Azure Function上でSpring BatchのChunkモデルで動作するプログラムにListenerで処理を追加してみた
Spring BatchのChunkモデルは、以下のサイトに記載の通り、ファイルの読み込み/データの加工/DBへの書き込みといった処理の流れを定型化している。
https://spring.pleiades.io/spring-batch/docs/current/reference/html/step.html#chunkOrientedProcessing
また、Spring BatchのChunkモデルには、ファイルの読み込み/データの加工/DBへの書き込みの各処理の前後に、別の処理を追加するListenerクラスも用意されている。
今回は、DBへの書き込み前後・Step実行前後のそれぞれに、処理結果を出力する処理を追加してみたので、そのサンプルプログラムを共有する。
前提条件
下記記事のサンプルプログラムを作成済であること。

サンプルプログラムの作成
作成したサンプルプログラムの構成は以下の通り。
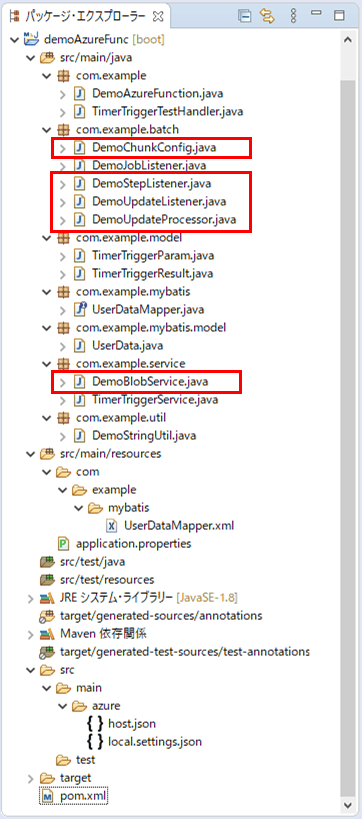
なお、上記の赤枠は、今回追加・変更したプログラムである。
チェック処理を行うクラスの内容は以下の通りで、ログ出力に加え、BlobStorage「result.txt」に、チェックエラーが発生した旨を記載している。
package com.example.batch;
import org.apache.commons.lang3.StringUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import com.example.mybatis.model.UserData;
import com.example.service.DemoBlobService;
import com.example.util.DemoStringUtil;
@Component
public class DemoUpdateProcessor implements ItemProcessor<UserData, UserData> {
/* Spring Bootでログ出力するためのLogbackのクラスを生成 */
private static final Logger LOGGER
= LoggerFactory.getLogger(DemoUpdateProcessor.class);
/** BLOBへアクセスするサービス */
@Autowired
private DemoBlobService demoBlobService;
/** 結果を出力するBLOB名 */
private static final String BLOB_NAME = "result.txt";
/**
* 読み込んだデータの加工を行う.
* ここでは、読み込んだデータのチェックを行い、エラーがあればNULLを、
* エラーがなければ引数の値をそのまま返す.
*/
@Override
public UserData process(UserData item) throws Exception {
String itemId = StringUtils.isEmpty(item.getId()) ? "(未設定)" : item.getId();
LOGGER.info("読み込んだデータの加工を行います。ID=" + itemId);
// 1列目が空またはNULLの場合はエラー
if (StringUtils.isEmpty(itemId)) {
printLog(itemId, "1列目が空またはNULLです。");
return null;
}
// 1列目が数値以外の場合はエラー
if (!StringUtils.isNumeric(itemId)) {
printLog(itemId, "1列目が数値以外です。");
return null;
}
// 1列目の桁数が不正な場合はエラー
if (itemId.length() > 6) {
printLog(itemId, "1列目の桁数が不正です。");
return null;
}
// 2列目が空またはNULLの場合はエラー
if (StringUtils.isEmpty(item.getName())) {
printLog(itemId, "2列目が空またはNULLです。");
return null;
}
// 2列目の桁数が不正な場合はエラー
if (item.getName().length() > 40) {
printLog(itemId, "2列目の桁数が不正です。");
return null;
}
// 3列目が空またはNULLの場合はエラー
if (StringUtils.isEmpty(item.getBirth_year())) {
printLog(itemId, "3列目が空またはNULLです。");
return null;
}
// 3列目が数値以外の場合はエラー
if (!StringUtils.isNumeric(item.getBirth_year())) {
printLog(itemId, "3列目が数値以外です。");
return null;
}
// 3列目の桁数が不正な場合はエラー
if (item.getBirth_year().length() > 4) {
printLog(itemId, "3列目の桁数が不正です。");
return null;
}
// 4列目が空またはNULLの場合はエラー
if (StringUtils.isEmpty(item.getBirth_month())) {
printLog(itemId, "4列目が空またはNULLです。");
return null;
}
// 4列目が数値以外の場合はエラー
if (!StringUtils.isNumeric(item.getBirth_month())) {
printLog(itemId, "4列目が数値以外です。");
return null;
}
// 4列目の桁数が不正な場合はエラー
if (item.getBirth_month().length() > 4) {
printLog(itemId, "4列目の桁数が不正です。");
return null;
}
// 5列目が空またはNULLの場合はエラー
if (StringUtils.isEmpty(item.getBirth_day())) {
printLog(itemId, "5列目が空またはNULLです。");
return null;
}
// 5列目が数値以外の場合はエラー
if (!StringUtils.isNumeric(item.getBirth_day())) {
printLog(itemId, "5列目が数値以外です。");
return null;
}
// 5列目の桁数が不正な場合はエラー
if (item.getBirth_day().length() > 2) {
printLog(itemId, "5列目の桁数が不正です。");
return null;
}
// 3列目・4列目・5列目から生成される日付が不正であればエラー
String birthDay = item.getBirth_year()
+ DemoStringUtil.addZero(item.getBirth_month())
+ DemoStringUtil.addZero(item.getBirth_day());
if (!DemoStringUtil.isCorrectDate(birthDay, "uuuuMMdd")) {
printLog(itemId, "3~5列目の日付が不正です。");
return null;
}
// 6列目が1,2以外の場合はエラー
if (!("1".equals(item.getSex())) && !("2".equals(item.getSex()))) {
printLog(itemId, "6列目の性別が不正です。");
return null;
}
// 7列目の桁数が不正な場合はエラー
if (!StringUtils.isEmpty(item.getMemo()) && item.getMemo().length() > 1024) {
printLog(itemId, "7列目の桁数が不正です。");
return null;
}
return item;
}
/**
* エラーメッセージを出力する
* @param itemId ID
* @param message メッセージ
*/
private void printLog(String itemId, String message) {
// ログにエラーメッセージを書き込む
LOGGER.info(message + " 該当のID=" + itemId);
// BlobStorageにチェックエラーだった旨のメッセージを書き込む
demoBlobService.writeAppendBlob(BLOB_NAME, "ID: " + itemId + ": チェックエラー");
}
}また、BlobStorageにアクセスするクラスの内容は以下の通りで、Blobへの追記・削除・URL取得を行っている。
package com.example.service;
import java.time.Duration;
import java.time.OffsetDateTime;
import javax.annotation.PostConstruct;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;
import com.azure.storage.blob.BlobServiceClient;
import com.azure.storage.blob.BlobServiceClientBuilder;
import com.azure.storage.common.sas.AccountSasPermission;
import com.azure.storage.common.sas.AccountSasResourceType;
import com.azure.storage.common.sas.AccountSasService;
import com.azure.storage.common.sas.AccountSasSignatureValues;
import com.microsoft.azure.storage.CloudStorageAccount;
import com.microsoft.azure.storage.blob.CloudBlobClient;
import com.microsoft.azure.storage.blob.CloudBlobContainer;
import com.microsoft.azure.storage.blob.BlobRequestOptions;
import com.microsoft.azure.storage.blob.CloudAppendBlob;
import io.netty.util.internal.StringUtil;
@Service
public class DemoBlobService {
/** Azure Storageのアカウント名 */
@Value("${azure.storage.accountName}")
private String storageAccountName;
/** Azure Storageへのアクセスキー */
@Value("${azure.storage.accessKey}")
private String storageAccessKey;
/** Azure StorageのBlobコンテナー名 */
@Value("${azure.storage.containerName}")
private String storageContainerName;
/** 改行コード */
private static final String LINE_SEPARATOR = "\r\n";
/** 文字コード */
private static final String CHARCTER_CODE = "UTF-8";
// Blobストレージへの接続文字列
private String storageConnectionString = null;
/**
* Blobストレージへの接続文字列の初期化処理
*/
@PostConstruct
public void init() {
// Blobストレージへの接続文字列を設定
storageConnectionString = "DefaultEndpointsProtocol=https;"
+ "AccountName=" + storageAccountName + ";"
+ "AccountKey=" + storageAccessKey + ";";
}
/**
* 引数で指定されたファイルに、引数で指定されたメッセージを追加する.
