Spring Batchには、ChunkモデルとTaskletモデルがあり、以下のサイトに記載の通り、大量のデータを処理するにはChunkモデルを利用するとよい。
https://terasoluna-batch.github.io/guideline/5.0.0.RELEASE/ja/Ch03_ChunkOrTasklet.html
今回は、DBの(カラム数を7個持つ)テーブルデータ30万件を、Blob上のCSVファイルに出力してみたので、その結果を共有する。
前提条件
下記記事のサンプルプログラムを作成済であること。

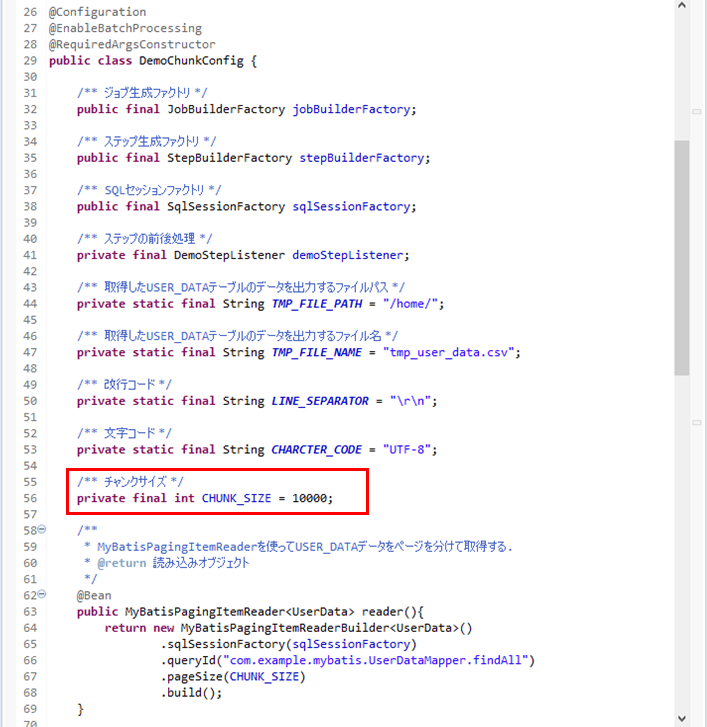
また、「DemoChunkConfig.java」のチャンクサイズを、以下のように1万に設定していること。

テストデータ作成
