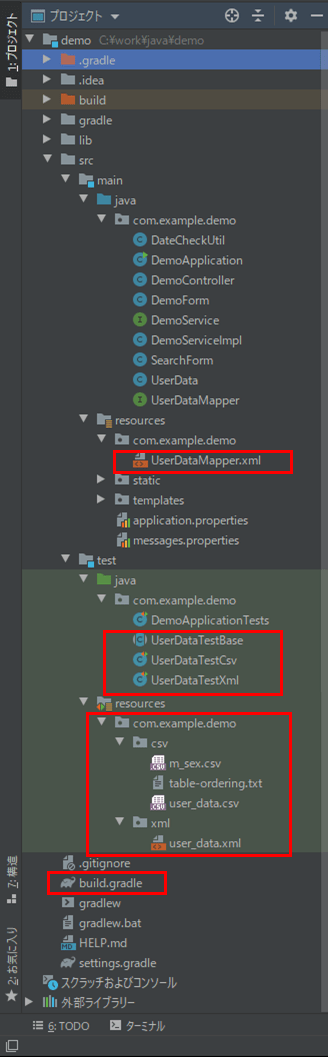
なお、上図の赤枠は、前提条件に記載したソースコードと比較し、変更になったソースコードを示す。赤枠のソースコードについては今後記載する。
まず、build.gradleには、以下のように、DBUnitを利用できる設定を追加している。
plugins {
id 'org.springframework.boot' version '2.1.7.RELEASE'
id 'java'
}
apply plugin: 'io.spring.dependency-management'
group = 'com.example'
version = '0.0.1-SNAPSHOT'
sourceCompatibility = '1.8'
repositories {
mavenCentral()
}
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-thymeleaf'
implementation 'org.springframework.boot:spring-boot-starter-web'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
compileOnly 'org.projectlombok:lombok:1.18.10'
annotationProcessor 'org.projectlombok:lombok:1.18.10'
compile files('lib/ojdbc6.jar')
implementation 'org.mybatis.spring.boot:mybatis-spring-boot-starter:2.1.1'
//DBUnitについての設定を追加
testCompile group: 'org.dbunit', name: 'dbunit', version: '2.6.0'
testCompile group: 'com.github.springtestdbunit', name: 'spring-test-dbunit', version: '1.3.0'
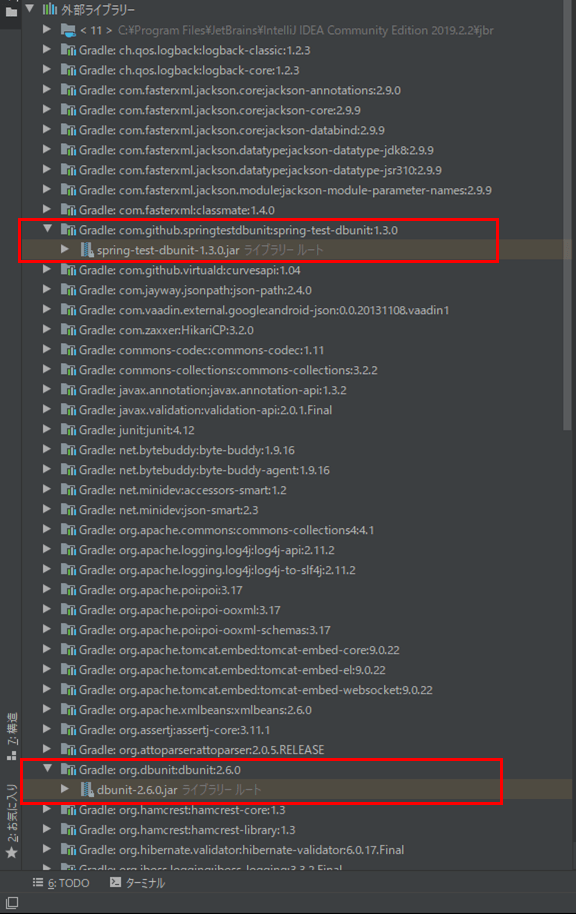
}上記のようにbuild.gradleにDBUnitの設定を追加すると、以下のように、外部ライブラリでDBUnitのライブラリが追加されていることが確認できる。
また、今回テスト対象となるUserDataMapperクラスのSQLファイルは以下の通り。今回はfindByIdメソッドがテスト対象となる。
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.demo.UserDataMapper">
<select id="findBySearchForm" parameterType="com.example.demo.SearchForm"
resultType="com.example.demo.UserData">
SELECT u.id, u.name, u.birth_year as birthY, u.birth_month as birthM
, u.birth_day as birthD, u.sex as sex, m.sex_value as sex_value
FROM USER_DATA u, M_SEX m
WHERE u.sex = m.sex_cd