* @param fileName ファイル名
* @param message メッセージ
*/
public void writeAppendBlob(String fileName, String message) {
// 未指定の項目がある場合、何もしない
if(StringUtil.isNullOrEmpty(storageAccountName)
|| StringUtil.isNullOrEmpty(storageAccessKey)
|| StringUtil.isNullOrEmpty(storageContainerName)
|| StringUtil.isNullOrEmpty(fileName)
|| StringUtil.isNullOrEmpty(message)) {
return;
}
// ファイルアップロード処理
// Blob内のコンテナー内の指定したファイルに、指定したメッセージを追記モードで書き込む
try {
CloudAppendBlob cab = getContainer().getAppendBlobReference(fileName);
if (!cab.exists()) {
cab.createOrReplace();
}
BlobRequestOptions options = new BlobRequestOptions();
options.setAbsorbConditionalErrorsOnRetry(true);
cab.appendText(message + LINE_SEPARATOR, CHARCTER_CODE, null, options, null);
} catch (Exception ex) {
throw new RuntimeException(ex);
}
}
/**
* 引数で指定されたファイルが存在する場合、削除する.
* @param fileName ファイル名
*/
public void deleteAppendBlob(String fileName) {
// 未指定の項目がある場合、何もしない
if(StringUtil.isNullOrEmpty(storageAccountName)
|| StringUtil.isNullOrEmpty(storageAccessKey)
|| StringUtil.isNullOrEmpty(storageContainerName)
|| StringUtil.isNullOrEmpty(fileName)) {
return;
}
// Blob内のコンテナー内の指定したファイルが存在する場合、削除する
try {
CloudAppendBlob cab = getContainer().getAppendBlobReference(fileName);
cab.deleteIfExists();
} catch (Exception ex) {
throw new RuntimeException(ex);
}
}
/**
* 引数で指定されたファイルのURLを返却する.
* @param fileName
* @return
*/
public String getBlobUrl(String fileName) {
// 未指定の項目がある場合、nullを返す
if(StringUtil.isNullOrEmpty(storageAccountName)
|| StringUtil.isNullOrEmpty(storageAccessKey)
|| StringUtil.isNullOrEmpty(storageContainerName)
|| StringUtil.isNullOrEmpty(fileName)) {
return null;
}
// Blob内のコンテナー内の指定したファイルのURLを返却する
try {
// Blobサービスクライアントの生成
BlobServiceClient blobServiceClient = new BlobServiceClientBuilder()
.connectionString(storageConnectionString).buildClient();
// BlobサービスクライアントからSASを生成
String sas = this.getServiceSasUriForBlob(blobServiceClient);
// Blob内のコンテナー内の指定したファイルのURLを返却
String url = blobServiceClient.getAccountUrl() + "/"
+ storageContainerName + "/" + fileName
+ "?" + sas;
return url;
} catch(Exception ex) {
throw new RuntimeException(ex);
}
}
/**
* Blobストレージのコンテナを取得する.
* @return Blobストレージのコンテナ
* @throws Exception
*/
private CloudBlobContainer getContainer() throws Exception {
// ストレージアカウントオブジェクトを取得
CloudStorageAccount storageAccount
= CloudStorageAccount.parse(storageConnectionString);
// Blobクライアントオブジェクトを取得
CloudBlobClient blobClient = storageAccount.createCloudBlobClient();
// Blob内のコンテナーを取得
CloudBlobContainer container
= blobClient.getContainerReference(storageContainerName);
return container;
}
/**
* 引数で指定したBlobのSASトークンを生成し返す.
* @param client Blobサービスクライアントオブジェクト
* @return SASトークン
*/
private String getServiceSasUriForBlob(BlobServiceClient client) {
// SASトークンのアクセス権を読み取り可能に設定
AccountSasPermission permissions
= new AccountSasPermission().setReadPermission(true);
// SASトークンがBlobコンテナやオブジェクトにアクセスできるように設定
AccountSasResourceType resourceTypes
= new AccountSasResourceType().setContainer(true).setObject(true);
// SASトークンがBlobにアクセスできるように設定
AccountSasService services = new AccountSasService().setBlobAccess(true);
// SASトークンの有効期限を5分に設定
OffsetDateTime expiryTime = OffsetDateTime.now().plus(Duration.ofMinutes(5));
// SASトークンを作成
AccountSasSignatureValues sasValues
= new AccountSasSignatureValues(expiryTime, permissions
, services, resourceTypes);
return client.generateAccountSas(sasValues);
}
}
さらに、Chunkモデルの出力(DB追加/更新処理)前後の処理を記載したクラスの内容は以下の通りで、BlobStorage「result.txt」に、書き込み結果を記載している。
package com.example.batch;
import java.util.List;
import org.springframework.batch.core.ItemWriteListener;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import com.example.mybatis.model.UserData;
import com.example.service.DemoBlobService;
@Component
public class DemoUpdateListener implements ItemWriteListener<UserData>{
/** BLOBへアクセスするサービス */
@Autowired
private DemoBlobService demoBlobService;
/** 結果を出力するBLOB名 */
private static final String BLOB_NAME = "result.txt";
/**
* データ書き込み前の処理を定義する.
*/
@Override
public void beforeWrite(List<? extends UserData> items) {
// 何もしない
}
/**
* データ書き込み後の処理を定義する.
*/
@Override
public void afterWrite(List<? extends UserData> items) {
// BlobStorageに正常終了だった旨のメッセージを書き込む
for(UserData u : items) {
demoBlobService.writeAppendBlob(BLOB_NAME, "ID: " + u.getId() + ": 書き込み正常");
}
}
/**
* データ書き込みエラー後の処理を定義する.
*/
@Override
public void onWriteError(Exception exception, List<? extends UserData> items) {
// BlobStorageに異常終了だった旨のメッセージを書き込む
for(UserData u : items) {
demoBlobService.writeAppendBlob(BLOB_NAME, "ID: " + u.getId() + ": 書き込み異常");
}
}
}また、Spring Batchのジョブ内で指定する処理単位(ステップ)実行前後の処理を記載したクラスの内容は以下の通りで、開始前にBlobStorage「result.txt」を削除し、終了後に読み込み件数・書き込み件数をログ出力している。
package com.example.batch;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.core.ExitStatus;
import org.springframework.batch.core.StepExecution;
import org.springframework.batch.core.StepExecutionListener;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import com.example.service.DemoBlobService;
@Component
public class DemoStepListener implements StepExecutionListener {
/* Spring Bootでログ出力するためのLogbackのクラスを生成 */
private static final Logger LOGGER
= LoggerFactory.getLogger(DemoStepListener.class);
/** BLOBへアクセスするサービス */
@Autowired
private DemoBlobService demoBlobService;
/** 結果を出力するBLOB名 */
private static final String BLOB_NAME = "result.txt";
/**
* Spring Batchのジョブ内で指定する処理単位(ステップ)実行前の処理を定義する.
