PythonのプログラムからAzure SQL Databaseに接続するには、ODBCドライバをインストールし、pyodbcパッケージやsqlalchemyパッケージをインストールすればよい。
今回は、FastAPIを利用したPythonのプログラムからAzure SQL Databaseに接続し、データを取得してみたので、その手順を共有する。
前提条件
下記サイトの手順に従って、Linux系のOS(Ubuntu)上のPythonの仮想環境(venv)でFastAPIを利用できること。

やってみたこと
Microsoft ODBC 18のインストール
PythonのプログラムからAzure SQL Databaseに接続するには、あらかじめODBCドライバをインストールしておく必要がある。
その手順は、以下のサイトの「Microsoft ODBC 18」、「Ubuntu」タブを参照のこと。
Microsoft ODBC Driver forSQL Serverをインストールする(Linux)
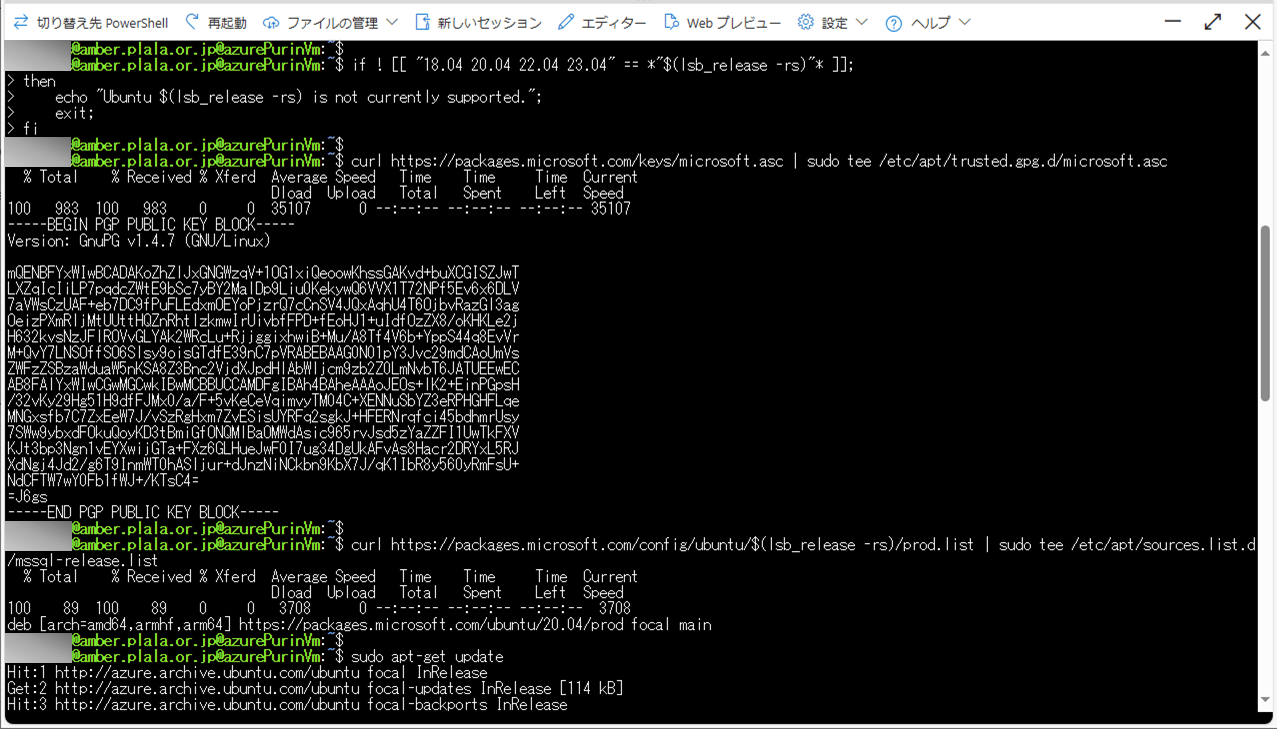
Azure Portalを起動し、Linux系のOS(Ubuntu)をもつ仮想マシンにログイン後、以下のコマンドを実行すればよい。
if ! [[ "18.04 20.04 22.04 23.04" == *"$(lsb_release -rs)"* ]];
then
