前回、Oracle上で実行計画の取得を行ってみたが、今回は他のDB上で同様の実行計画を取得してみたので、その内容を共有する。
前提条件
下記記事の「ストアドプログラムによるデータ追加」が完了していること。

やってみたこと
Oracleの場合の実行結果
Oracleの場合の実行結果は、下記記事を参照のこと。

MySQLの場合の実行結果
MySQLの場合も、「USER_DATA」テーブルのカラム「ID」に主キーのインデックスが設定されていることが確認できる。そのSQLの確認結果は、以下の通り。
SELECT TABLE_SCHEMA, TABLE_NAME, COLUMN_NAME, INDEX_NAME FROM INFORMATION_SCHEMA.STATISTICS WHERE TABLE_NAME='USER_DATA'
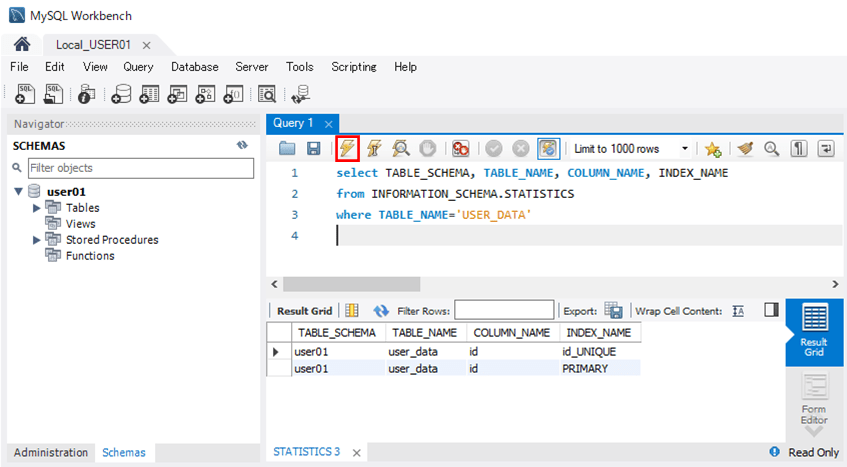
また、「USER_DATA」テーブルからID=1のデータを抽出する際、インデックス検索が行われる。その際、以下のSQLを実行して、type, possible_keys, keyの値を確認することで、主キーを用いたインデックス検索が行われていることが確認できる。