*/
@Override
public void beforeStep(StepExecution stepExecution) {
// 結果を出力するBLOBが残っていれば削除
demoBlobService.deleteAppendBlob(BLOB_NAME);
}
/**
* Spring Batchのジョブ内で指定する処理単位(ステップ)実行後の処理を定義する.
*/
@Override
public ExitStatus afterStep(StepExecution stepExecution) {
// 読み込み件数・書き込み件数を取得しログ出力
int readCnt = stepExecution.getReadCount();
int writeCnt = stepExecution.getWriteCount();
LOGGER.info("読み込み件数:" + readCnt + ", 書き込み件数:" + writeCnt);
return ExitStatus.COMPLETED;
}
}さらに、Spring Batchの定義クラスは以下の通りで、DemoUpdateListener・DemoStepListenerの呼出処理を追加している。
package com.example.batch;
import java.net.MalformedURLException;
import javax.sql.DataSource;
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.batch.MyBatisBatchItemWriter;
import org.mybatis.spring.batch.builder.MyBatisBatchItemWriterBuilder;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.batch.item.ItemReader;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.file.FlatFileItemReader;
import org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper;
import org.springframework.batch.item.file.mapping.DefaultLineMapper;
import org.springframework.batch.item.file.transform.DelimitedLineTokenizer;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.UrlResource;
import com.example.mybatis.model.UserData;
import com.example.service.DemoBlobService;
import lombok.RequiredArgsConstructor;
@Configuration
@EnableBatchProcessing
@RequiredArgsConstructor
public class DemoChunkConfig {
/** ジョブ生成ファクトリ */
public final JobBuilderFactory jobBuilderFactory;
/** ステップ生成ファクトリ */
public final StepBuilderFactory stepBuilderFactory;
/** SQLセッションファクトリ */
public final SqlSessionFactory sqlSessionFactory;
/** データ加工処理 */
private final DemoUpdateProcessor demoUpdateProcessor;
/** データ書き込み前後処理 */
private final DemoUpdateListener demoUpdateListener;
/** ステップの前後処理 */
