カイ二乗分布を利用して区間推定で母集団が正規分布に従う場合の母分散を求めてみた
以下の条件を満たす、母分散の95%信頼区間を考える。
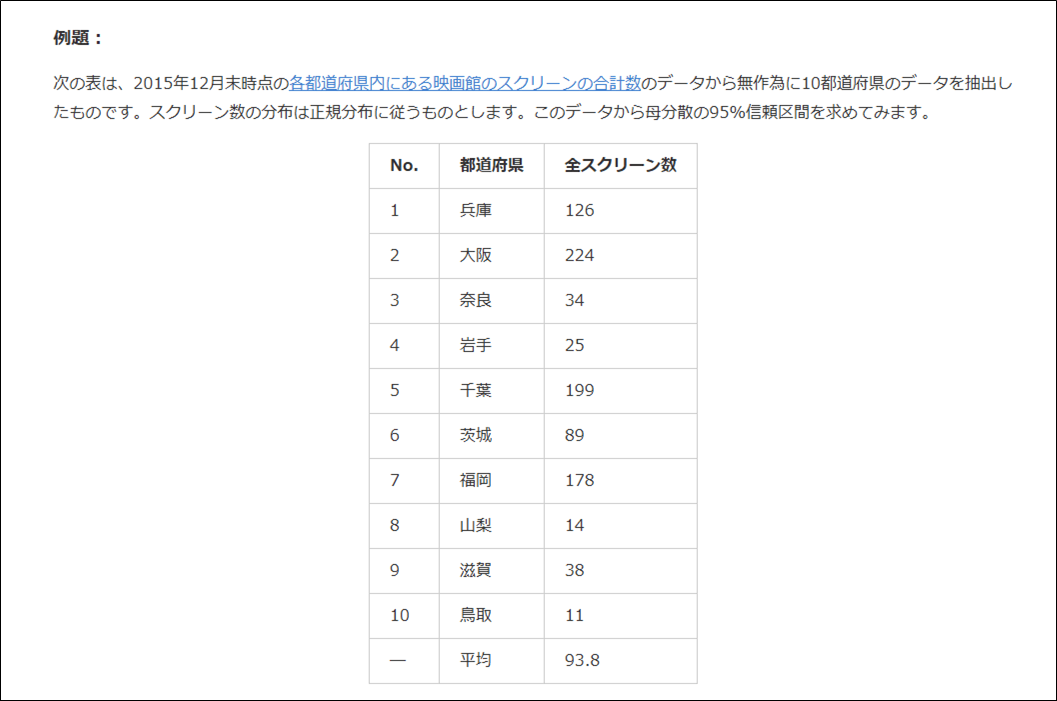
この問題を考えるにあたって、以下の性質を利用する。
- \(Z_1,Z_2,\cdots,Z_n\)は互いに独立で各\(i\)で\(Z_i~N(0,1)\)のとき、
\(X={Z_1}^2+{Z_2}^2+\cdots+{Z_n}^2\)で定義される確率変数\(X\)が従う分布を
自由度\(n\)のカイ二乗分布といい、\(χ^2(n)\)と表す。 - 確率変数\(X_1,X_2,\cdots,X_n\)は互いに独立で、平均\(μ\)、分散\(σ^2\)の正規分布に従う場合、標本平均との偏差の平方和は、自由度\(n-1\)の\(χ^2\)分布と呼ばれる分布に従うことが知られている。
これを式で表すと、標本不偏分散\(U^2=\displaystyle \frac{1}{n-1}\sum_{i=1}^{n} (X_i-\bar{X})^2\)を利用して、
\(\displaystyle \sum_{i=1}^{n} \frac{(X_i-\bar{X})^2}{σ^2}=\frac{(n-1)U^2}{σ^2}~χ^2(n-1)\)となる。
カイ二乗分布とグラフ
カイ二乗分布の確率密度関数は以下の通りで、自由度\(n\)を決めることで確率分布関数が決まるようになっている。

また、上記カイ二乗分布の確率密度関数で利用している\(Γ(s)\)はガンマ関数で、以下の式で定義される。

上記カイ二乗分布の確率密度関数の式は煩雑であるが、カイ二乗分布のグラフは、Scipyのstats.chi2.pdf関数を利用して描くことができる。例えば、自由度\(n=9\)の場合、カイ二乗分布のグラフを描画した結果は、以下の通り。
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
# 0~25までを1000等分した値をxとする
x = np.linspace(0, 25, 1000)
# 自由度nの値を定義
n = 9
# 自由度nのカイ二乗分布の値を計算し、グラフに描画
y = stats.chi2(n).pdf(x)
plt.plot(x, y)
plt.title(f"chi-square distribution graph(freedom {n})")
plt.xlabel("x", size=14)
plt.ylabel("y", size=14)
plt.grid()
plt.show()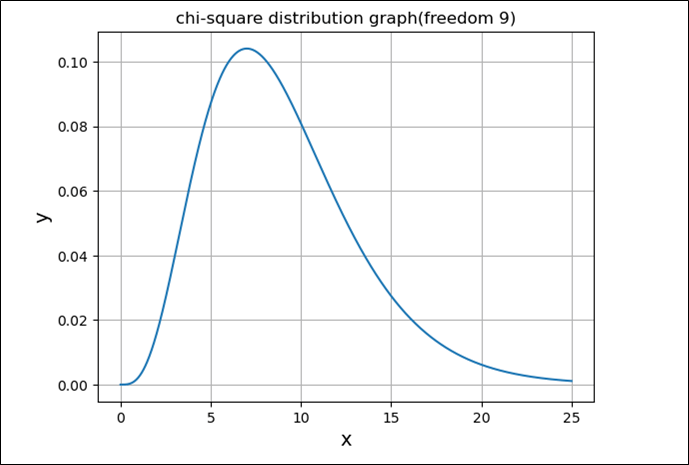
また、自由度\(n\)の値をいろいろ変えていった場合の、カイ二乗分布のグラフを描画した結果は、以下の通り。
