Azure Function上でCSVファイルのデータをDBに取り込むプログラムで楽観ロックを使ってみた
これまでこのブログで、Spring BatchのChunkモデルを用いて、Blob上のCSVファイルをDBのテーブルに書き込む処理を作成していたが、DBのテーブルに書き込む際に、楽観ロックを利用することもできる。
今回は、Blob上のCSVファイルをDBのテーブルに書き込む処理で、楽観ロックを利用してみたので、そのサンプルプログラムを共有する。
なお、楽観ロックを含む排他制御については、以下のサイトを参照のこと。
https://qiita.com/NagaokaKenichi/items/73040df85b7bd4e9ecfc
前提条件
下記記事のサンプルプログラムを作成済であること。

書き込み先テーブルのカラム追加
書き込み対象となるテーブルであるUSER_DATAテーブルに、楽観ロックを行うためのカラム「VERSION」を追加する。その手順は、以下の通り。
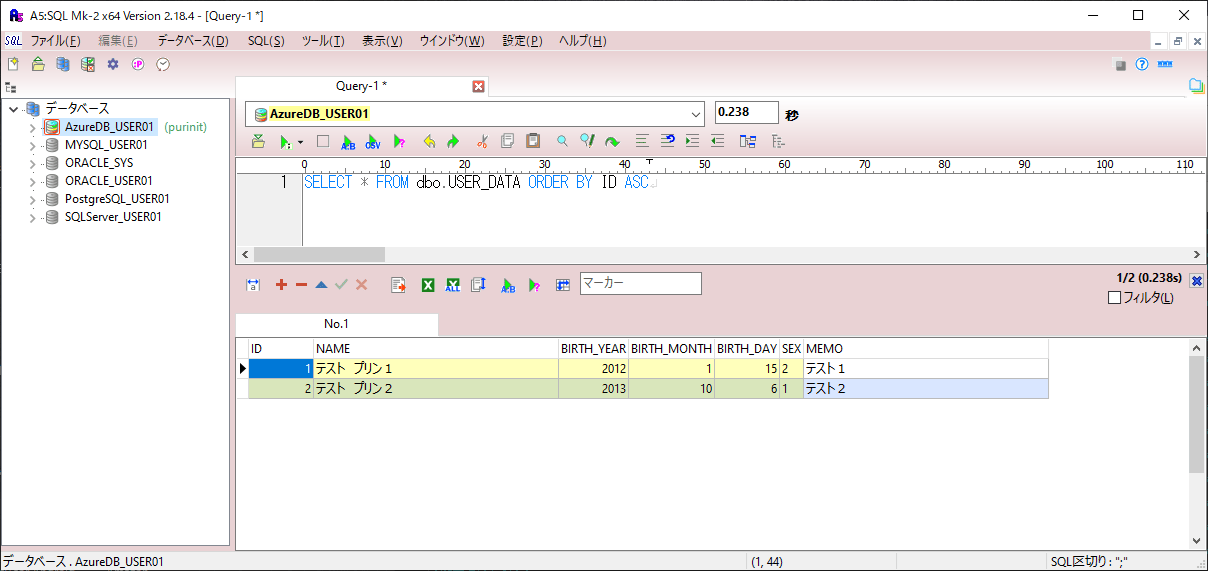
1) VERSIONを追加する前のUSER_DATAテーブルの構成は、以下の通り。
SELECT * FROM dbo.USER_DATA ORDER BY ID ASC
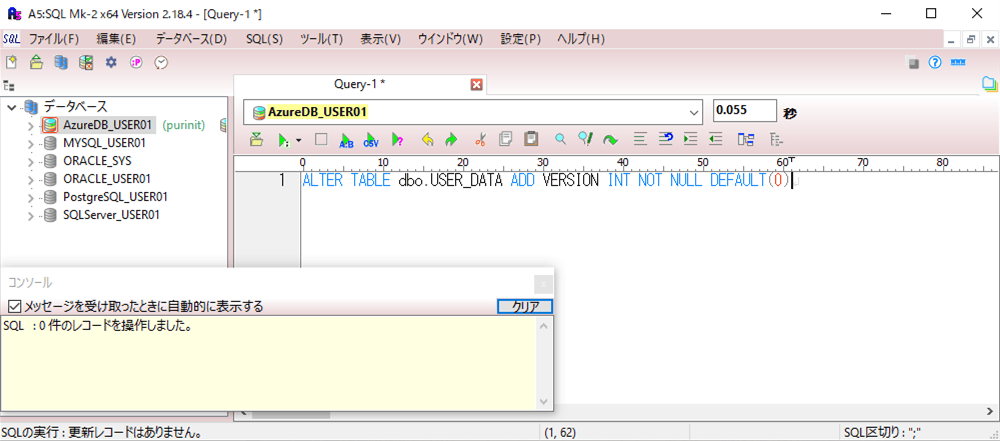
2) 以下のSQLを実行し、楽観ロックを行うためのカラム「VERSION」を追加する。
ALTER TABLE dbo.USER_DATA ADD VERSION INT NOT NULL DEFAULT(0)
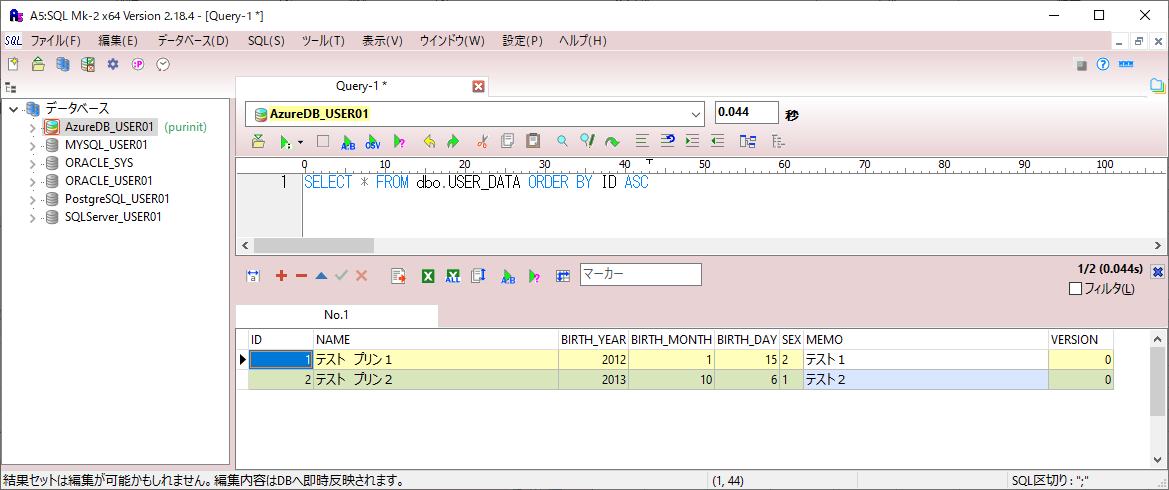
3) VERSIONを追加した後のUSER_DATAテーブルの構成は、以下の通り。