EXPLAIN SELECT * FROM USER_DATA WHERE ID = 1
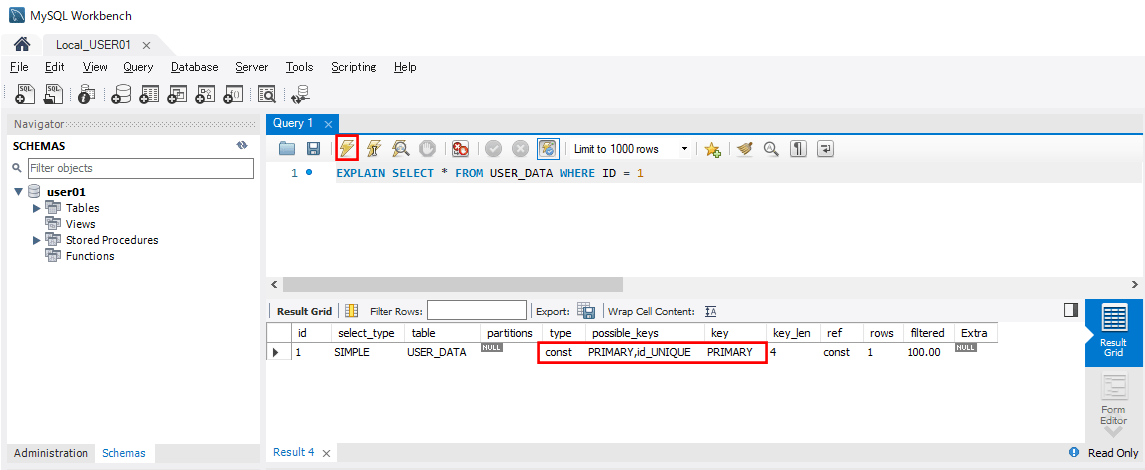
なお、上記で表示されている項目については、以下のサイトを参照のこと。
https://style.potepan.com/articles/18910.html
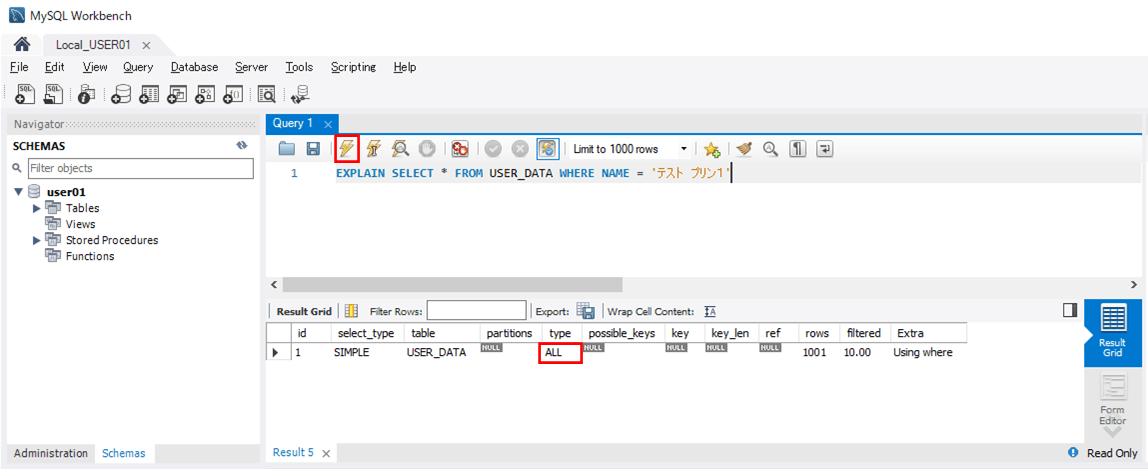
さらに、「USER_DATA」テーブルからNAME = ‘テスト プリン1’のデータを抽出する際、インデックス検索が行われない。その際、以下のSQLを実行して、type=ALLとなっていることを確認することで、インデックス検索が行われずフルスキャンが行われていることが確認できる。
EXPLAIN SELECT * FROM USER_DATA WHERE NAME = 'テスト プリン1'

PostgreSQLの場合の実行結果
PostgreSQLの場合も、「USER_DATA」テーブルのカラム「ID」に主キーのインデックスが設定されていることが確認できる。そのSQLの確認結果は、以下の通り。
SELECT
c.table_name -- テーブル名
, c.column_name -- 列名