<if test="searchName != null and searchName != ''">
AND u.name like '%' || #{searchName} || '%'
</if>
<if test="fromBirthYear != null and fromBirthYear != ''">
AND #{fromBirthYear} || lpad(#{fromBirthMonth}, 2, '0')
|| lpad(#{fromBirthDay}, 2, '0')
<= u.birth_year || lpad(u.birth_month, 2, '0')
|| lpad(u.birth_day, 2, '0')
</if>
<if test="toBirthYear != null and toBirthYear != ''">
AND u.birth_year || lpad(u.birth_month, 2, '0')
|| lpad(u.birth_day, 2, '0')
<= #{toBirthYear} || lpad(#{toBirthMonth}, 2, '0')
|| lpad(#{toBirthDay}, 2, '0')
</if>
<if test="searchSex != null and searchSex != ''">
AND u.sex = #{searchSex}
</if>
ORDER BY u.id
</select>
<select id="findById" resultType="com.example.demo.UserData">
SELECT u.id, u.name, u.birth_year as birthY
, u.birth_month as birthM , u.birth_day as birthD
, u.sex, m.sex_value as sex_value
FROM USER_DATA u, M_SEX m
WHERE u.sex = m.sex_cd AND u.id = #{id}
</select>
<delete id="deleteById" parameterType="java.lang.Long">
DELETE FROM USER_DATA WHERE id = #{id}
</delete>
<insert id="create" parameterType="com.example.demo.UserData">
INSERT INTO USER_DATA ( id, name, birth_year, birth_month, birth_day, sex )
VALUES (#{id}, #{name}, #{birthY}, #{birthM}, #{birthD}, #{sex})
</insert>
<update id="update" parameterType="com.example.demo.UserData">
UPDATE USER_DATA SET name = #{name}, birth_year = #{birthY}
, birth_month = #{birthM}, birth_day = #{birthD}, sex = #{sex}
WHERE id = #{id}
</update>
<select id="findMaxId" resultType="long">
SELECT NVL(max(id), 0) FROM USER_DATA