private final DemoStepListener demoStepListener;
/** BLOBへアクセスするサービス */
@Autowired
private DemoBlobService demoBlobService;
/**
* BlobStorageからファイルを読み込む.
* @return 読み込みオブジェクト
*/
@Bean
public FlatFileItemReader<UserData> reader() {
FlatFileItemReader<UserData> reader = new FlatFileItemReader<UserData>();
try {
// BlobStorageからファイル(user_data.csv)を読み込む際のURLをreaderに設定
String url = demoBlobService.getBlobUrl("user_data.csv");
reader.setResource(new UrlResource(url));
} catch (MalformedURLException ex) {
throw new RuntimeException(ex);
}
// ファイルを読み込む際の文字コード
reader.setEncoding("UTF-8");
// 1行目を読み飛ばす
reader.setLinesToSkip(1);
// ファイルから読み込んだデータをUserDataオブジェクトに格納
reader.setLineMapper(new DefaultLineMapper<UserData>() {
{
setLineTokenizer(new DelimitedLineTokenizer() {
{
setNames(new String[] { "id", "name", "birth_year"
, "birth_month", "birth_day", "sex", "memo" });
}
});
setFieldSetMapper(new BeanWrapperFieldSetMapper<UserData>() {
{
setTargetType(UserData.class);
}
});
}
});
return reader;
}
/**
* 読み込んだファイルのデータを、DBに書き込む.
* @param dataSource データソース
* @return 書き込みオブジェクト
*/
@Bean
public MyBatisBatchItemWriter<UserData> writer(DataSource dataSource) {
return new MyBatisBatchItemWriterBuilder<UserData>()
.sqlSessionFactory(sqlSessionFactory)
.statementId("com.example.mybatis.UserDataMapper.upsert")
.build();
}
/**
* Spring Batchのジョブ内で指定する処理単位(ステップ)を定義する.
* @param reader 読み込みオブジェクト
* @param writer 書き込みオブジェクト
* @return Spring Batchのジョブ内で指定する処理単位
*/
@Bean
public Step step(ItemReader<UserData> reader, ItemWriter<UserData> writer) {
// 生成するステップ内で読み込み/加工/書き込み/書き込み後/ステップ実行前後の処理の一連の流れを指定する
// その際のチャンクサイズ(=何件読み込む毎にコミットするか)を3に指定している
return stepBuilderFactory.get("step")
.<UserData, UserData>chunk(3)
.reader(reader)
.processor(demoUpdateProcessor)
.writer(writer)
.listener(demoUpdateListener)
.listener(demoStepListener)