SELECT * FROM dbo.USER_DATA ORDER BY ID ASC

サンプルプログラムの作成
作成したサンプルプログラムの構成は、以下の通り。
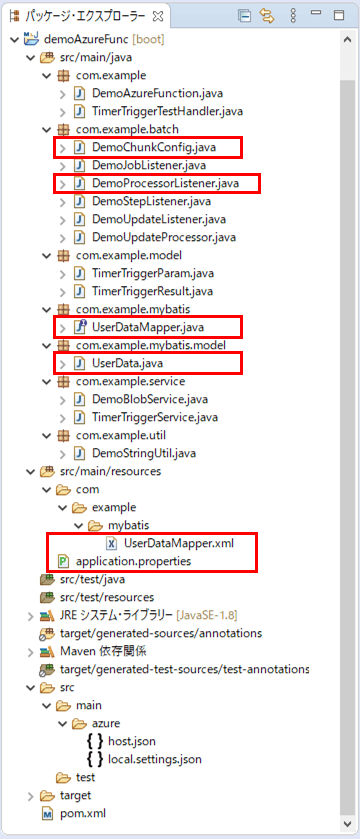
なお、上記の赤枠は、今回追加・変更したプログラムである。
データ加工前後の処理は以下の通りで、データ加工後に、USER_DATAテーブルのデータ取得/更新処理を追加している。
package com.example.batch;
import org.springframework.batch.core.ItemProcessListener;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import org.springframework.transaction.annotation.Transactional;
import com.example.mybatis.UserDataMapper;
import com.example.mybatis.model.UserData;
@Component
public class DemoProcessorListener implements ItemProcessListener<UserData, UserData> {
@Autowired
private UserDataMapper userDataMapper;
/**
* データ加工前の処理を定義する.
*/
@Override
public void beforeProcess(UserData item) {
// 何もしない
}
/**
* データ加工後の処理を定義する.