</select>
</mapper>


![]()
![]()
さらに、XMLとCSVでデータ追加を行うテストクラスに共通の処理を、以下で定義している。
package com.example.demo;
import org.dbunit.database.DatabaseConnection;
import org.dbunit.database.IDatabaseConnection;
import org.dbunit.dataset.IDataSet;
import org.dbunit.operation.DatabaseOperation;
import org.junit.Before;
import java.sql.Connection;
import java.sql.DriverManager;
public abstract class UserDataTestBase {
/**
* テストケース(サブクラスのuserDataMapperFindByIdTestメソッド)実行前に
* データベースの指定テーブルデータを更新する処理
*/
@Before
public void setUp(){
IDatabaseConnection connection = null;
try{
// データベース接続用コネクションを取得
connection = this.getDatabaseConnection();
// データベースに追加するデータファイルを指定
IDataSet iDataset = this.getIDataSet();
// データベースの指定テーブルデータを、全データ削除後に、
// 追加するデータファイルの内容に変更
DatabaseOperation.CLEAN_INSERT.execute(connection, iDataset);
}catch (Exception e){
System.err.println(e);
}finally {
if(connection != null){
try{
// データベース接続用コネクションをクローズ
connection.close();
}catch (Exception e){
System.err.println(e);
}
}
}
}
/**
* データベースに追加するデータファイルを指定
* (本実装はサブクラスで行う)
* @return データセットオブジェクト
*/
protected abstract IDataSet getIDataSet();
/**
* Oracleデータベース接続コネクションを取得
* @return Oracleデータベース接続コネクション
*/
private IDatabaseConnection getDatabaseConnection(){
try{
// Oracleデータベース接続用ドライバクラスを指定
Class.forName("oracle.jdbc.driver.OracleDriver");
// Oracleデータベース接続コネクションに接続URL,ユーザーID,パスワードを指定
Connection jdbcConnection = DriverManager.getConnection(
"jdbc:oracle:thin:@localhost:1521:xe","USER01" ,"USER01");
// 返却用データベースコネクションを取得
// その際、第二引数にスキーマ名を指定
// (そうしないとAmbiguousTableNameExceptionが発生する)