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
# 0~25までを1000等分した値をxとする
x = np.linspace(0, 25, 1000)
# 自由度の値を定義
n_1 = 1
n_2 = 2
n_3 = 3
# 自由度nのカイ二乗分布の値を計算し、グラフに描画
y_1 = stats.chi2(n_1).pdf(x)
y_2 = stats.chi2(n_2).pdf(x)
y_3 = stats.chi2(n_3).pdf(x)
plt.plot(x, y_1, label=f"chi-squ dist(freedom {n_1})")
plt.plot(x, y_2, label=f"chi-squ dist(freedom {n_2})")
plt.plot(x, y_3, label=f"chi-squ dist(freedom {n_3})")
plt.title(f"chi-square distribution graph")
plt.xlabel("x", size=14)
plt.ylabel("y", size=14)
plt.legend()
plt.grid()
plt.show()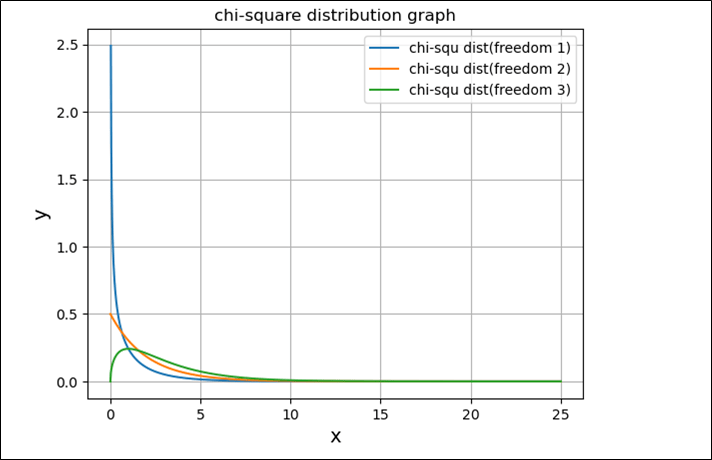
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
# 0~25までを1000等分した値をxとする
x = np.linspace(0, 25, 1000)
# 自由度の値を定義
#n_1 = 1
n_1 = 3
n_2 = 6
n_3 = 9
n_4 = 12
# 自由度nのカイ二乗分布の値を計算し、グラフに描画
y_1 = stats.chi2(n_1).pdf(x)
y_2 = stats.chi2(n_2).pdf(x)
y_3 = stats.chi2(n_3).pdf(x)
y_4 = stats.chi2(n_4).pdf(x)
plt.plot(x, y_1, label=f"chi-squ dist(freedom {n_1})")
plt.plot(x, y_2, label=f"chi-squ dist(freedom {n_2})")
plt.plot(x, y_3, label=f"chi-squ dist(freedom {n_3})")
plt.plot(x, y_4, label=f"chi-squ dist(freedom {n_4})")
plt.title(f"chi-square distribution graph")
plt.xlabel("x", size=14)
plt.ylabel("y", size=14)