*/
@Override
@Transactional
public void afterProcess(UserData item, UserData result) {
// 処理結果がnullの場合は、処理を終了する
if(result == null) {
return;
}
// 既に登録済データのVERSIONを取得する
Integer id = Integer.parseInt(result.getId());
UserData ud = userDataMapper.findByIdRowLock(id);
// バージョンの値を結果に設定する
if(ud != null) {
result.setVersion(ud.getVersion());
} else {
result.setVersion(0);
}
// id=8の場合、バージョンを更新し、楽観ロックエラーにする
if(id == 8) {
userDataMapper.updateVersion(result);
}
}
/**
* データ編集エラー後の処理を定義する.
*/
@Override
public void onProcessError(UserData item, Exception e) {
// 何もしない
}
}
また、USER_DATAテーブルのエンティティクラスの内容は以下の通りで、カラム「VERSION」を追加している。
package com.example.mybatis.model;
import lombok.Data;
@Data
public class UserData {
/** ID */
private String id;
/** 名前 */
private String name;
/** 生年月日_年 */
private String birth_year;
/** 生年月日_月 */
private String birth_month;
/** 生年月日_日 */
private String birth_day;
/** 性別 */
private String sex;
/** メモ */
private String memo;
/** バージョン */
private Integer version;
}
さらに、USER_DATAテーブルのMapperインタフェース・XMLファイルの内容は以下の通りで、USER_DATAテーブルのデータ取得/更新処理を追加している。
package com.example.mybatis;
import org.apache.ibatis.annotations.Mapper;
import com.example.mybatis.model.UserData;
@Mapper
public interface UserDataMapper {
/**
* DBにUserDataオブジェクトがあれば更新し、なければ追加する.
* @param userData UserDataオブジェクト
*/
void upsert(UserData userData);
/**
* 引数のIDをキーにもつUserDataオブジェクトを行ロックをかけ取得する.
* @param id ID
* @return UserDataオブジェクト
*/
UserData findByIdRowLock(Integer id);
/**
* 引数のUserDataオブジェクトのバージョンを更新する.
* @param userData UserDataオブジェクト
*/
void updateVersion(UserData userData);
}
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.mybatis.UserDataMapper">
<update id="upsert" parameterType="com.example.mybatis.model.UserData">
MERGE INTO USER_DATA AS u
USING ( SELECT #{id} id, #{version} version ) s
ON ( u.id = s.id )
WHEN MATCHED AND u.version = s.version THEN
UPDATE SET name = #{name}, birth_year = #{birth_year}
, birth_month = #{birth_month}, birth_day = #{birth_day}, sex = #{sex}
, memo = #{memo}, version = #{version} + 1
WHEN NOT MATCHED THEN
INSERT ( id, name, birth_year, birth_month, birth_day, sex, memo, version )
VALUES (#{id}, #{name}, #{birth_year}, #{birth_month}, #{birth_day}
, #{sex}, #{memo}, #{version})
;
</update>
<select id="findByIdRowLock" parameterType="java.lang.Integer"
resultType="com.example.mybatis.model.UserData">
SELECT id, name, birth_year, birth_month, birth_day, sex, memo, version
FROM USER_DATA WITH(ROWLOCK, UPDLOCK, NOWAIT) <!-- SQL Databaseで行ロックをかける -->
WHERE id = #{id}
</select>
<update id="updateVersion" parameterType="com.example.mybatis.model.UserData">
UPDATE USER_DATA SET version = #{version} + 2 WHERE id = #{id}
</update>
</mapper>
また、プロパティファイルの内容は以下の通りで、USER_DATAテーブルのデータ取得/更新処理を追加することにより発生するエラーを回避するために、バッチモードで処理できるようにしている。
# Azure Storageの接続先 azure.storage.accountName=azureblobpurinit azure.storage.accessKey=(Azure Blob Storageのアクセスキー) azure.storage.blob-endpoint=https://azureblobpurinit.blob.core.windows.net azure.storage.containerName=blobcontainer # DB接続設定 spring.datasource.url=jdbc:sqlserver://azure-db-purinit.database.windows.net:1433;database=azureSqlDatabase spring.datasource.username=purinit@azure-db-purinit spring.datasource.password=(DBのパスワード) spring.datasource.driverClassName=com.microsoft.sqlserver.jdbc.SQLServerDriver # MyBatisでバッチモードで処理できるよう設定を変更 mybatis.executor-type=BATCH mybatis.configuration.default-executor-type=BATCH
さらに、Spring Batchの定義クラスは以下の通りで、DemoProcessorListenerの呼出処理と、writerメソッドに楽観ロックエラーを有効にする設定を追加している。