echo "Ubuntu $(lsb_release -rs) is not currently supported.";
exit;
fi
curl https://packages.microsoft.com/keys/microsoft.asc | sudo tee /etc/apt/trusted.gpg.d/microsoft.asc
curl https://packages.microsoft.com/config/ubuntu/$(lsb_release -rs)/prod.list | sudo tee /etc/apt/sources.list.d/mssql-release.list
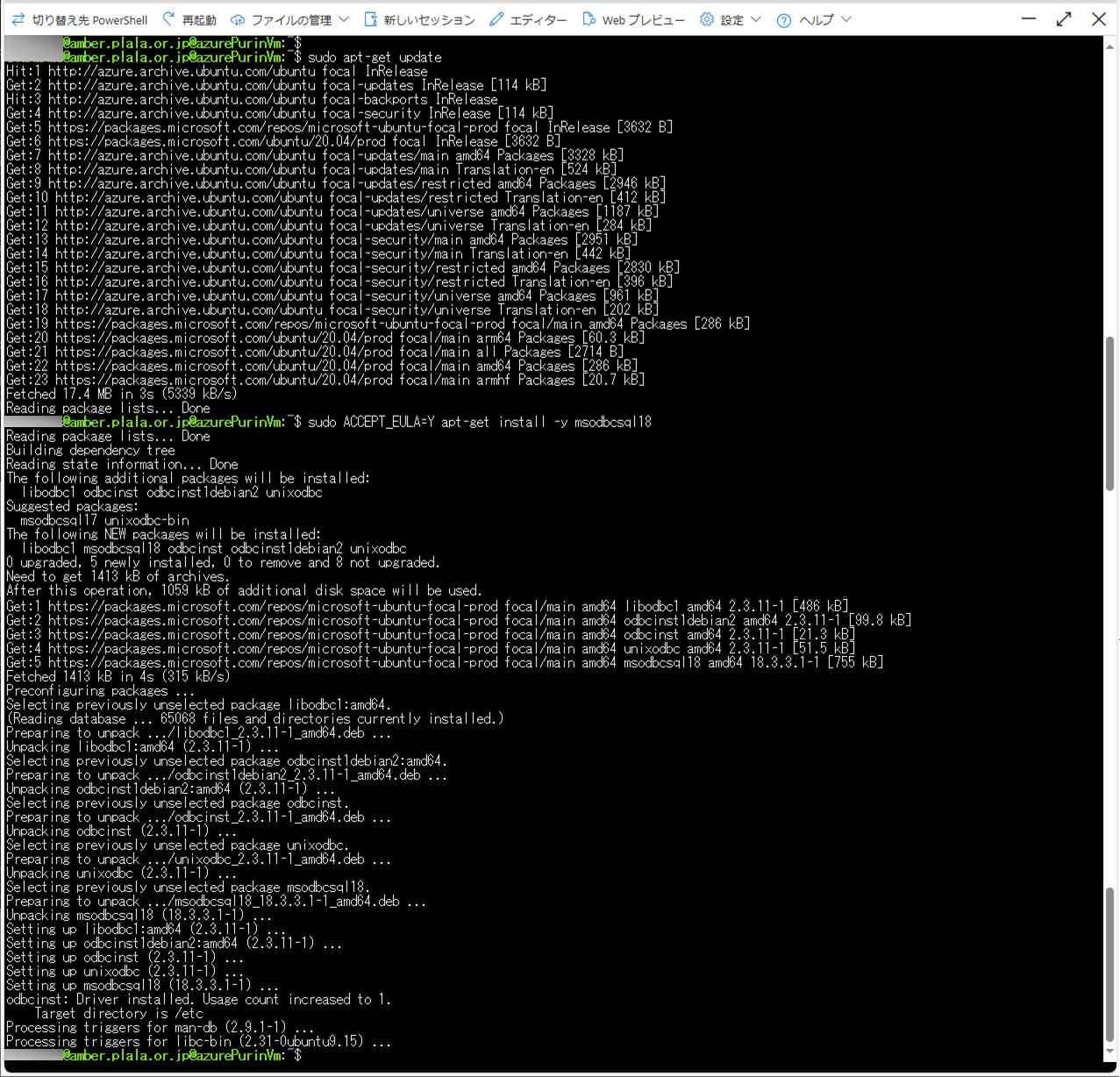
sudo apt-get update
sudo ACCEPT_EULA=Y apt-get install -y msodbcsql18
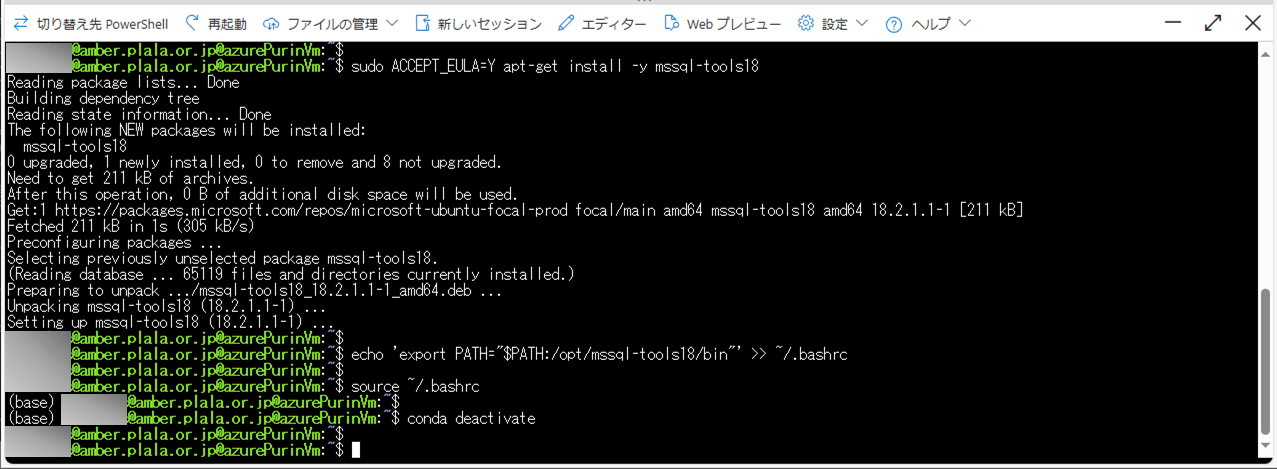
sudo ACCEPT_EULA=Y apt-get install -y mssql-tools18
echo 'export PATH="$PATH:/opt/mssql-tools18/bin"' >> ~/.bashrc
source ~/.bashrc
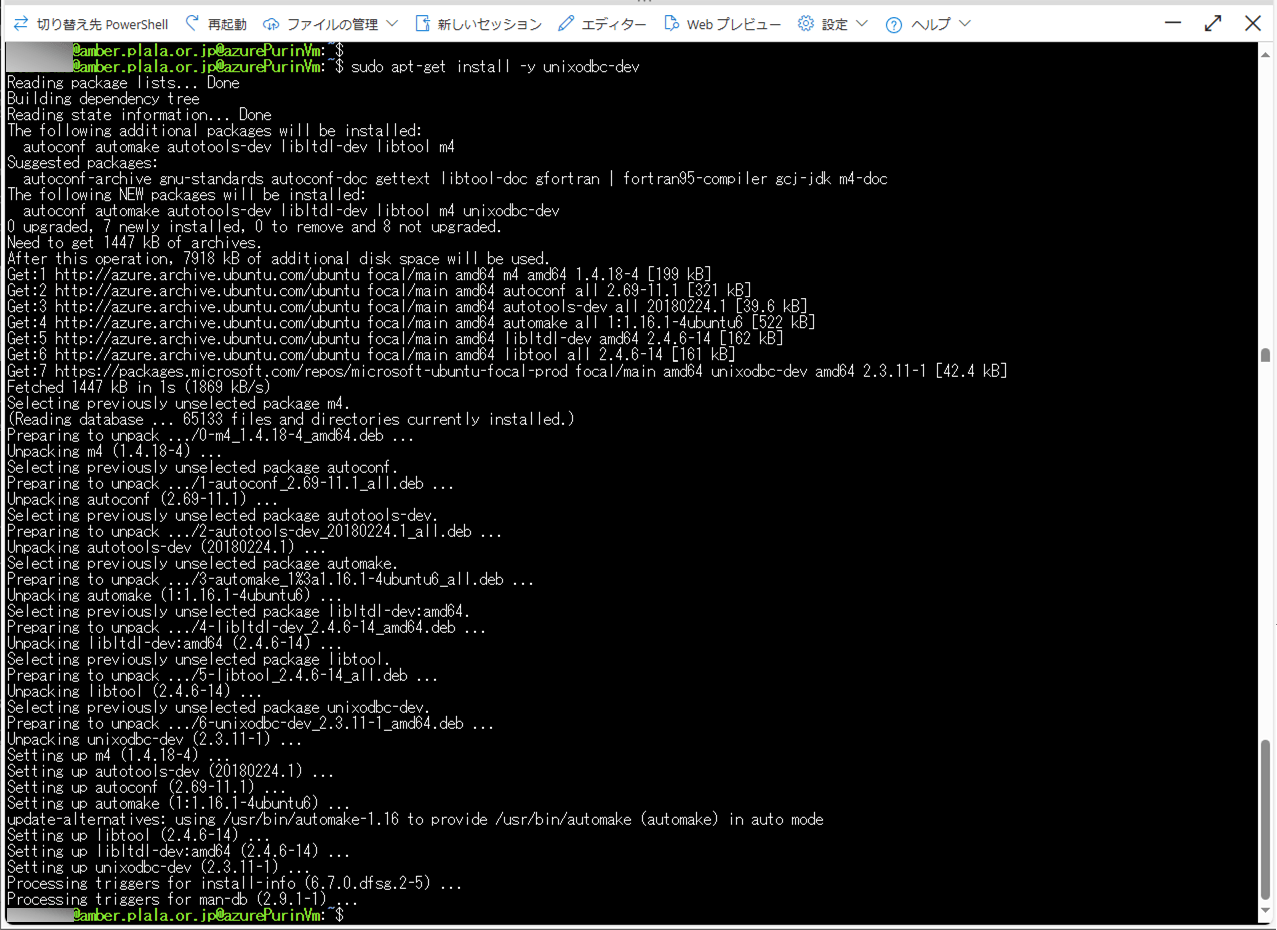