取得元のDB(Azure SQL Database上のUSER_DATAテーブル)に、30万件のデータを追加する。その手順は、以下の通り。
1) 指定した件数のテストデータを作成する、ストアドプロシージャ(LOAD_USER_DATA )を作成する。そのソースコードは、以下の通り。
CREATE OR ALTER PROCEDURE dbo.LOAD_USER_DATA
@cntNum INT
AS BEGIN
DECLARE @tmp INT;
SET @tmp = 1;
WHILE @tmp <= @cntNum
BEGIN
INSERT INTO dbo.USER_DATA (id, name, birth_year
, birth_month, birth_day, sex, memo)
VALUES (@tmp, N'テスト プリン', 2005
, 3, 21, '1', N'メモ')
SET @tmp = @tmp + 1;
END;
END2) A5M2で、「プロシージャモード」によって、1)のソースコードを実行する。
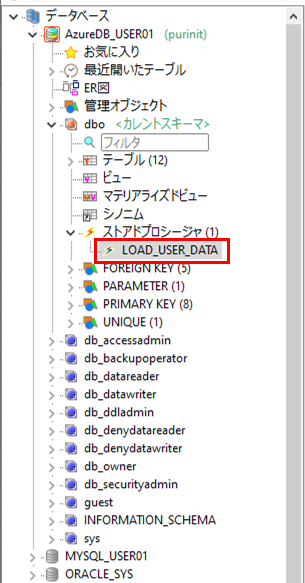
3) 2)の実行を行うと、以下のように、ストアドプロシージャ(LOAD_USER_DATA)が作成されていることが確認できる。
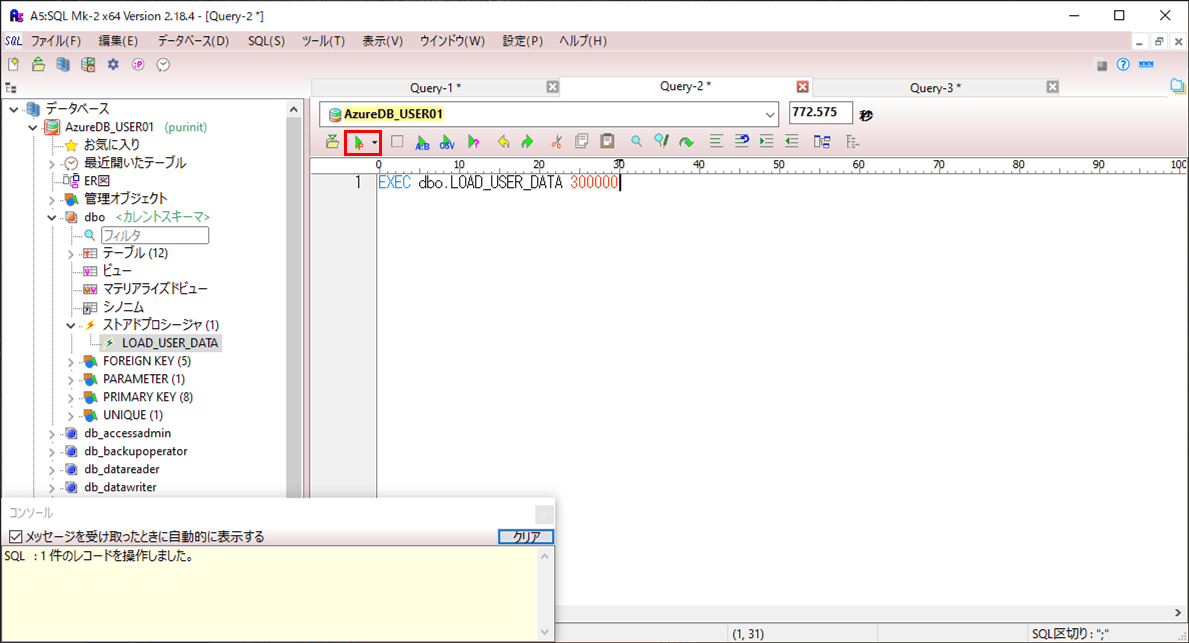
4) 30万件のデータを追加する設定で、ストアドプロシージャ(LOAD_USER_DATA)を実行する。
5) 4)の実行が完了すると、以下のように、30万件のデータが追加されていることが確認できる。
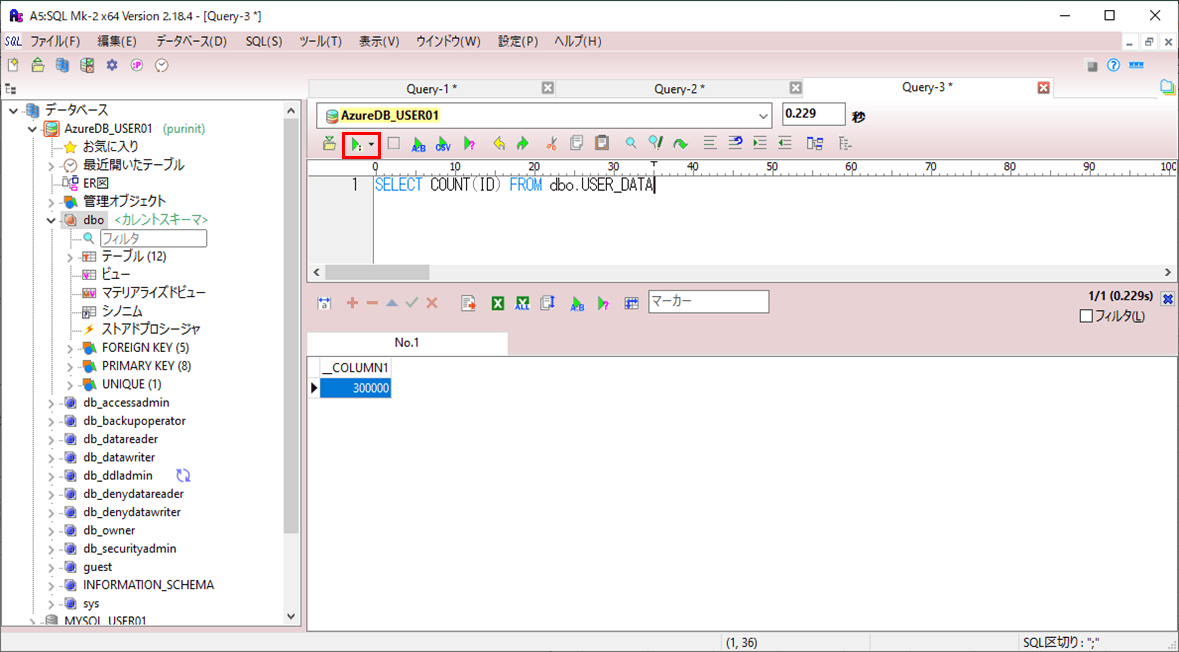