IDatabaseConnection iDatabaseConnection
= new DatabaseConnection(jdbcConnection, "USER01");
// データベースコネクションを返却
return iDatabaseConnection;
}catch (Exception e){
System.err.println(e);
}
return null;
}
/**
* 想定結果となるUserDataオブジェクトを取得
* @return 想定結果となるUserDataオブジェクト
*/
protected UserData getExpectedUserData(){
UserData userData = new UserData();
userData.setId(1);
userData.setName("テスト プリン");
userData.setBirthY(2012);
userData.setBirthM(2);
userData.setBirthD(28);
userData.setSex("2");
userData.setSex_value("女");
return userData;
}
}
上記クラスでは、ファイルのデータをデータベースに取り込む処理と、結果確認用オブジェクト生成処理を定義している。ファイルのデータを取り込む処理は、サブクラスで実装するようになっている。
また、データベース接続する際は、AmbiguousTableNameException例外の発生を防ぐために、スキーマ名を指定している。

さらに、データベースに取り込むファイル(XML)を指定しデータ検索メソッドの実行を確認するクラスは、以下の通り。
package com.example.demo;
import org.dbunit.dataset.IDataSet;
import org.dbunit.dataset.xml.FlatXmlDataSetBuilder;
import org.junit.Test;
import org.junit.runner.RunWith;
import static org.junit.Assert.assertEquals;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.io.FileInputStream;
// Spring BootのDIを利用するため、SpringRunnerクラスで、
// @SpringBootTestアノテーションを付与して実行
@RunWith(SpringRunner.class)
@SpringBootTest
public class UserDataTestXml extends UserDataTestBase{
@Autowired
private UserDataMapper userDataMapper;
/**
* {@inheritDoc}
*/
@Override
protected IDataSet getIDataSet(){
IDataSet iDataset = null;
try{
iDataset = new FlatXmlDataSetBuilder().build(
new FileInputStream(System.getProperty("user.dir")
+ "\\src\\test\\resources\\com\\example\\demo\\xml\\user_data.xml" ));