.build();
}
/**
* Spring Batchのジョブを定義する.
* @param jobListener 実行前後の処理(リスナ)
* @param step 実行するステップ
* @return Spring Batchのジョブ
*/
@Bean
public Job updateUserData(DemoJobListener jobListener, Step step) {
// 生成するジョブ内で、実行前後の処理(リスナ)と処理単位(ステップ)を指定する
return jobBuilderFactory
.get("updateUserData")
.incrementer(new RunIdIncrementer())
.listener(jobListener)
.flow(step)
.end()
.build();
}
}その他のソースコード内容は、以下のサイトを参照のこと。
https://github.com/purin-it/azure/tree/master/azure-functions-spring-batch-chunk-listener/demoAzureFunc

サンプルプログラムの実行結果
サンプルプログラムの実行結果は、以下の通り。
1) 以下のサイトの「サンプルプログラムの実行結果(ローカル)」「サンプルプログラムの実行結果(Azure上)」に記載の手順で、サンプルプログラムをAzure Functionsにデプロイする。

2) 赤枠でエラーが発生する場合のCSVファイルをBlob Storageに配置し、作成したバッチ処理を実行する。
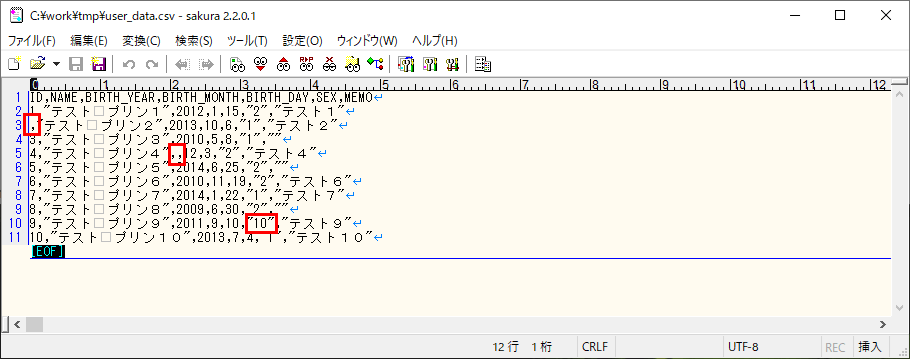
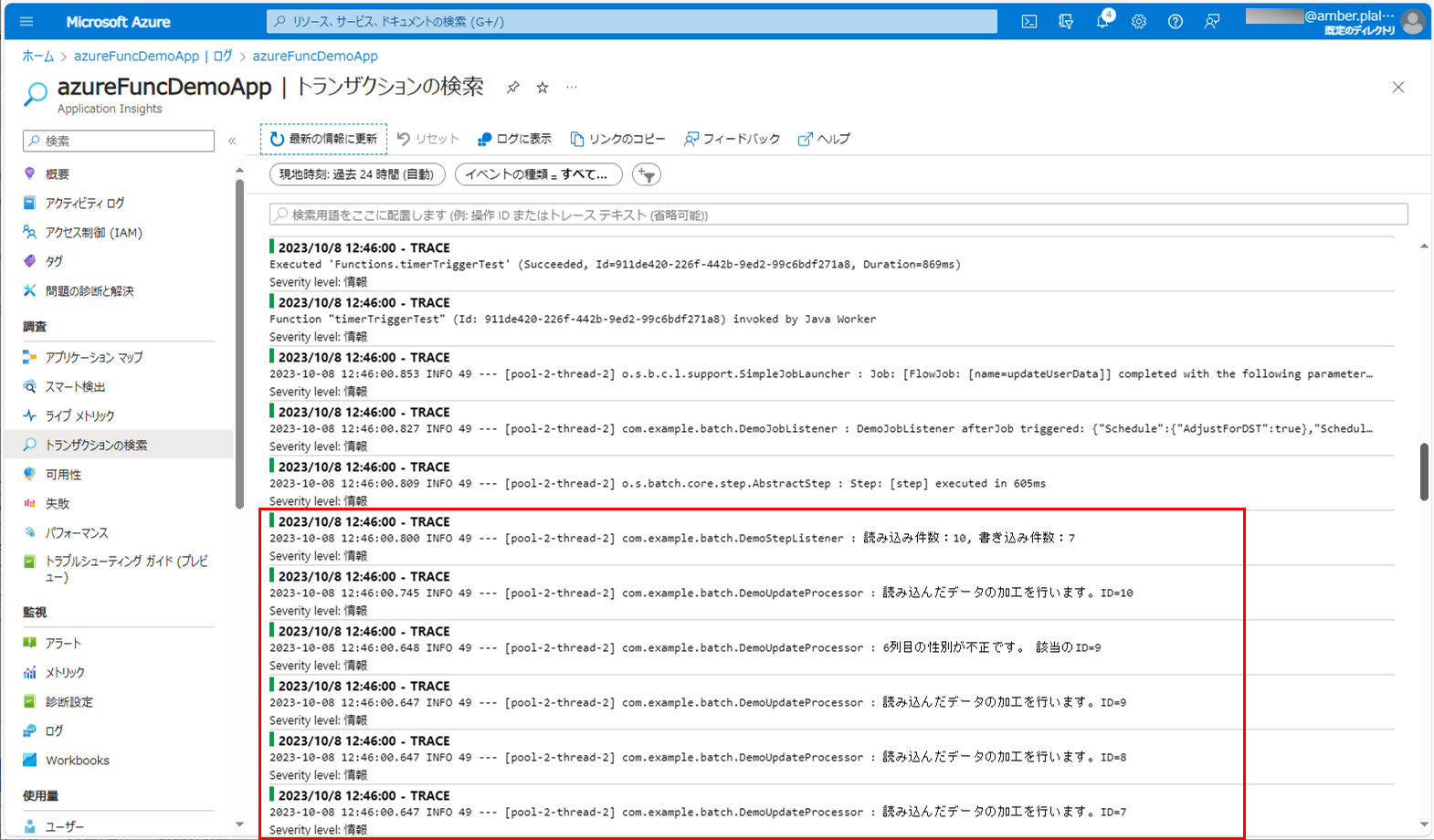
3) バッチ実行後のログ出力内容は以下の通りで、エラー内容や処理件数が出力されることが確認できる。
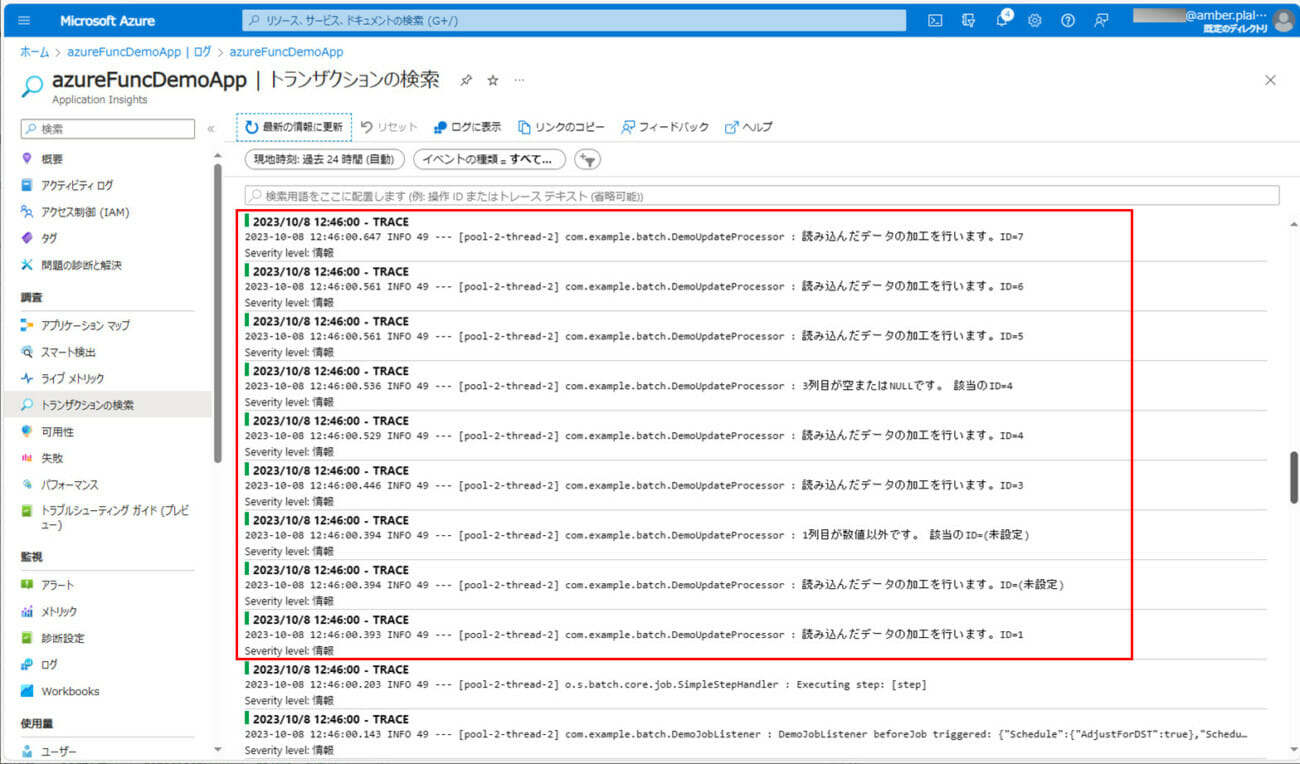