, c.data_type -- データ型
, c.ordinal_position -- 列順
, tc.constraint_type -- 制約名
FROM information_schema.columns c
INNER JOIN information_schema.constraint_column_usage ccu
ON c.table_name = ccu.table_name
AND c.column_name = ccu.column_name
INNER JOIN information_schema.table_constraints tc
ON tc.table_catalog = c.table_catalog
AND tc.table_schema = c.table_schema
AND tc.table_name = c.table_name
AND tc.constraint_name = ccu.constraint_name
WHERE tc.constraint_type = 'PRIMARY KEY'
AND c.table_name = 'user_data'
ORDER BY c.table_name, c.ordinal_position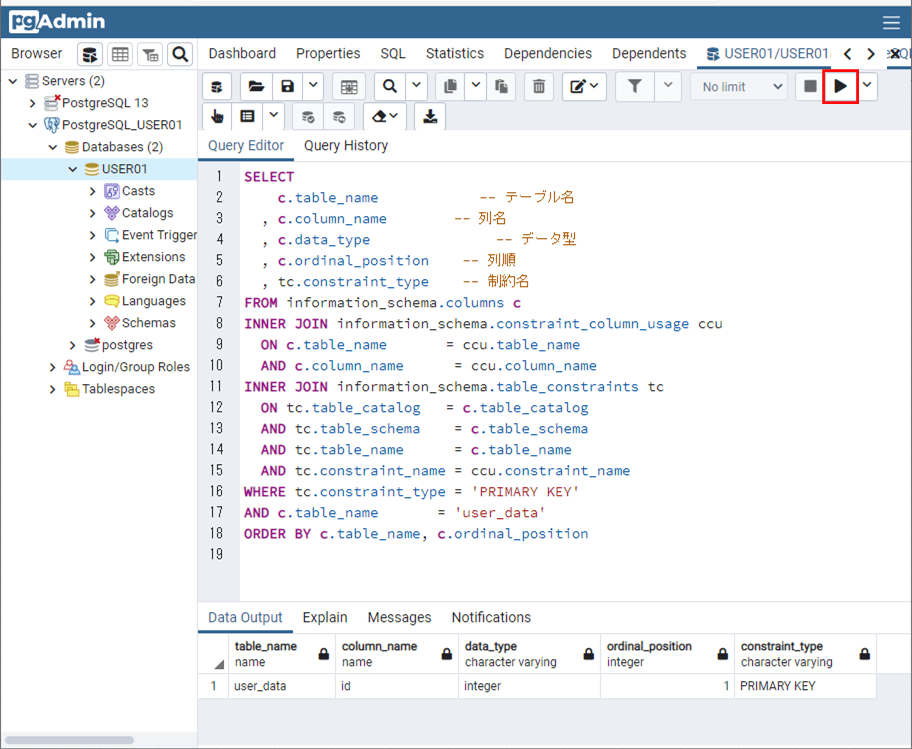