sudo apt-get install -y unixodbc-dev実際にコンソール上で実行した内容は、以下の通り。

pyodbc、sqlalchemyパッケージのインストール
PythonのプログラムからAzure SQL Databaseに接続するには、あらかじめpyodbcパッケージとsqlalchemyパッケージをインストールしておく必要がある。その手順は、以下の通り。
1) 仮想環境(venv)である仮想環境(test1)を起動する。

2)「pip install pyodbc」コマンドで、pyodbcパッケージをインストールする。

3)「pip install sqlalchemy」コマンドで、sqlalchemyパッケージをインストールする。
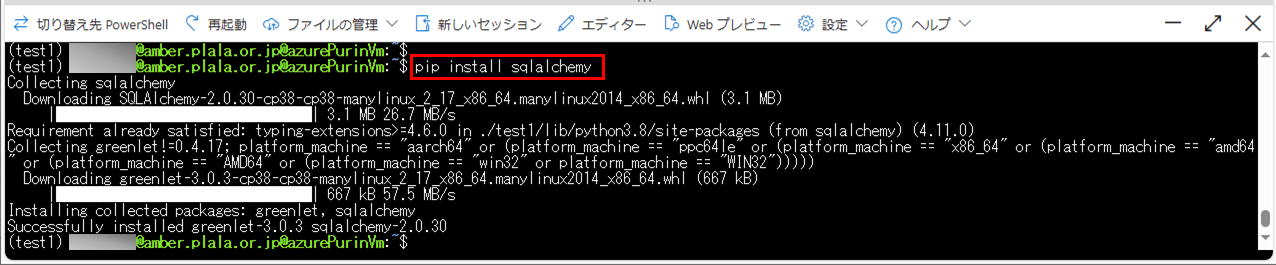
4) インストール済のpyodbc, sqlalchemyを確認した結果は、以下の通り。


サンプルプログラムの作成と実行
作成したサンプルプログラムの内容は、以下の通り。
from fastapi import FastAPI
import sqlalchemy as sa
import urllib
# SQL Databaseへの接続情報
driver='{ODBC Driver 18 for SQL Server}'
server = 'azure-db-purinit.database.windows.net'