package com.example.batch;
import java.net.MalformedURLException;
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.batch.MyBatisBatchItemWriter;
import org.mybatis.spring.batch.builder.MyBatisBatchItemWriterBuilder;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.batch.item.ItemReader;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.file.FlatFileItemReader;
import org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper;
import org.springframework.batch.item.file.mapping.DefaultLineMapper;
import org.springframework.batch.item.file.transform.DelimitedLineTokenizer;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.UrlResource;
import com.example.mybatis.model.UserData;
import com.example.service.DemoBlobService;
import lombok.RequiredArgsConstructor;
@Configuration
@EnableBatchProcessing
@RequiredArgsConstructor
public class DemoChunkConfig {
/** ジョブ生成ファクトリ */
public final JobBuilderFactory jobBuilderFactory;
/** ステップ生成ファクトリ */
public final StepBuilderFactory stepBuilderFactory;
/** SQLセッションファクトリ */
public final SqlSessionFactory sqlSessionFactory;
/** データ加工処理 */
private final DemoUpdateProcessor demoUpdateProcessor;
/** データ加工前後処理 */
private final DemoProcessorListener demoProcessorListener;
/** データ書き込み前後処理 */
private final DemoUpdateListener demoUpdateListener;
/** ステップの前後処理 */
private final DemoStepListener demoStepListener;
/** BLOBへアクセスするサービス */
@Autowired
private DemoBlobService demoBlobService;
/**
* BlobStorageからファイルを読み込む.
* @return 読み込みオブジェクト
*/
@Bean
public FlatFileItemReader<UserData> reader() {
FlatFileItemReader<UserData> reader = new FlatFileItemReader<UserData>();
try {
// BlobStorageからファイル(user_data.csv)を読み込む際のURLをreaderに設定
String url = demoBlobService.getBlobUrl("user_data.csv");
reader.setResource(new UrlResource(url));
} catch (MalformedURLException ex) {
throw new RuntimeException(ex);
}
// ファイルを読み込む際の文字コード
reader.setEncoding("UTF-8");
// 1行目を読み飛ばす
reader.setLinesToSkip(1);
// ファイルから読み込んだデータをUserDataオブジェクトに格納
reader.setLineMapper(new DefaultLineMapper<UserData>() {
{
setLineTokenizer(new DelimitedLineTokenizer() {
{
setNames(new String[] { "id", "name", "birth_year"
, "birth_month", "birth_day", "sex", "memo" });
}
});
setFieldSetMapper(new BeanWrapperFieldSetMapper<UserData>() {
{
setTargetType(UserData.class);
}
});
}
});
return reader;
}
/**
* 読み込んだファイルのデータを、DBに書き込む.
* @return 書き込みオブジェクト
*/
@Bean
public MyBatisBatchItemWriter<UserData> writer() {
return new MyBatisBatchItemWriterBuilder<UserData>()
.sqlSessionFactory(sqlSessionFactory)
.statementId("com.example.mybatis.UserDataMapper.upsert")
.assertUpdates(true) // 楽観ロックエラーを有効にする
.build();
}
/**
* Spring Batchのジョブ内で指定する処理単位(ステップ)を定義する.
* @param reader 読み込みオブジェクト
* @param writer 書き込みオブジェクト
* @return Spring Batchのジョブ内で指定する処理単位
*/
@Bean
public Step step(ItemReader<UserData> reader, ItemWriter<UserData> writer) {
// 生成するステップ内で読み込み/加工/加工後/書き込み/書き込み後/ステップ実行前後の処理の
// 一連の流れを指定する
// その際のチャンクサイズ(=何件読み込む毎にコミットするか)を3に指定している
return stepBuilderFactory.get("step")
.<UserData, UserData>chunk(3)
.reader(reader)
.processor(demoUpdateProcessor)
.listener(demoProcessorListener)
.writer(writer)
.listener(demoUpdateListener)
.listener(demoStepListener)
.build();
}
/**
* Spring Batchのジョブを定義する.