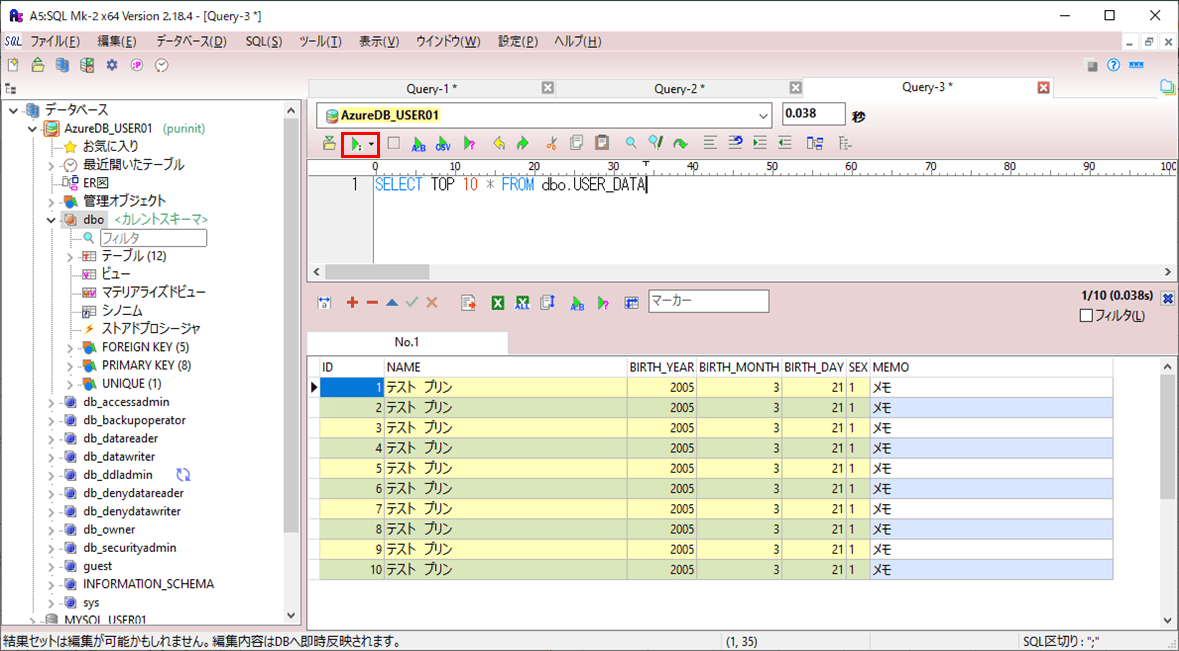

サンプルプログラムの実行結果
サンプルプログラム(前提条件に記載)の実行結果は、以下の通り。
1) 以下のサイトの「サンプルプログラムの実行結果(ローカル)」「サンプルプログラムの実行結果(Azure上)」に記載の手順で、サンプルプログラムをAzure Functionsにデプロイする。

2) バッチ実行後に、Blob Storageに、以下のCSVファイルが出力されていることが確認できる。
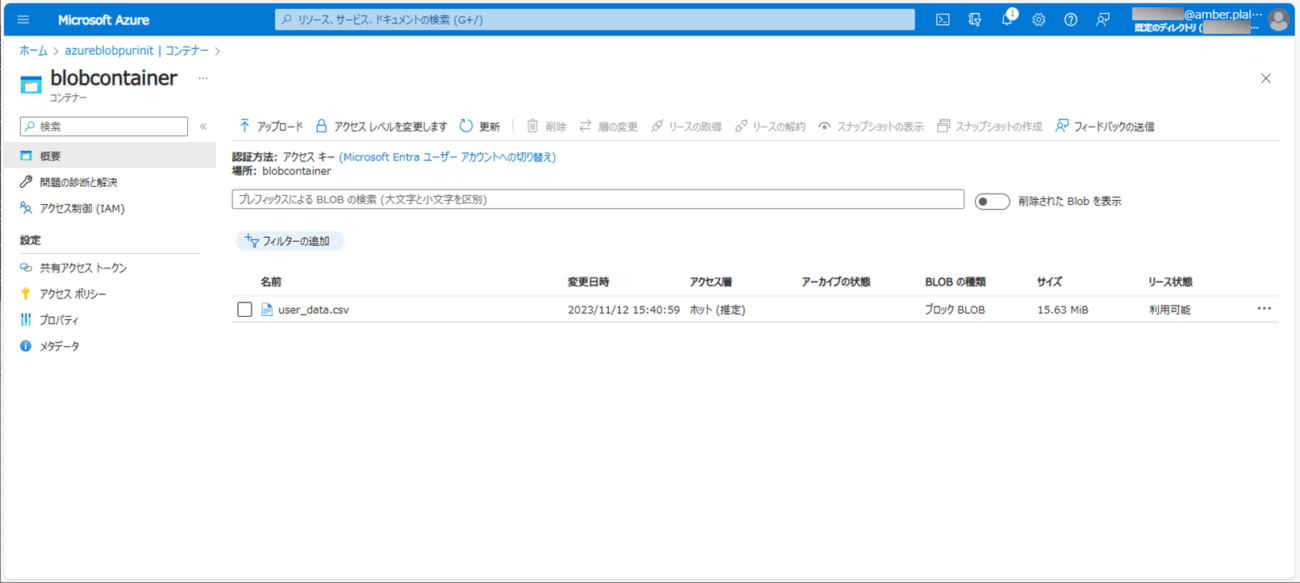
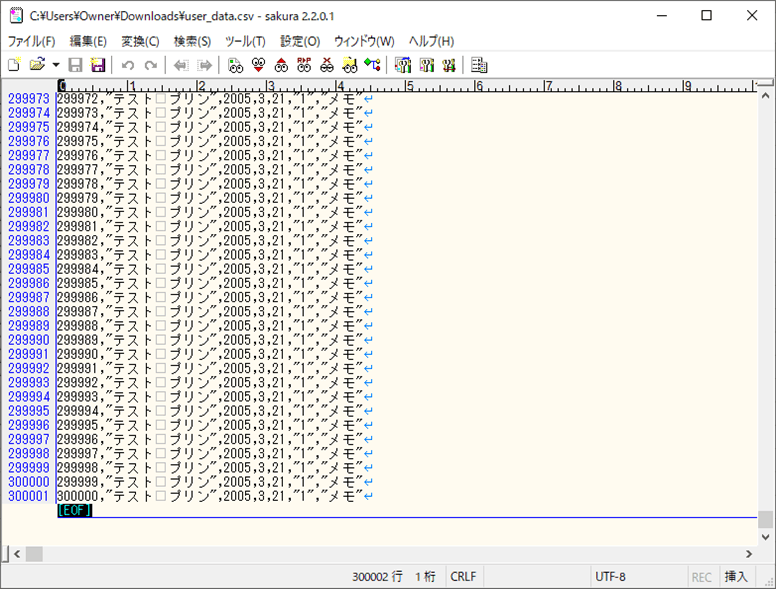
3) 2)で出力されたファイルの内容は以下の通りで、30万件のデータが全て出力されていることが確認できる。