database = 'azureSqlDatabase'
username = 'purinit@azure-db-purinit'
password = '(DBのパスワード)'
# SQL Databaseに接続
odbc_connect = urllib.parse.quote_plus('DRIVER=' + driver + ';SERVER=' + server
+ ';DATABASE=' + database + ';UID=' + username + ';PWD=' + password)
engine = sa.create_engine('mssql+pyodbc:///?odbc_connect=' + odbc_connect)
app = FastAPI()
@app.get("/")
def read_root():
return {"Hello": "FastAPI"}
@app.get("/users")
def read_users():
ret_val = '{' # 返却用文字列
with engine.connect() as conn:
query = sa.text("SELECT * FROM dbo.USER_DATA ORDER BY ID ASC;")
rs = conn.execute(query)
for row in rs:
# 各レコードの各項目をJSON形式に編集
ret_val += "{'id':'" + str(row[0]) + "'"
ret_val += ", 'name':'" + row[1] + "'"
ret_val += ", 'birthday':'" + str(row[2]) + '年'
ret_val += str(row[3]) + '月' + str(row[4]) + '日' + "'"
ret_val += ", 'sex':'" + ('男' if row[5]=='1' else '女') + "'"
ret_val += ", 'memo':'" + str(row[6]) + "'"
ret_val += ", 'version':'" + str(row[7]) + "'},"
# 末尾のカンマを削除し、閉じ括弧を付与
ret_val = ret_val.rstrip(',')
ret_val += "}"
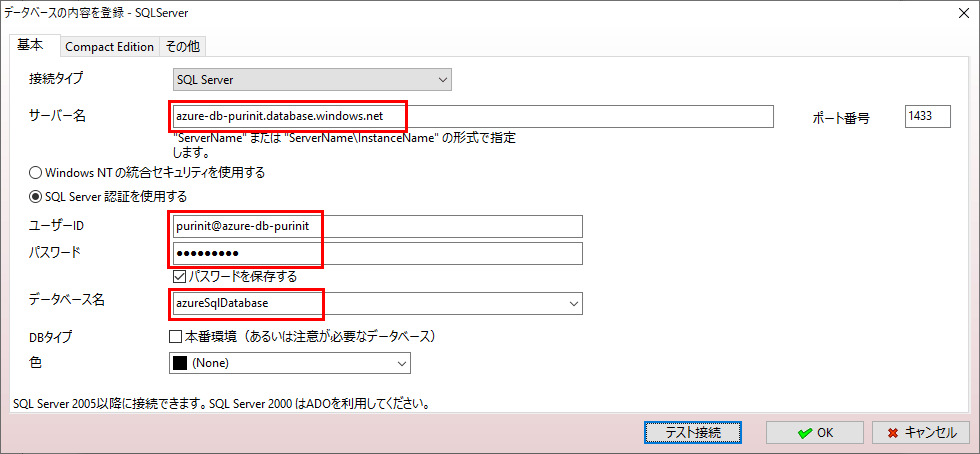
return ret_valなお、上記接続先の「ODBC Driver 18 for SQL Server」は、以下の赤枠部分を記載している。

また、サーバー名・データベース名・ユーザー名・パスワードは、以下の赤枠部分を記載している。
さらに、上記プログラムを作成中に発生したエラー解決のために参照したサイトは、以下の通り。