* @param jobListener 実行前後の処理(リスナ)
* @param step 実行するステップ
* @return Spring Batchのジョブ
*/
@Bean
public Job updateUserData(DemoJobListener jobListener, Step step) {
// 生成するジョブ内で、実行前後の処理(リスナ)と処理単位(ステップ)を指定する
return jobBuilderFactory
.get("updateUserData")
.incrementer(new RunIdIncrementer())
.listener(jobListener)
.flow(step)
.end()
.build();
}
}その他のソースコード内容は、以下のサイトを参照のこと。
https://github.com/purin-it/azure/tree/master/azure-functions-csv-to-db-opt-lock/demoAzureFunc

サンプルプログラムの実行結果
サンプルプログラムの実行結果は、以下の通り。
1) バッチ実行前のBlob・DBの状態は、それぞれ以下の通り。
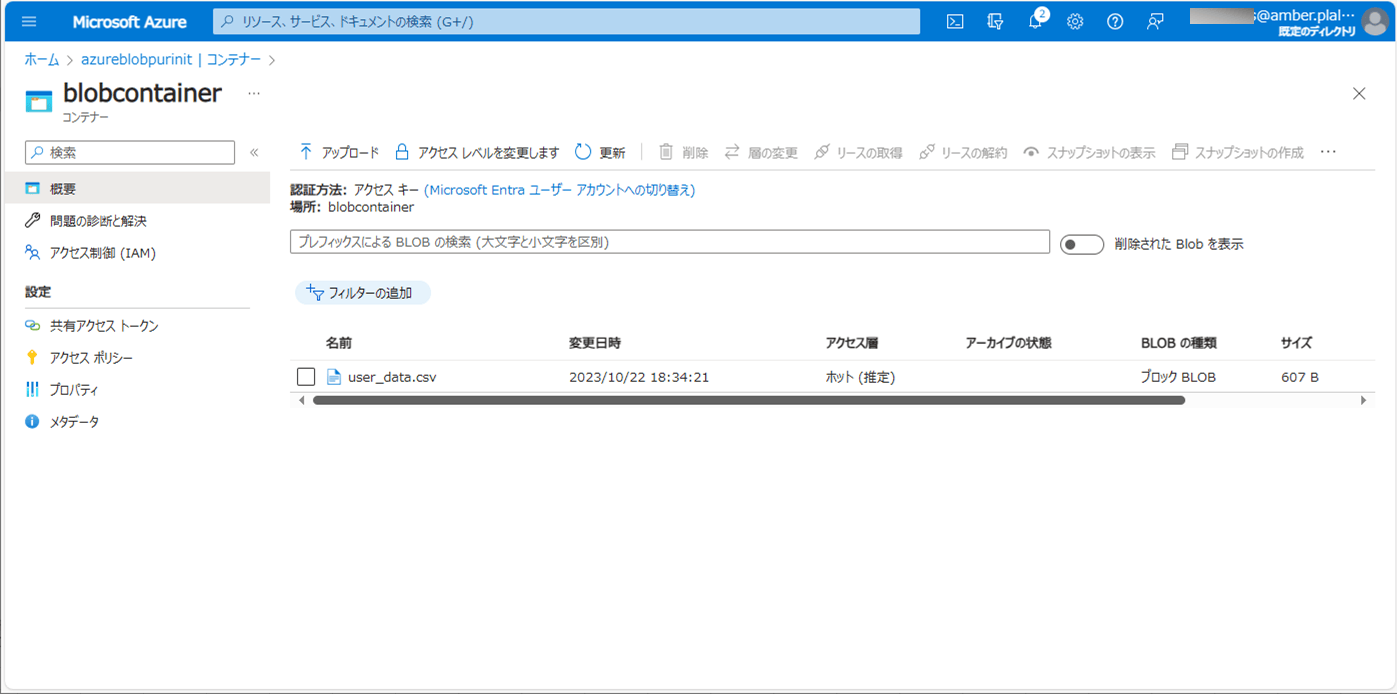
<配置したCSVファイル(user_data.csv)>
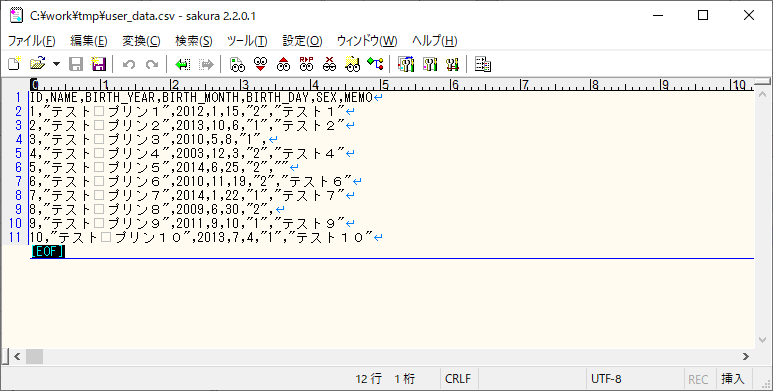