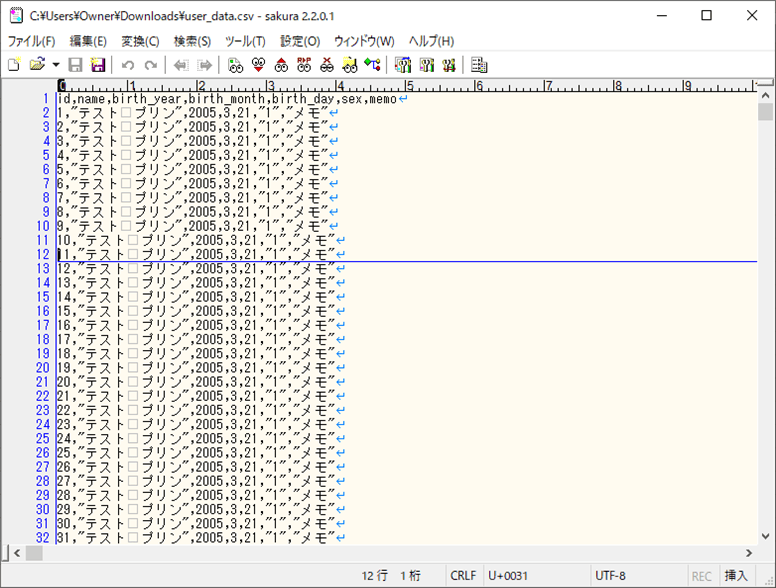
4) バッチ実行時のログ出力内容は以下の通りで、59769ms(約1分)で処理が完了していることが確認できる。
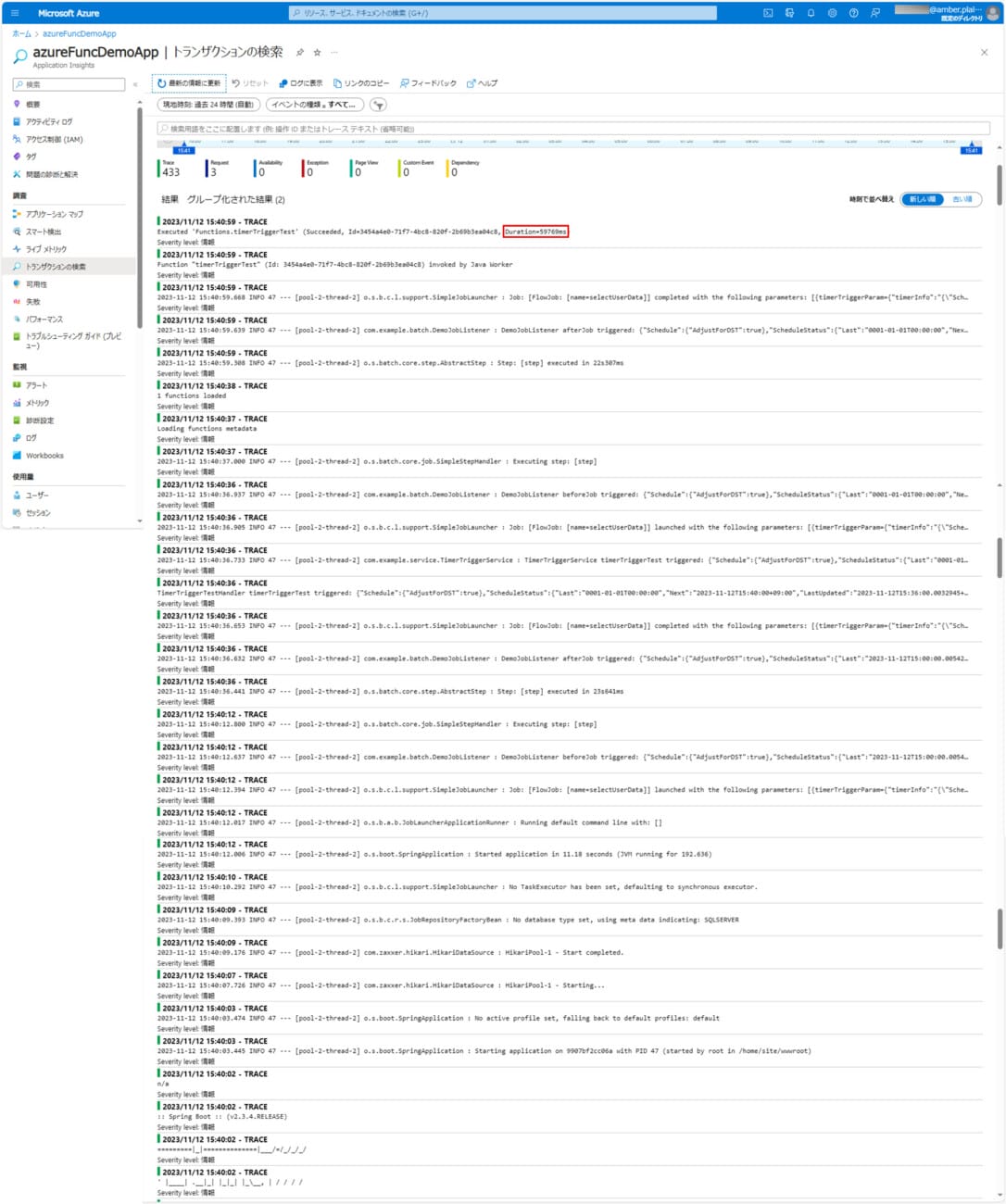
なお、上記ログの確認手順は、以下のサイトを参照のこと。

要点まとめ
- Spring Batchには、ChunkモデルとTaskletモデルがあるが、大量のデータを処理するには、Chunkモデルを利用するとよい。
- Spring BatchのChunkモデルを利用したバッチで、DBの(カラム数を7個持つ)テーブルデータ30万件を、Blob上のCSVファイルに出力する際の処理時間は1分程度となる。