https://stackoverflow.com/questions/75464271/attributeerror-str-object-has-no-attribute-execute-on-connection
https://stackoverflow.com/questions/35359969/typeerror-tuple-indices-must-be-integers-not-str
上記サンプルプログラムを実行した結果は、以下の通り。
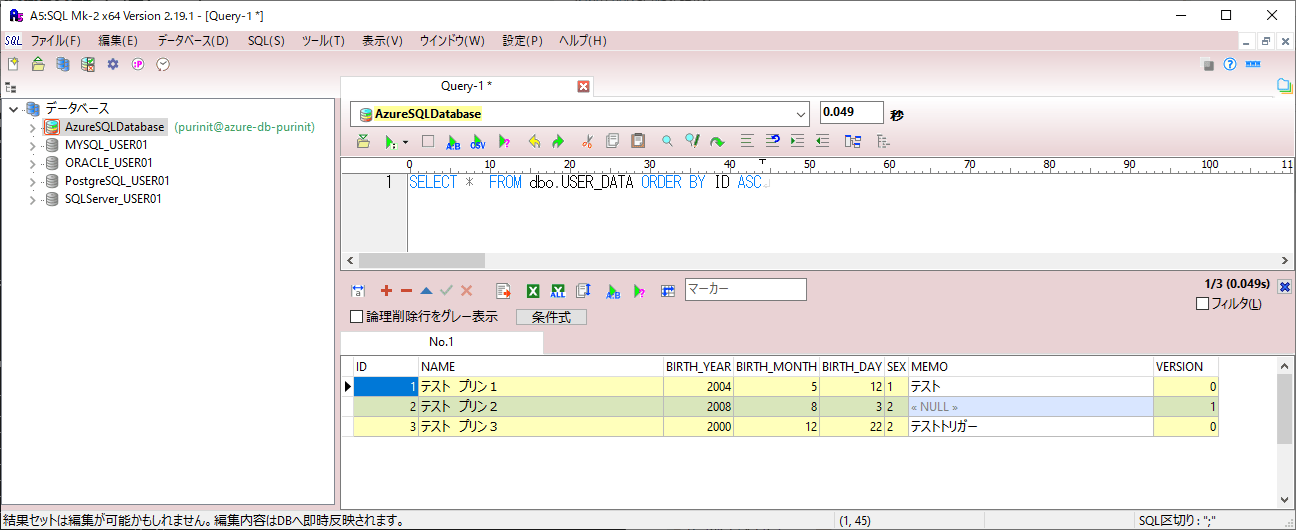
1) SQL DatabaseのUSER_DATAテーブルの内容は、以下の通り。
2)「uvicorn main:app –reload」コマンドで、Uvicornを使用したFastAPIアプリケーションを実行する。

3) 別セッションから「http://127.0.0.1:8000/users」にアクセスした結果は以下の通りで、1)でSQLを実行したときと同じデータがJSON形式で出力されていることが確認できる。

なお、別セッションの起動方法は、以下の記事の「FastAPIを利用したプログラムの実行」を参照のこと。
要点まとめ
- PythonのプログラムからAzure SQL Databaseに接続するには、ODBCドライバをインストールし、pyodbcパッケージやsqlalchemyパッケージをインストールすればよい。