plt.legend()
plt.grid()
plt.show()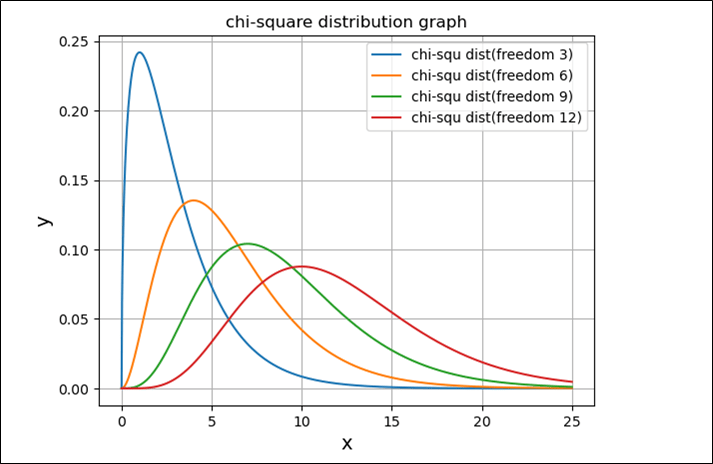

母分散の\(95\)%信頼区間の手動計算
この記事の冒頭に記載した例題の、母分散の\(95\)%信頼区間を計算した結果は、以下の通り。
\[
\begin{eqnarray}
\bar{X} &=& \displaystyle \frac{1}{n}\sum_{i=1}^{n}X_i = \frac{1}{10}\sum_{i=1}^{10}X_i \\
&=& \frac{1}{10}(126 + 224 + 34 + 25 + 199 + 89 + 178 + 14 + 38 + 11) \\
&=& \displaystyle \frac{1}{10} \times 938 = 93.8 \\
(n-1)U^2 &=& (n-1) \times \displaystyle \frac{1}{n-1}\sum_{i=1}^{n}\left(X_i – \bar{X} \right)^2 = \sum_{i=1}^{n}\left(X_i – \bar{X} \right)^2 \\
&=& \left(126 – 93.8 \right)^2 + \left(224 – 93.8 \right)^2 + \cdots + \left(11 – 93.8 \right)^2 \\
&=& 1036.84 + 16952.04 + \cdots + 6855.84 = 60815.6
\end{eqnarray}
\]
また、この計算を進めるにあたり、以下のカイ二乗分布表を利用する。
出所:カイ二乗分布表
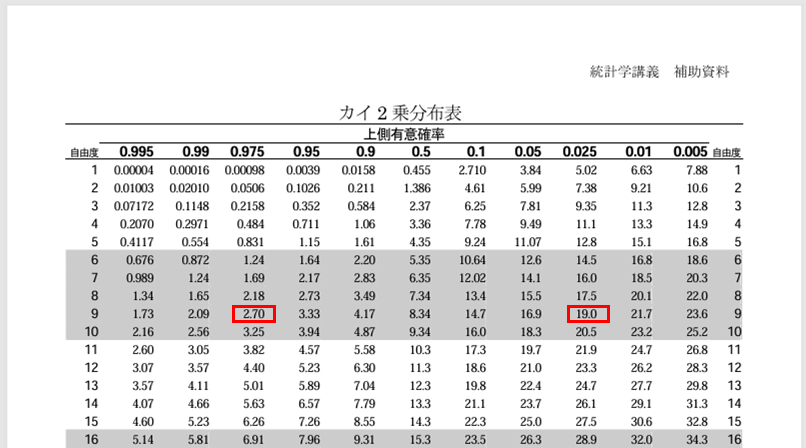
\(\displaystyle \frac{(n-1)U^2}{σ^2}\)が自由度\(n-1(=9)\)のカイ二乗分布において\(95\)%の範囲内に収まるようにするには、上記カイ二乗分布表より、\(2.70≦\displaystyle \frac{(n-1)U^2}{σ^2}≦19.0\)となればよいので、\((n-1)U^2=60815.6\)を代入し計算すると、以下のようになる。
\[
\begin{eqnarray}
2.70 &≦& \displaystyle \frac{60815.6}{σ^2} ≦ 19.0 \\
2.70σ^2 &≦& 60815.6 ≦ 19.0σ^2 \\
\displaystyle \frac{60815.6}{19.0} &≦& σ^2 ≦ \frac{60815.6}{2.70} \\
3200.821 &≦& σ^2 ≦ 22524.3
\end{eqnarray}
\]