なお、上記SQLは、以下のサイトを参考にして作成している。
https://web.archive.org/web/20160912093856/http://log.nissuk.info/2014/03/blog-post.html
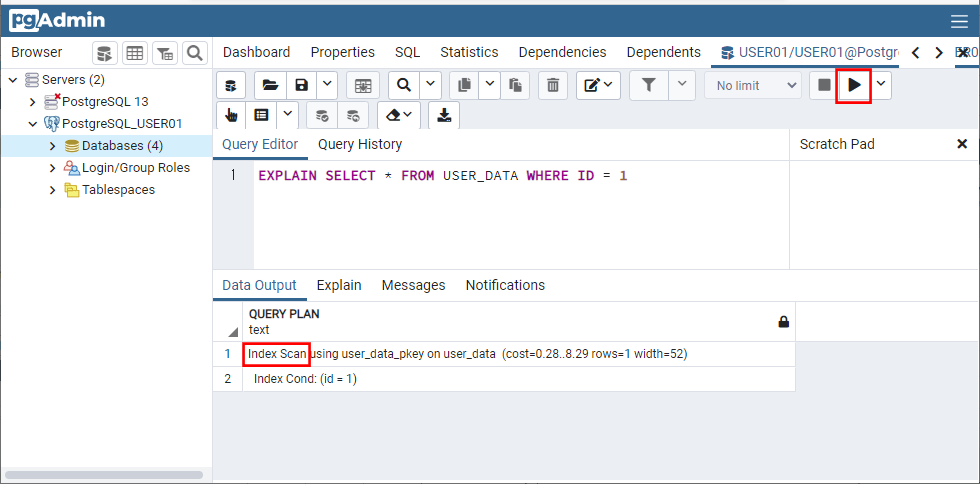
また、「USER_DATA」テーブルからID=1のデータを抽出する際、インデックス検索が行われる。その際、以下のSQLを実行して、「Index Scan」と表示されることを確認することで、インデックス検索が行われていることが確認できる。
EXPLAIN SELECT * FROM USER_DATA WHERE ID = 1
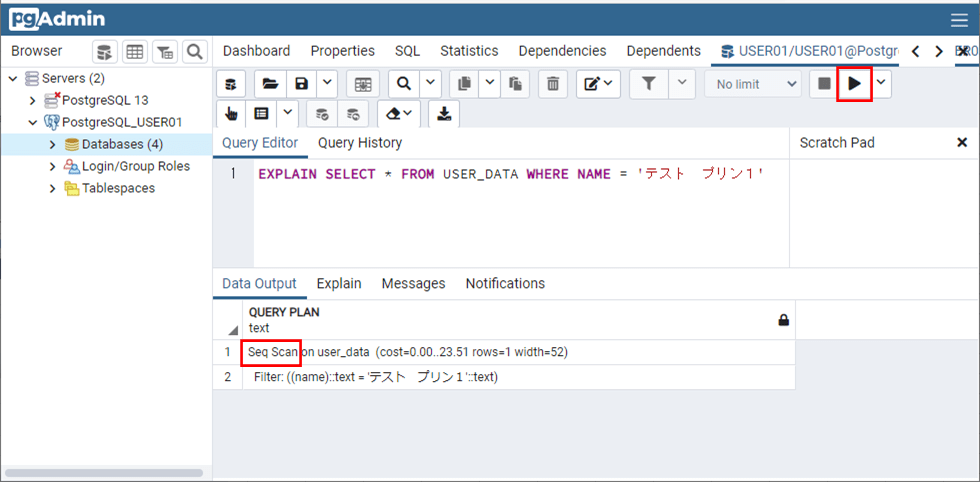
さらに、「USER_DATA」テーブルからNAME = ‘テスト プリン1’のデータを抽出する際、インデックス検索が行われない。その際、以下のSQLを実行して、「Seq Scan」と表示されることを確認することで、インデックス検索が行われずフルスキャンが行われていることが確認できる。