}catch (Exception e){
System.err.println(e);
}
return iDataset;
}
/**
* ユーザーデータのテーブルデータを取得し、結果を確認
*/
@Test
public void userDataMapperFindByIdTest(){
UserData userData = userDataMapper.findById(Long.valueOf("1"));
System.out.println("取得した値 : " + userData.toString());
assertEquals(super.getExpectedUserData().toString(), userData.toString());
}
}
また、このときに取り込むXMLファイル「user_data.xml」の内容は以下の通り。
<dataset>
<user_data id="1"
name="テスト プリン"
birth_year="2012"
birth_month="2"
birth_day="28"
sex="2" />
<user_data id="2"
name="テスト プリン2"
birth_year="2013"
birth_month="3"
birth_day="19"
sex="1" />
<m_sex sex_cd="1"
sex_value="男"/>
<m_sex sex_cd="2"
sex_value="女"/>
</dataset>上記定義により、user_dataテーブルとm_sexテーブルそれぞれに、レコードが2件ずつ追加される。各テーブル名のタグ内に、各カラムの設定値を指定している。
さらに、データベースに取り込むファイル(CSV)を指定しデータ検索メソッドの実行を確認するクラスは、以下の通り。
package com.example.demo;
import org.dbunit.dataset.IDataSet;
import org.dbunit.dataset.csv.CsvDataSet;
import org.junit.Test;
import org.junit.runner.RunWith;
import static org.junit.Assert.assertEquals;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.io.File;
// Spring BootのDIを利用するため、SpringRunnerクラスで、
// @SpringBootTestアノテーションを付与して実行
@RunWith(SpringRunner.class)
@SpringBootTest
public class UserDataTestCsv extends UserDataTestBase{
@Autowired
private UserDataMapper userDataMapper;
/**
* {@inheritDoc}
*/
@Override
protected IDataSet getIDataSet(){
IDataSet iDataset = null;
try{
iDataset = new CsvDataSet(
new File(System.getProperty("user.dir")
+ "\\src\\test\\resources\\com\\example\\demo\\csv"));