2) 以下のサイトの「サンプルプログラムの実行結果(ローカル)」「サンプルプログラムの実行結果(Azure上)」に記載の手順で、サンプルプログラムをAzure Functionsにデプロイする。

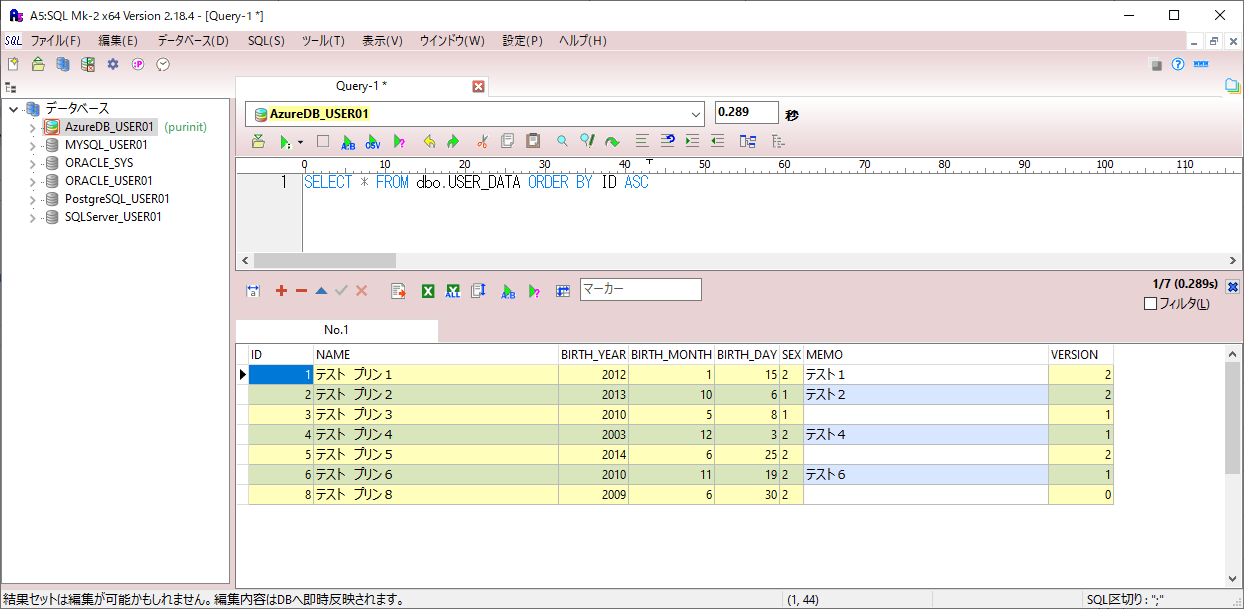
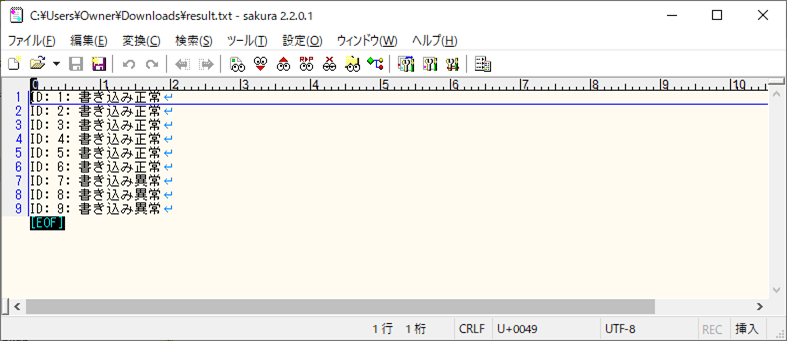
3) バッチ実行後のBlob・DBの状態は、それぞれ以下の通りで、楽観ロックエラーになったid=8付近の、id=7以上のデータが更新されていないことが確認できる。また、エラーになっていない、id=6以下のVERSIONが1ずつインクリメントされていることが確認できる。
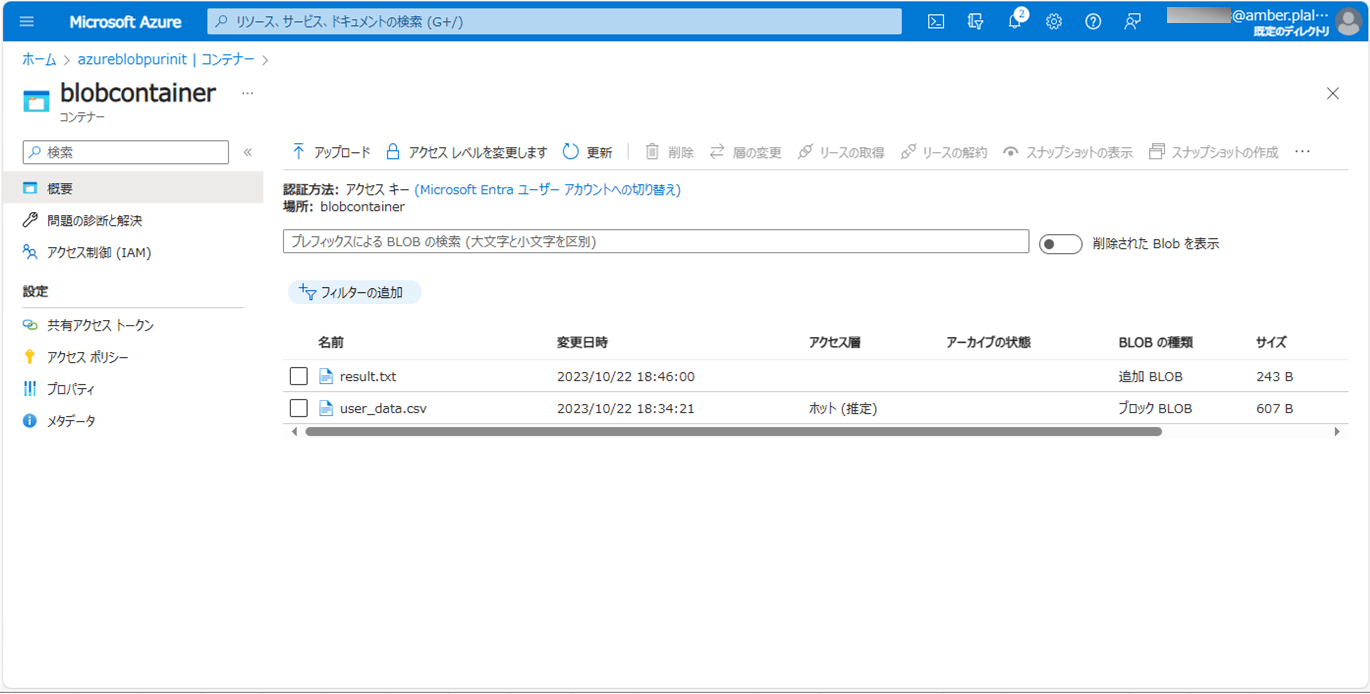
<作成された結果ファイル(result.txt)>