EXPLAIN SELECT * FROM USER_DATA WHERE NAME = 'テスト プリン1'

SQL Serverの場合の実行結果
SQL Serverの場合も、「USER_DATA」テーブルのカラム「ID」にインデックスが設定されていることが確認できる。そのSQLの確認結果は、以下の通り。
SELECT
i.name AS index_name
,o.name AS table_name
,col.name AS column_name
FROM
sysindexkeys ik
,sysobjects o
,syscolumns col
,sysindexes i
WHERE
ik.id = o.id
AND ik.id = col.id
AND ik.colid = col.colid
AND ik.id = i.id
AND ik.indid = i.indid
AND o.xtype = 'U'
AND o.name = 'user_data'
ORDER BY
i.name, ik.id, ik.indid, ik.keyno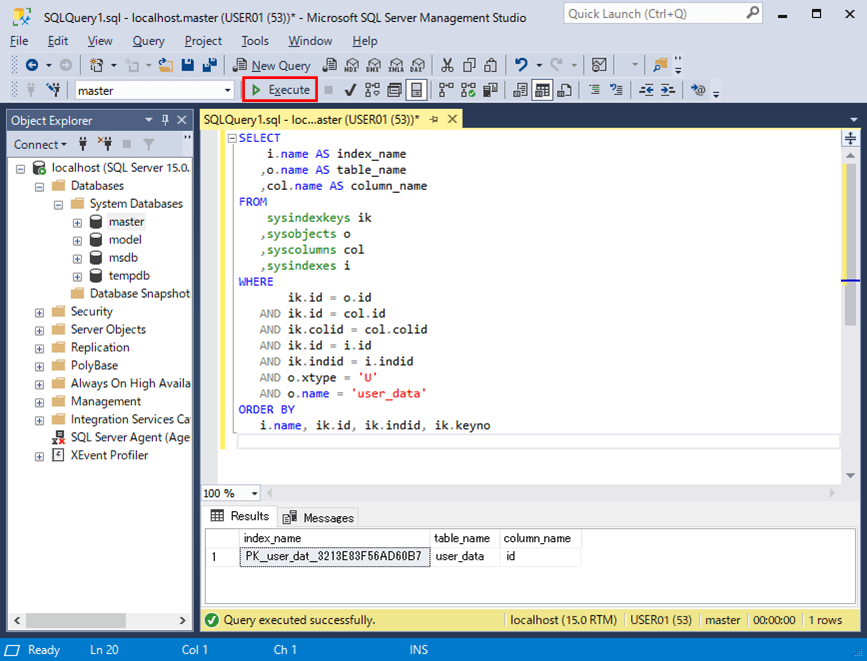
なお、上記SQLは、以下のサイトを参考にして作成している。