}catch (Exception e){
System.err.println(e);
}
return iDataset;
}
/**
* ユーザーデータのテーブルデータを取得し、結果を確認
*/
@Test
public void userDataMapperFindByIdTest(){
UserData userData = userDataMapper.findById(Long.valueOf("1"));
System.out.println("取得した値 : " + userData.toString());
assertEquals(super.getExpectedUserData().toString(), userData.toString());
}
}
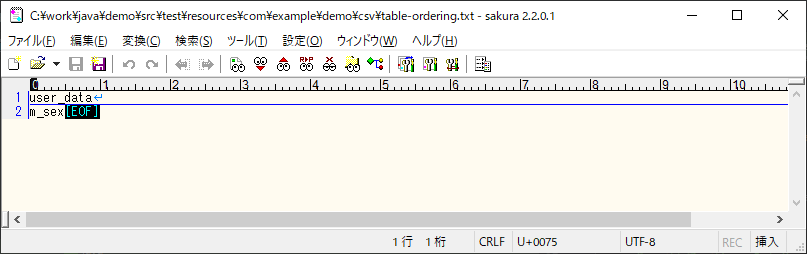
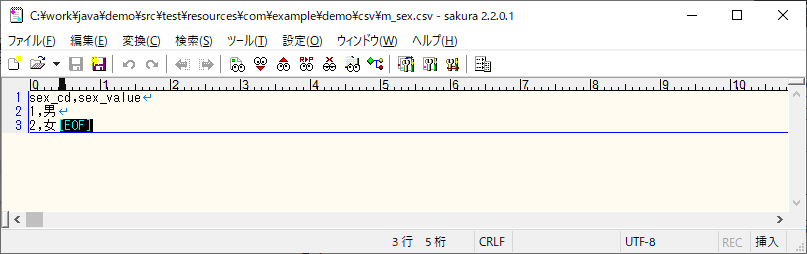
また、このときに取込対象CSVファイルを指定する「table-ordering.txt」と、取込対象CSVファイルは以下の通りで、「table-ordering.txt」には、取込対象となるテーブル名を指定する必要がある。
<table-ordering.txt>
<user_data.csv>

<m_sex.csv>
その他のソースコード内容は、以下のサイトを参照のこと。
https://github.com/purin-it/java/tree/master/junit-dbunit-select/demo
作成したサンプルプログラムの実行結果
XMLファイルのデータを取り込んでデータ検索メソッドの実行を確認するクラス(UserDataTestXml.java)の実行結果は以下の通り。
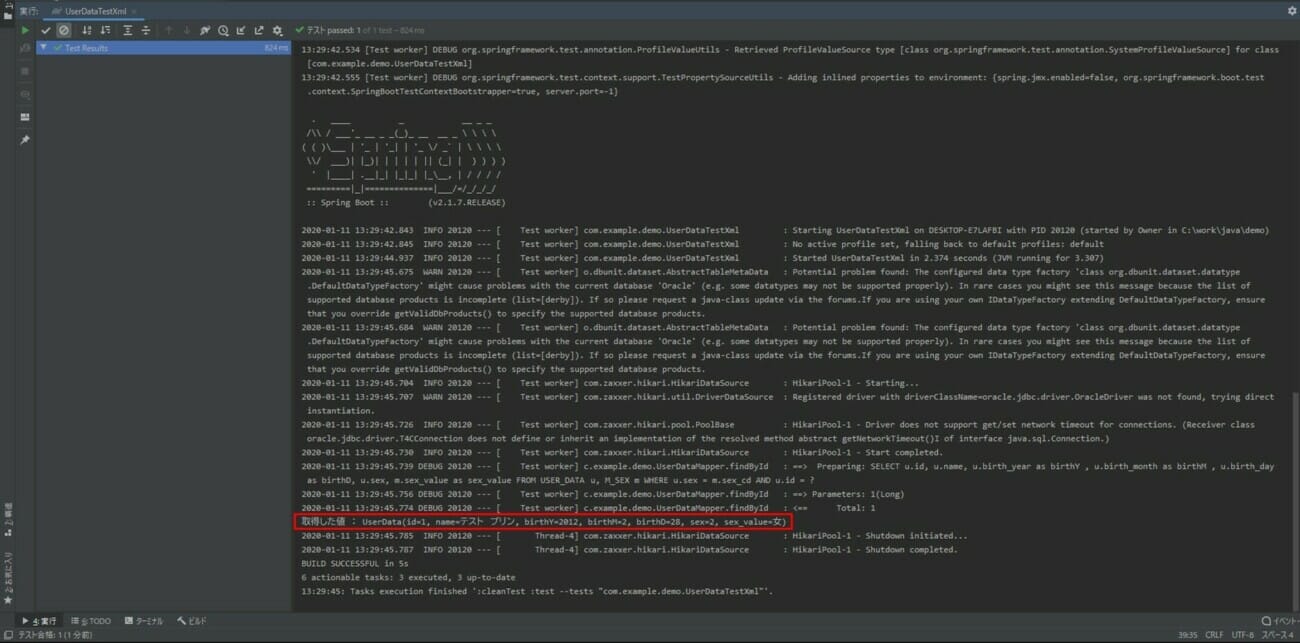
上記赤枠で、userDataMapper.findByIdメソッドにより取得した値が確認できる。
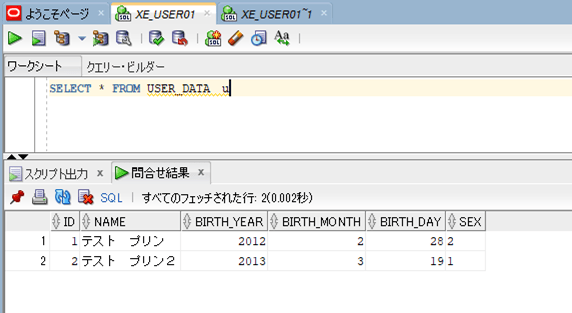
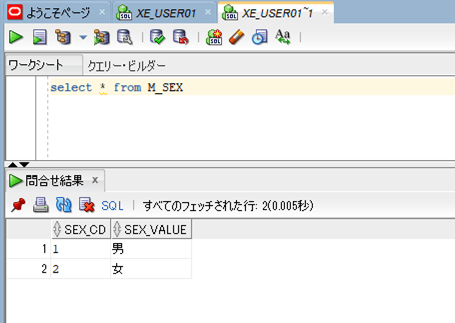
また、実行後のDBのテーブルデータは以下の通りで、XMLのデータがテーブルに格納されていることが確認できる。
さらに、CSVファイルのデータを取り込んでデータ検索メソッドの実行を確認するクラス(UserDataTestCsv.java)の実行結果は以下の通り。
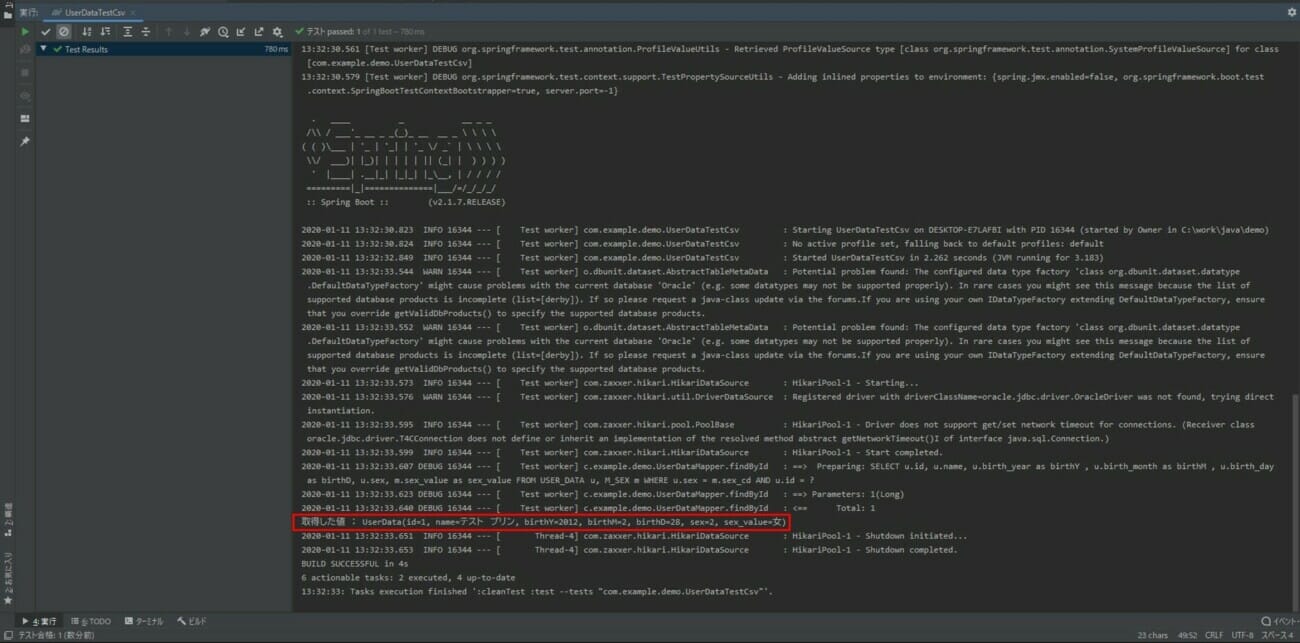
上記赤枠で、userDataMapper.findByIdメソッドにより取得した値が確認でき、取得値がXMLの場合と同じであることが確認できる。
また、実行後のDBのテーブルデータは以下の通りで、CSVのデータがテーブルに格納されていることが確認できる。
要点まとめ
- DBUnitというツールを利用すると、テストメソッドを実行する前に、データを追加したり削除したりすることができる。
- DBUnitでは、追加対象のデータタイプに、XMLまたはCSVも指定できる。
- DBUnitでは、データベース接続用にはIDatabaseConnectionクラスを、データセットにはIDataSetクラスを利用すればよい。
なお、今回取り上げていないが、追加対象のデータタイプにエクセルファイルも指定できる。詳細は下記サイト等を参照のこと。
http://teqspaces.com/DBUnit/1