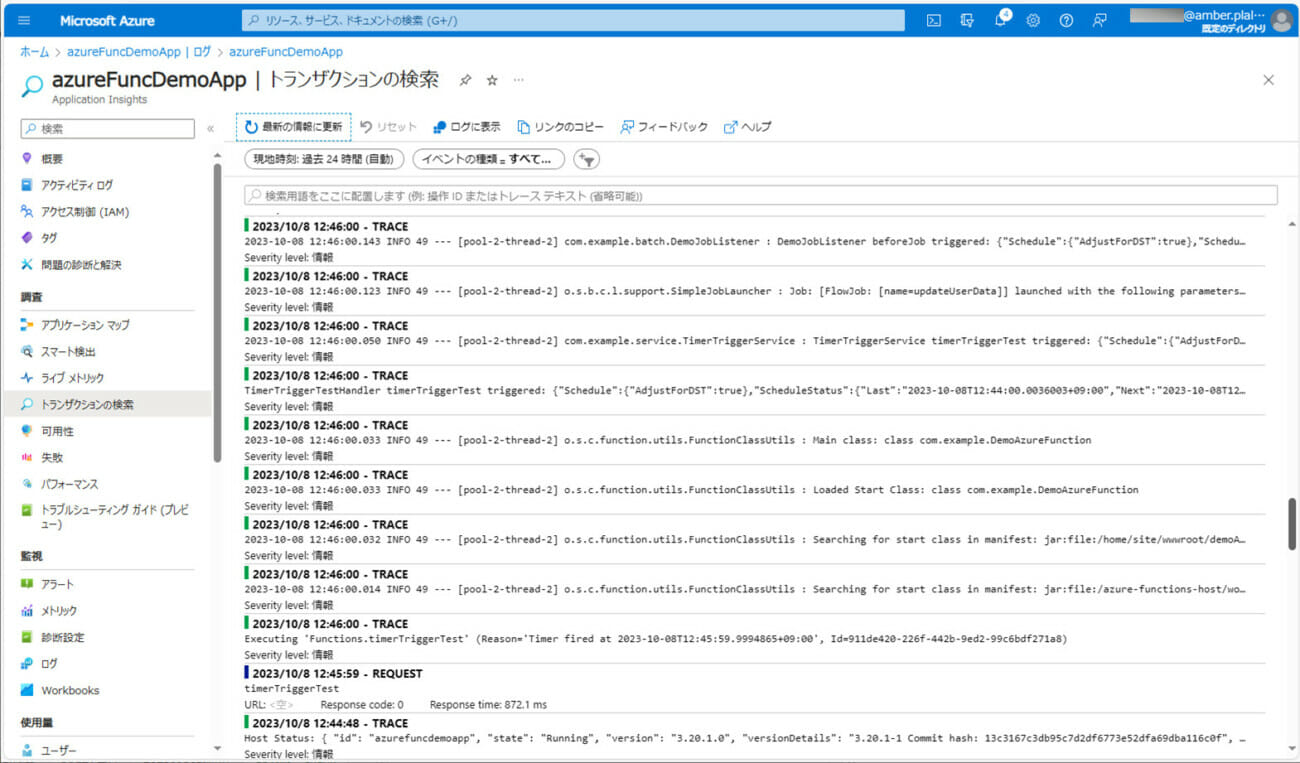
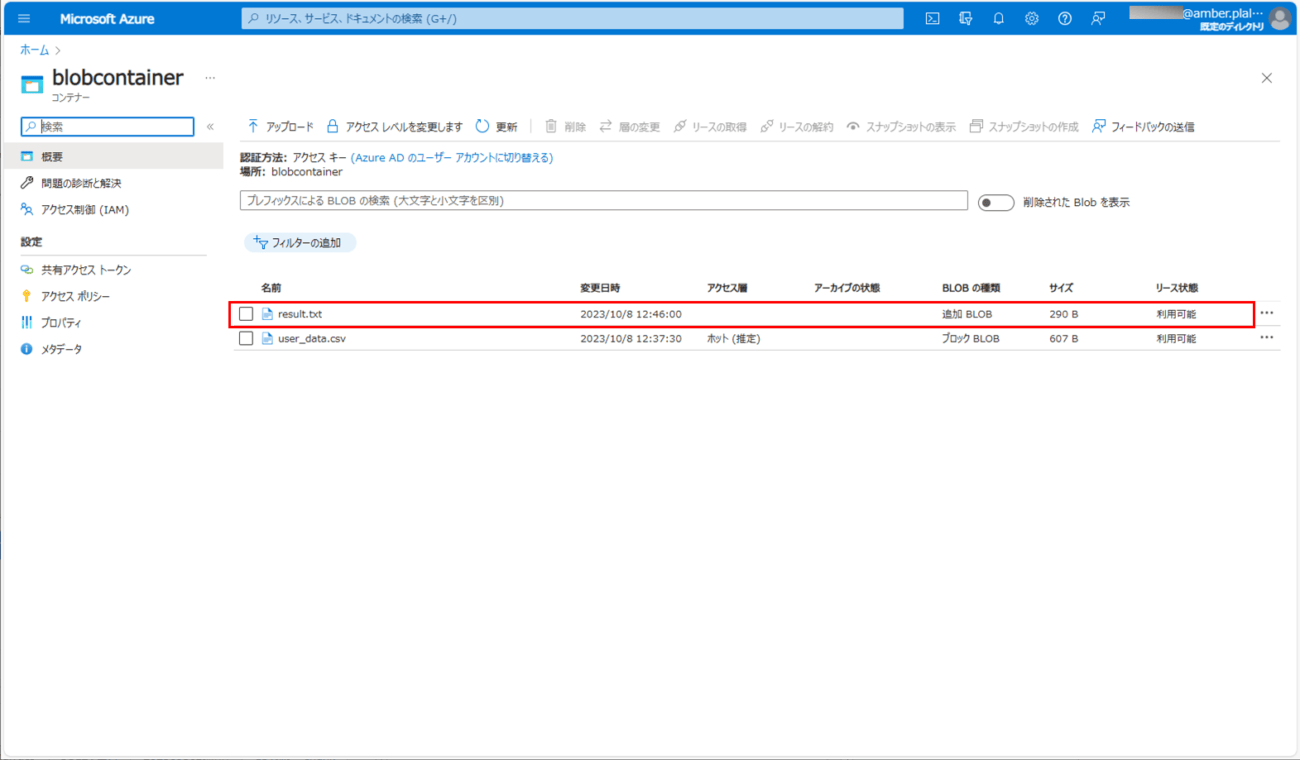
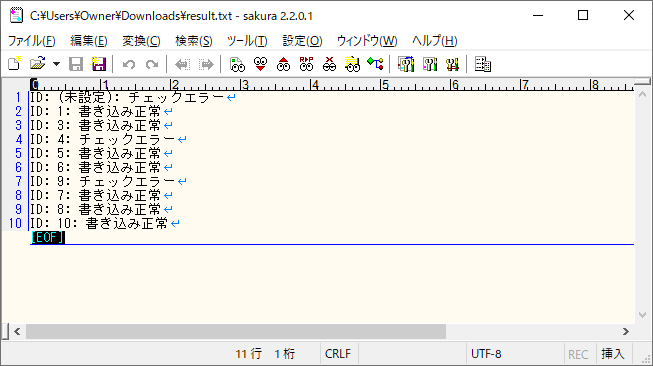
4) バッチ実行後にBlob Storageを確認すると、結果ファイル「result.txt」が作成され、各データの処理結果が出力されていることが確認できる。
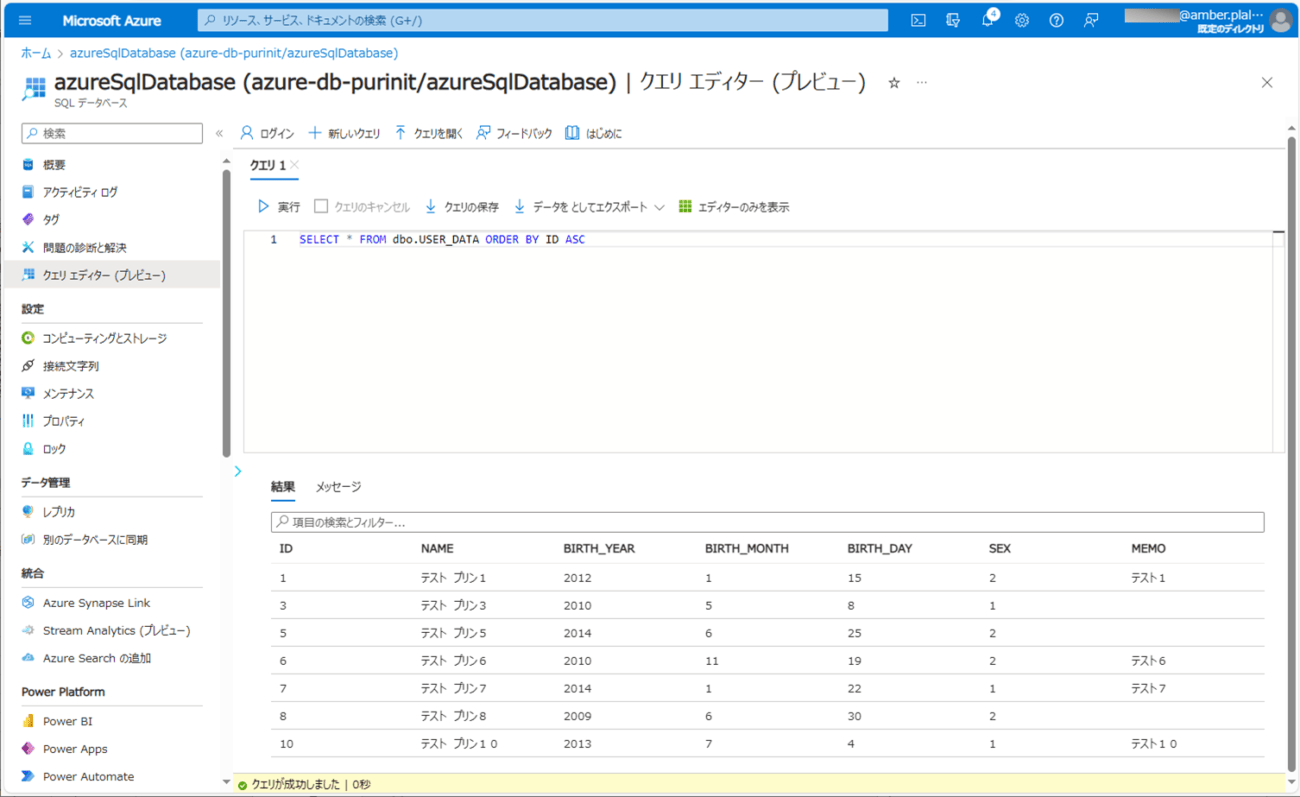
5) バッチ実行後にUSER_DATAテーブルを確認すると、正常に書き込みできたデータが全件登録されていることが確認できる。
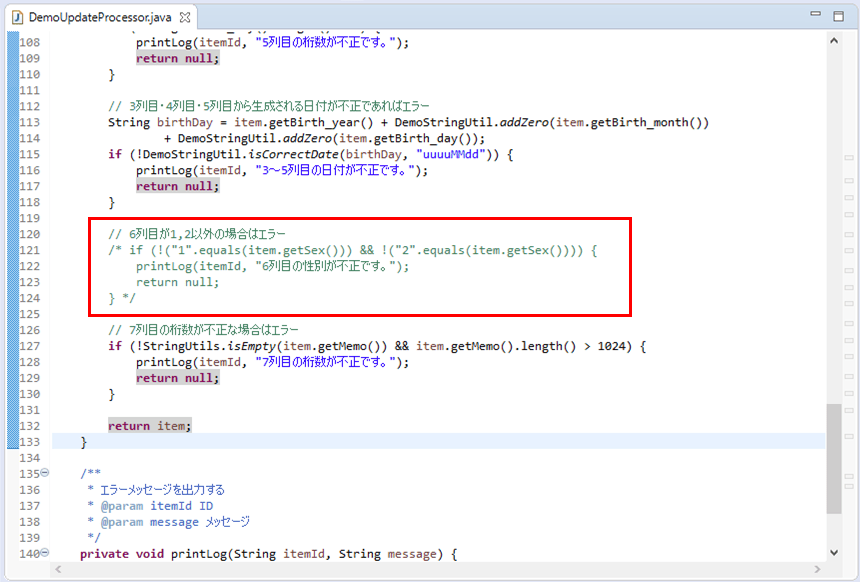
6) 以下のように、性別のチェック処理をコメントアウトし、バッチを再実行する。なお、読み込むCSVファイルの内容は、1)と同様とする。
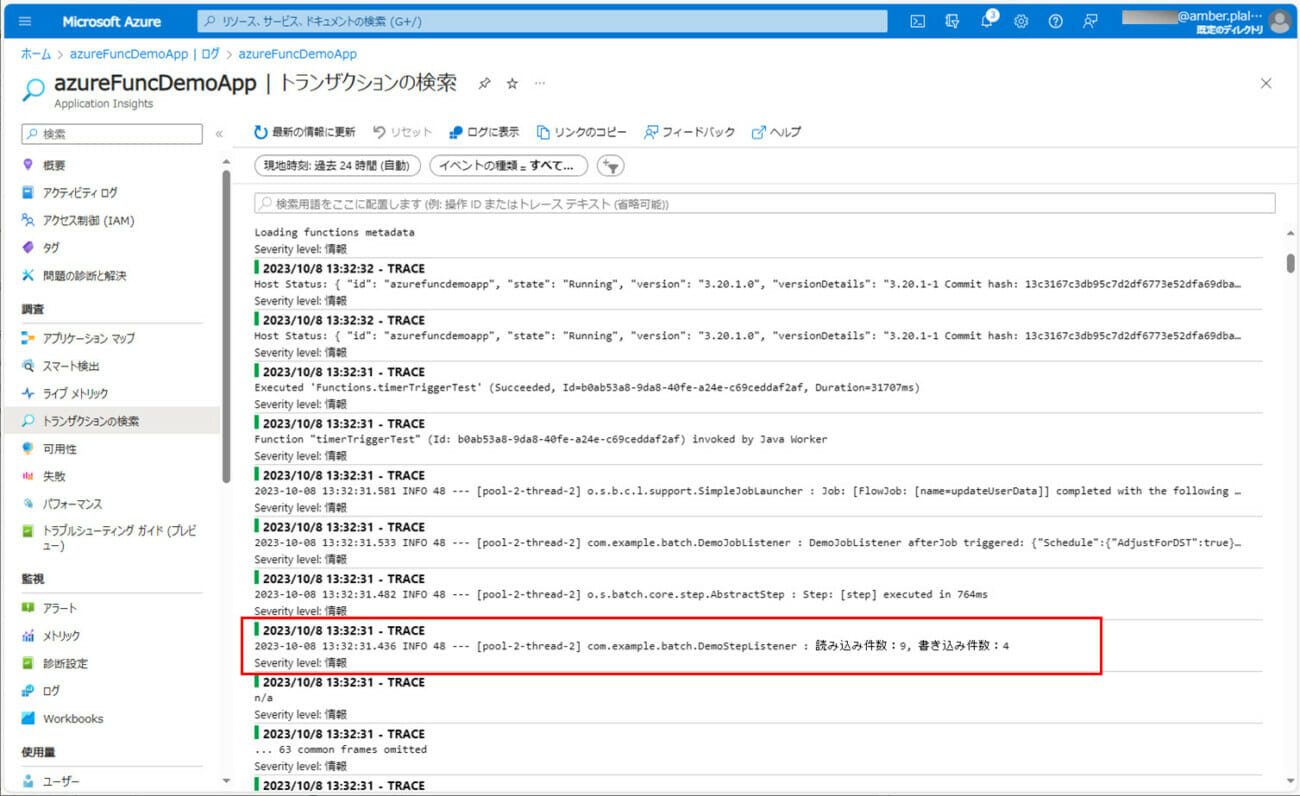
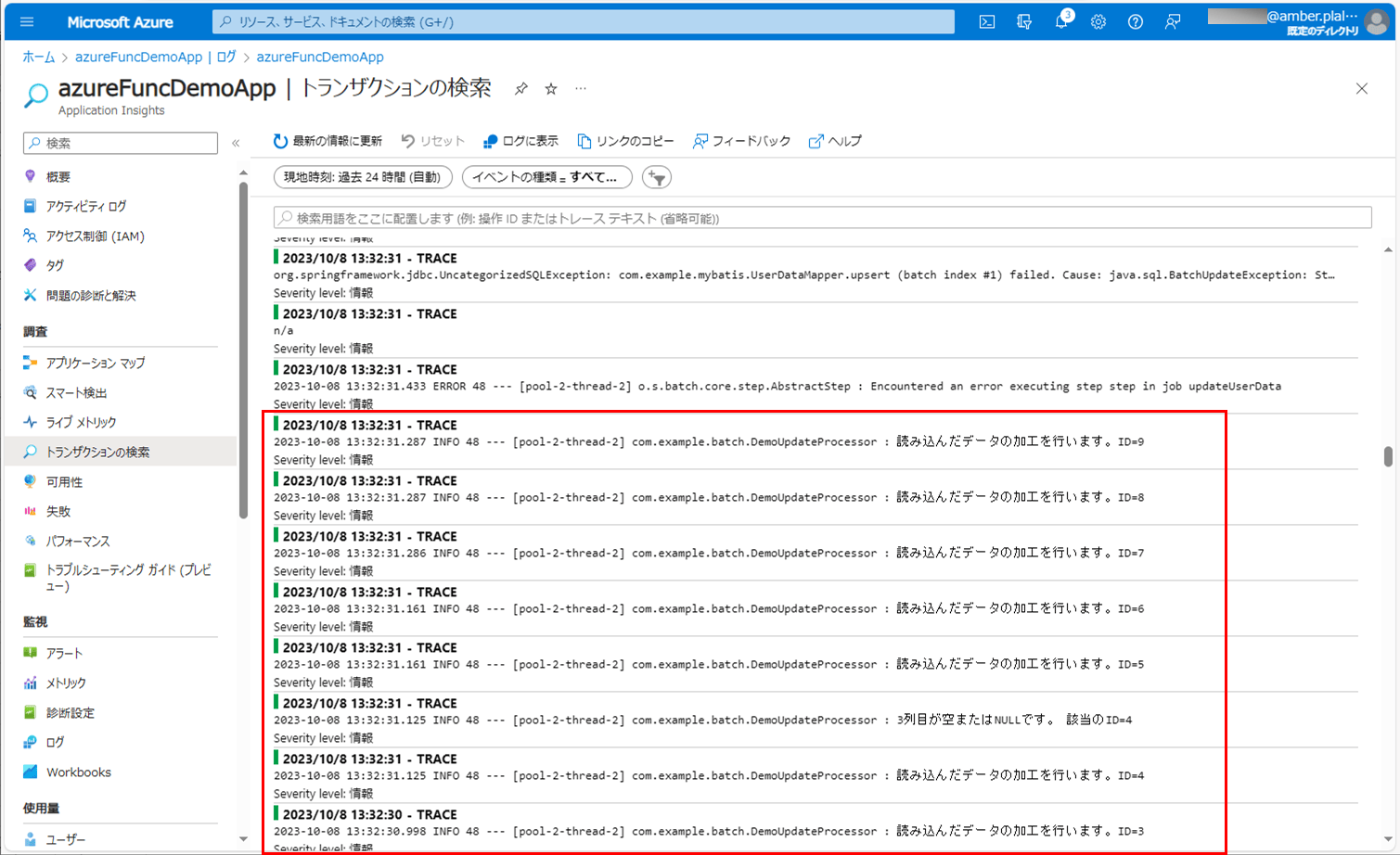
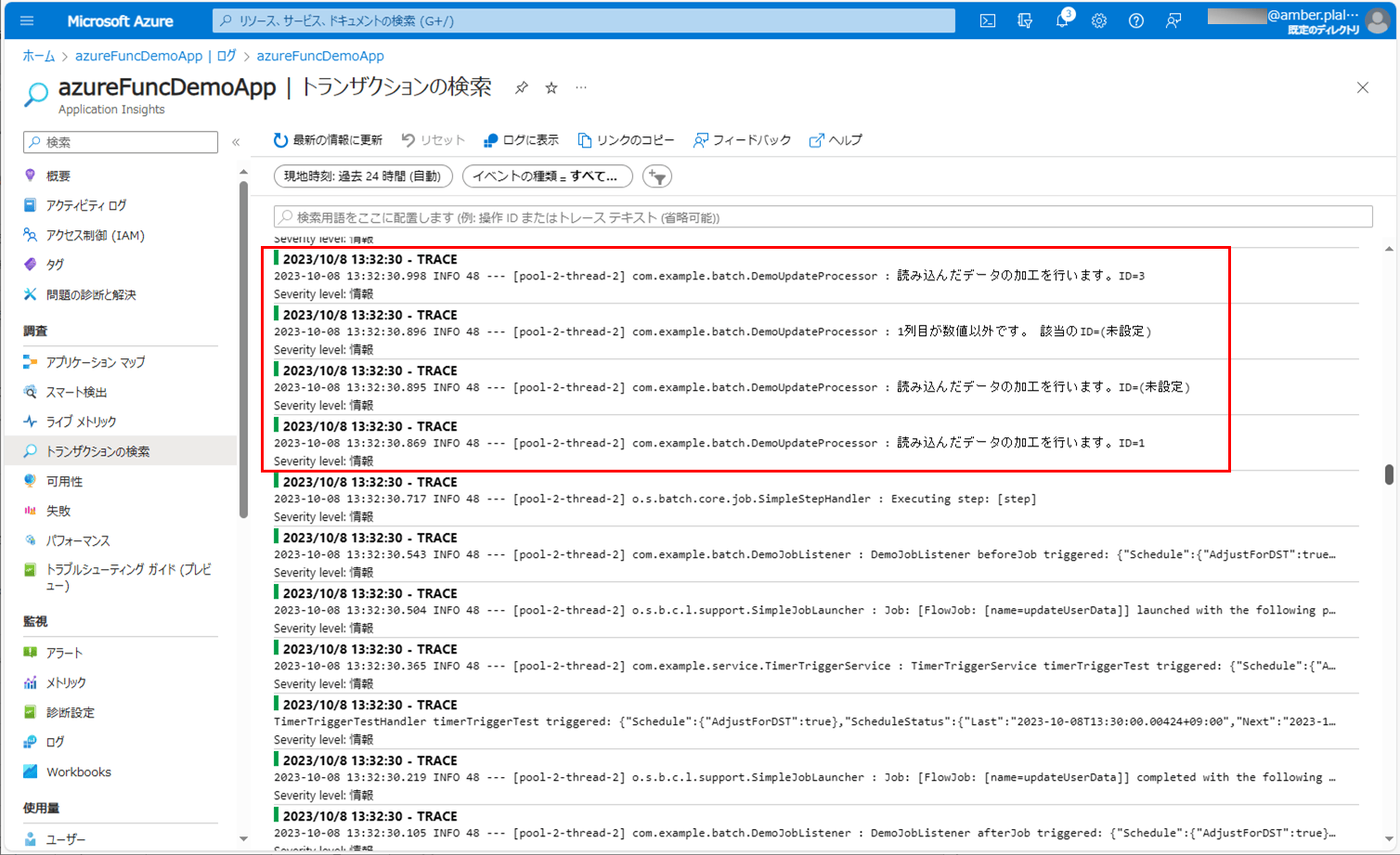
7) バッチ実行後のログ出力内容を確認すると、以下のようになっていることが確認できる。
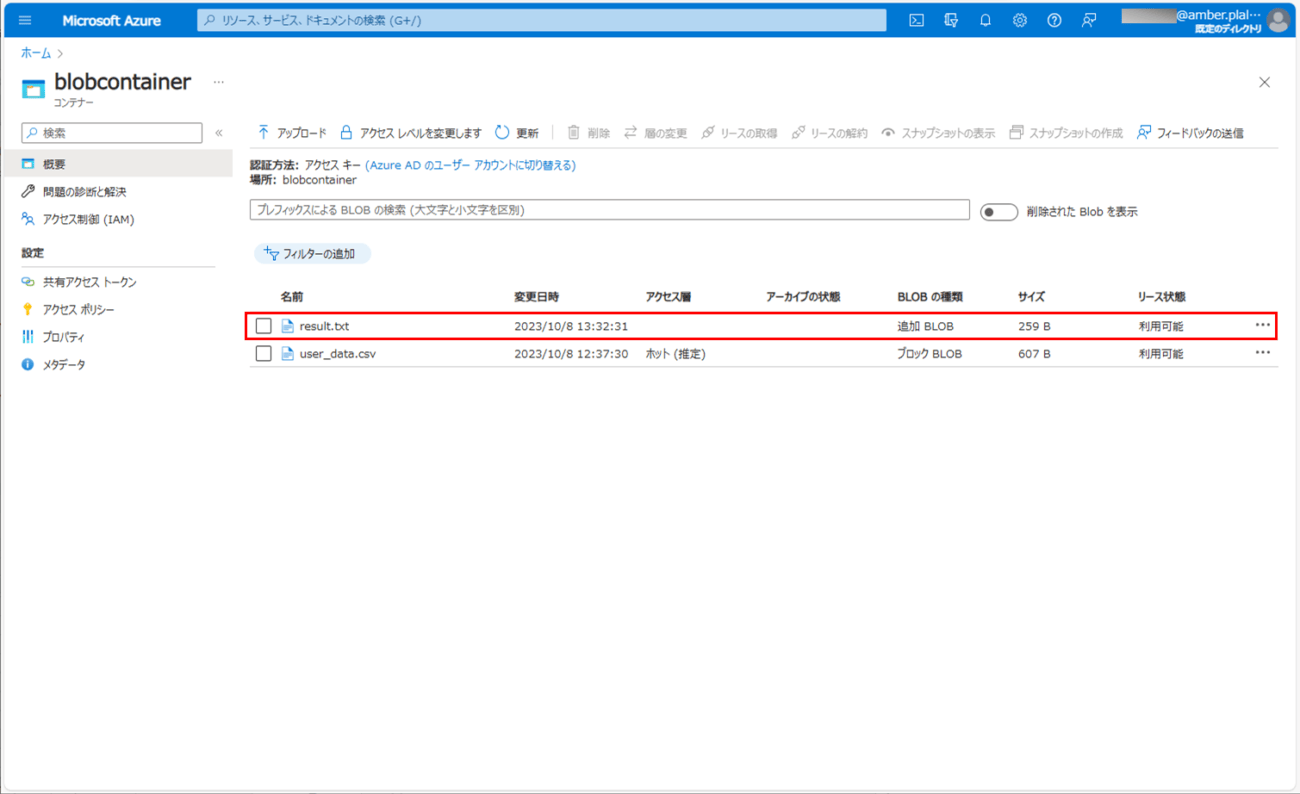
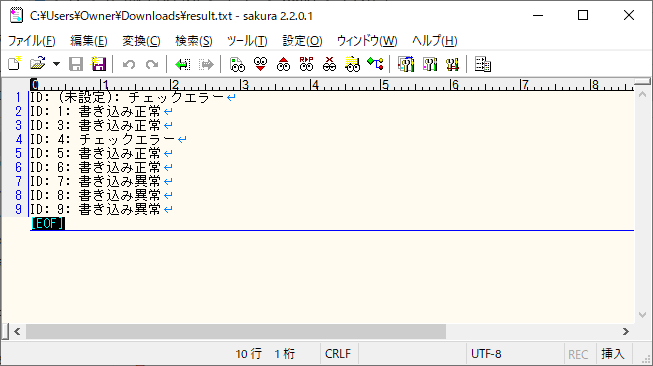
8) バッチ実行後の結果ファイル「result.txt」を確認すると、以下のようになっていることが確認できる。
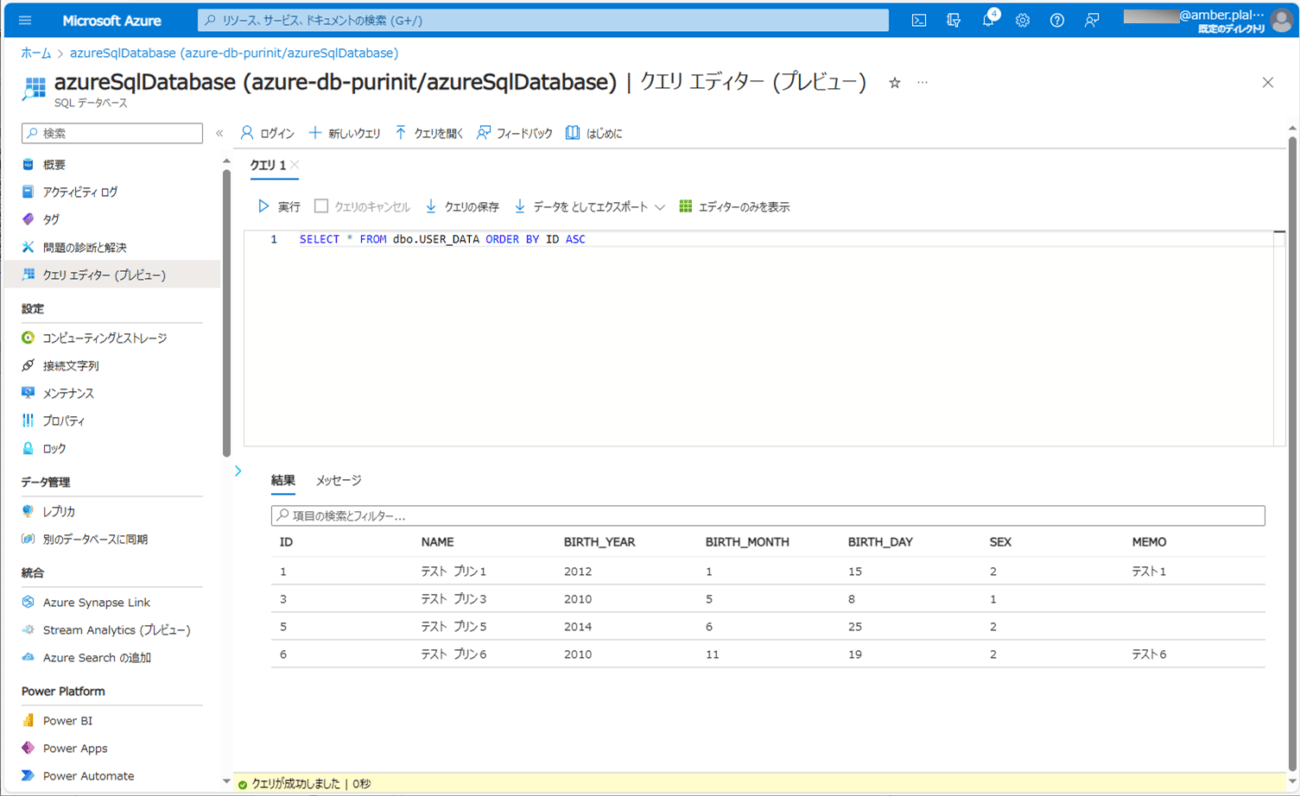
9) バッチ実行後のUSER_DATAテーブルの内容を確認すると、以下のようになっていることが確認できる。
要点まとめ
- Spring BatchのChunkモデルで、ファイルの読み込み/データの加工/DBへの書き込みの各処理の前後に、別の処理を追加するには、そのためのListenerクラスも利用すればよい。