http://kslaboratory.blogspot.com/2010/01/sql.html
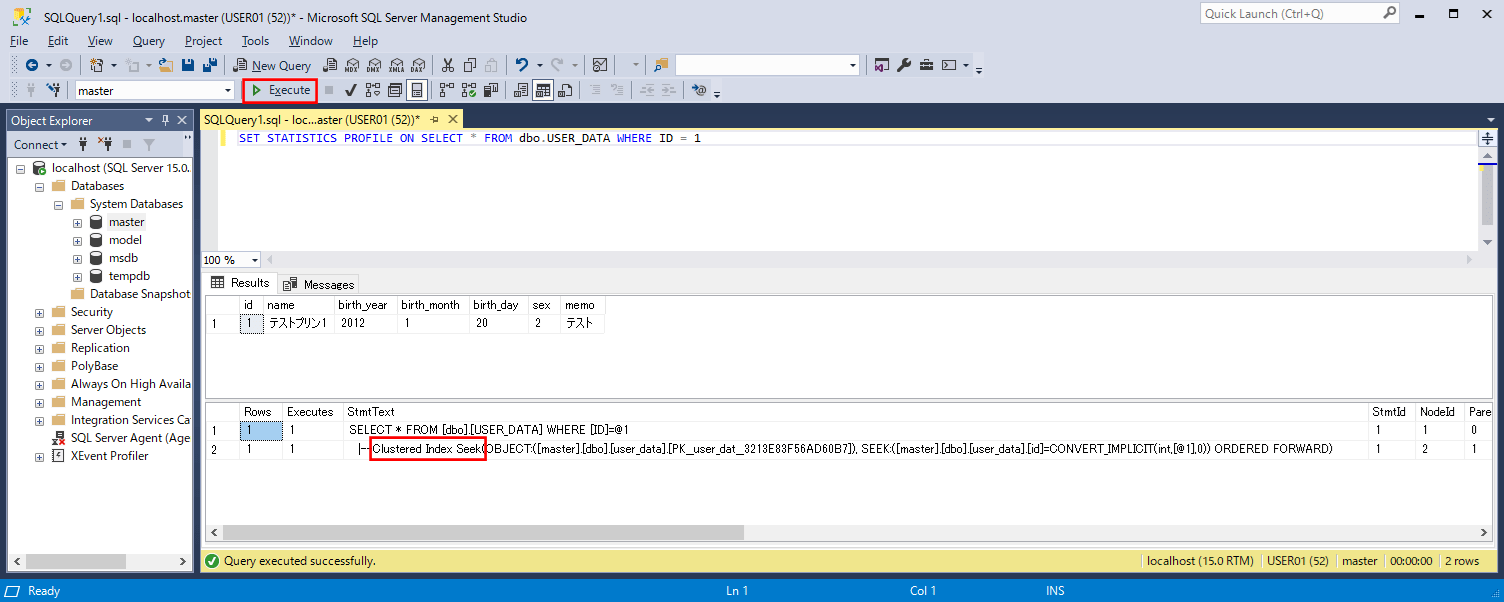
また、「USER_DATA」テーブルからID=1のデータを抽出する際、インデックス検索が行われる。その際、以下のSQLを実行して、「Index Seek」と表示されることを確認することで、インデックス検索が行われていることが確認できる。
SET STATISTICS PROFILE ON SELECT * FROM dbo.USER_DATA WHERE ID = 1
さらに、「USER_DATA」テーブルからNAME = ‘テスト プリン1’のデータを抽出する際、インデックス検索が行われない。その際、以下のSQLを実行して、「Index Scan」と表示されることを確認することで、インデックス検索が行われずフルスキャンが行われていることが確認できる。
SET STATISTICS PROFILE ON SELECT * FROM dbo.USER_DATA WHERE NAME = N'テストプリン1'
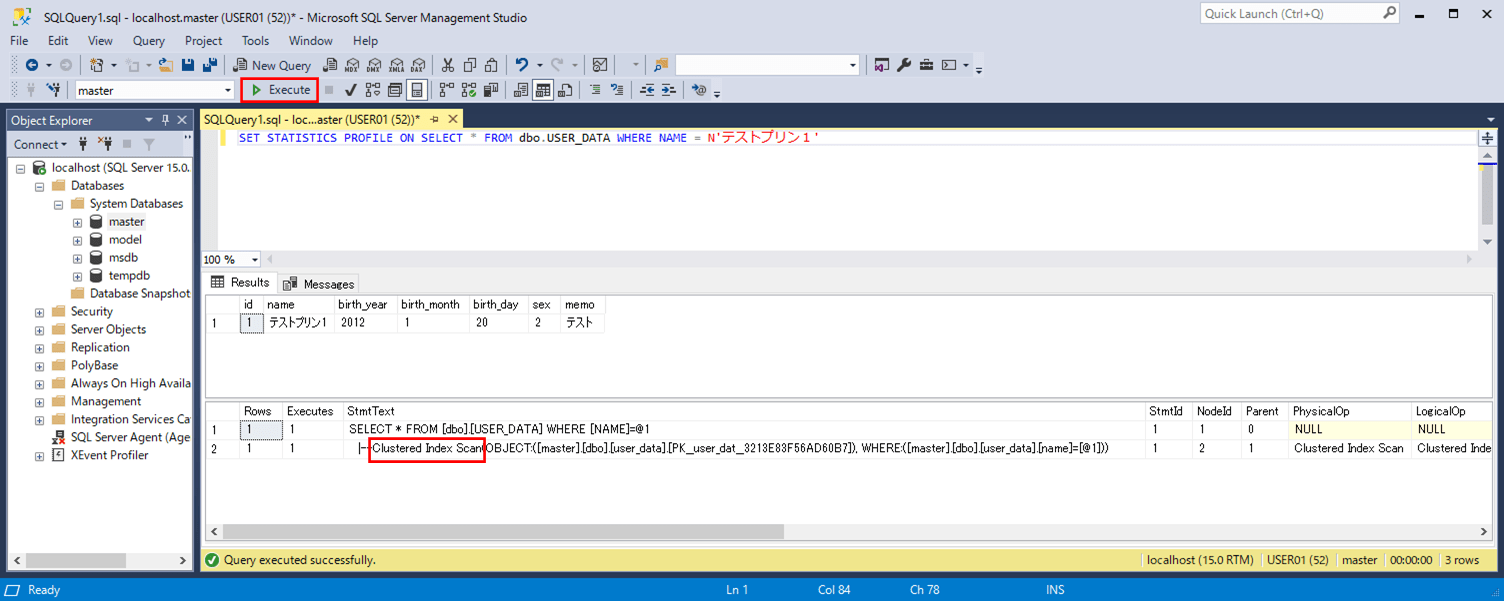