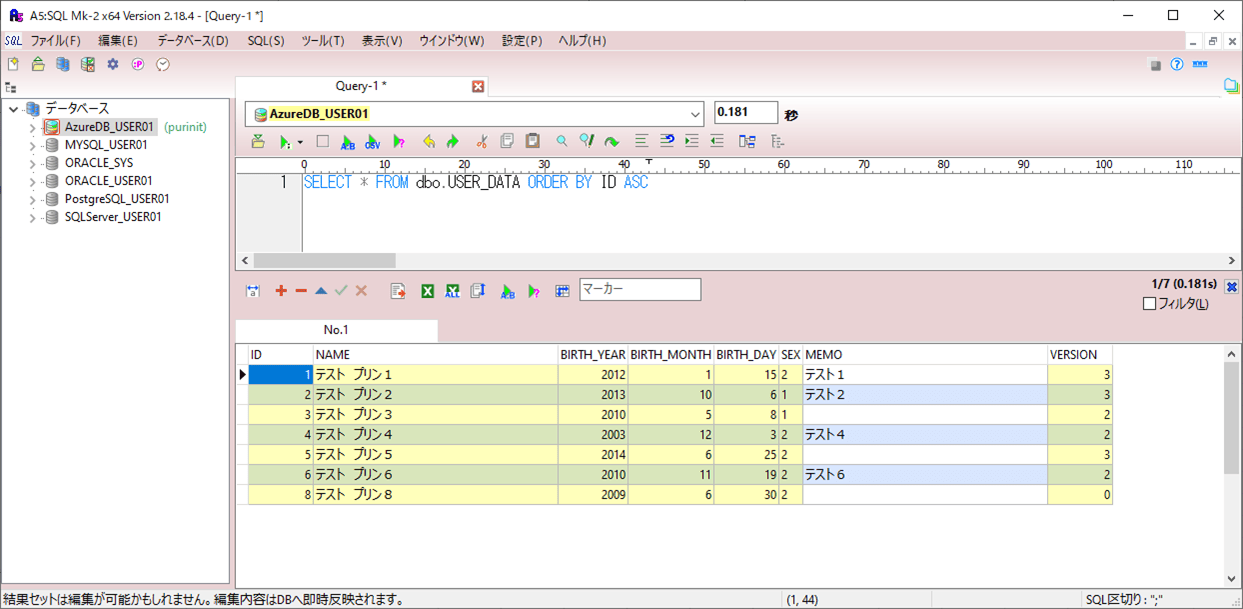
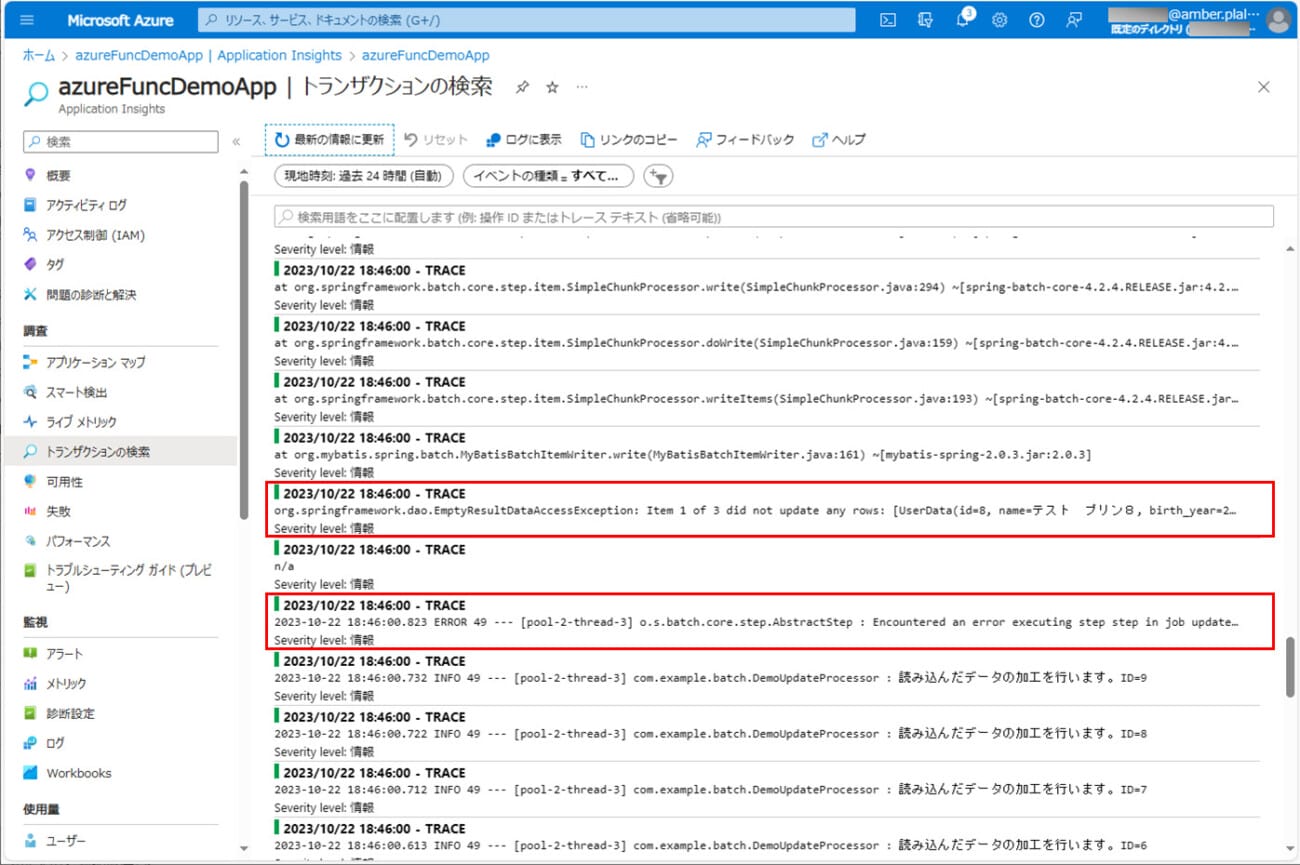
4) ログの出力結果は以下の通りで、id=8でエラーが発生していることが確認できる。
要点まとめ
- Spring BatchのChunkモデルで、DBのデータを読み込んだ後に書き込みを行えるようにするには、application.propertiesをバッチモードに設定する必要がある。
- Spring BatchのChunkモデルで、DBのテーブルに書き込む際に楽観ロックエラーにするには、MyBatisBatchItemWriterのassertUpdatesプロパティの値を、trueに設定すればよい。