なお、「Index Seek」「Index Scan」については、以下のサイトを参照のこと。
https://use-the-index-luke.com/ja/sql/explain-plan/sql-server/operations
最後に「SET STATISTICS PROFILE OFF」とすると、実行計画の表示欄が閉じる。

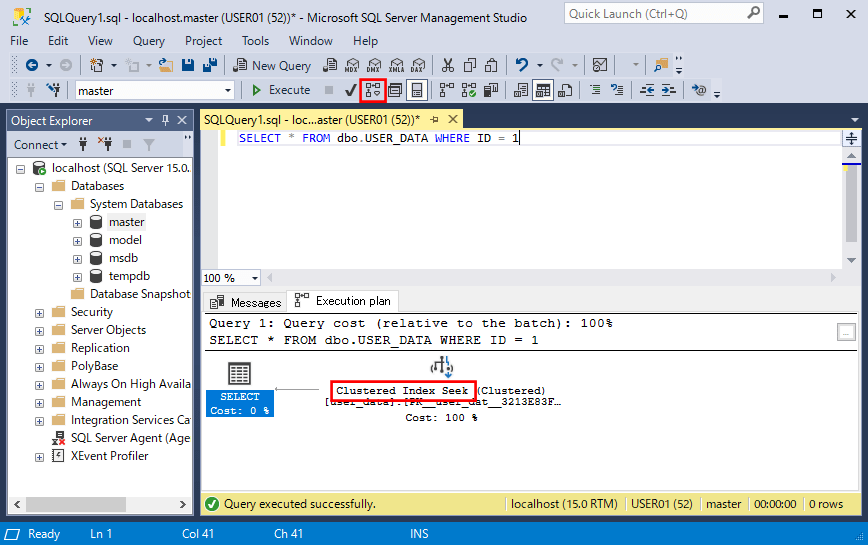
また、SQL Serverの場合は、SQLを指定後に「実行計画」ボタンを押下することで、ビジュアルベースで実行計画を表示することができる。
SELECT * FROM dbo.USER_DATA WHERE ID = 1
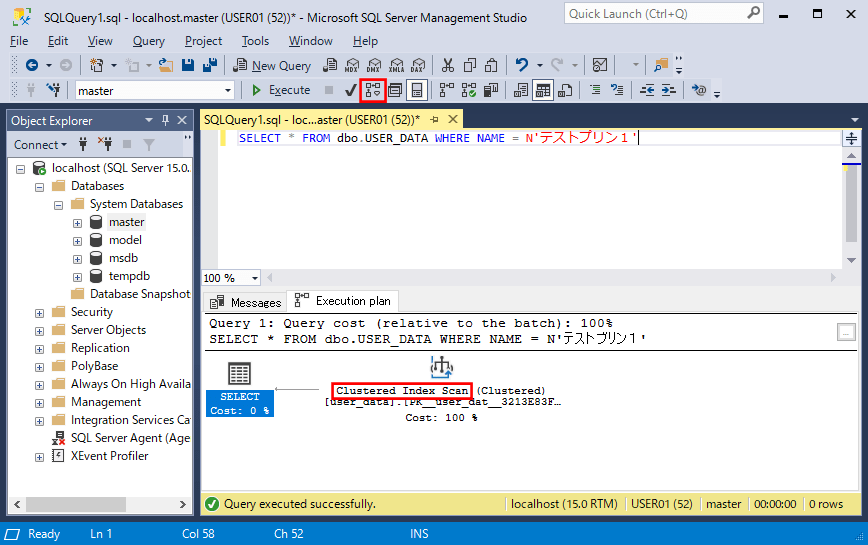
SELECT * FROM dbo.USER_DATA WHERE NAME = N'テストプリン1'
要点まとめ
- MySQL、PostgreSQLの場合は、SQLの先頭に「EXPLAIN」を付与することで、実行計画が取得できる。
- SQL Serverの場合は、SQLの先頭に「SET STATISTICS PROFILE ON」を付与するか、実行計画ボタンを押下することで、実行計画が取得できる。