上記計算を行い小数第二位を四捨五入すると、\(3200.8 ≦ σ^2 ≦ 22524.3\)となる。
母分散の\(95\)%信頼区間のプログラムによる計算
この記事の冒頭に記載した例題の、母分散の\(95\)%信頼区間を計算した結果をプログラムで計算した結果は、以下の通り。
import numpy as np
from scipy import stats
# 無作為に選択した10都道府県のデータ(標本)とそのデータ数を表示
sample_mean_list = [126, 224, 34, 25, 199, 89, 178, 14, 38, 11]
sample_mean_list_cnt = len(sample_mean_list)
print("*** 無作為に選択した10都道府県のデータとそのデータ数、与えられた母分散 ***")
print("無作為に選択した都道府県のデータ(標本):", sample_mean_list)
print(f"無作為に選択した都道府県のデータ(標本)のデータ数:{sample_mean_list_cnt}")
print()
# 無作為に選択した10都道府県のデータから、標本平均・不偏分散を算出
sample_mean_list_mean = np.mean(sample_mean_list)
sample_mean_list_unbiased_var = np.var(sample_mean_list, ddof=1)
print("*** 無作為に選択した10都道府県のデータから算出した、標本平均・不偏分散 ***")
print(f"標本平均:{sample_mean_list_mean}")
print(f"不偏分散:{sample_mean_list_unbiased_var}")
print()
# カイ二乗分布の自由度を算出
degree_of_freedom = sample_mean_list_cnt - 1
print("*** カイ二乗分布の自由度 ***")
print(degree_of_freedom)
print()
# 算出した自由度のカイ二乗分布に従う95%信頼区間の下限値と上限値を求める
chi2_low, chi2_up = stats.chi2.interval(confidence=0.95, df=degree_of_freedom)
print(f"*** 自由度{degree_of_freedom}のカイ二乗分布で95%信頼区間の下限値~上限値 ***")
print(f"下限値:{chi2_low}~上限値:{chi2_up}")
print()
# 算出した自由度のカイ二乗分布に従う95%信頼区間の母分散の下限値と上限値を求める
low = (sample_mean_list_cnt - 1) * sample_mean_list_unbiased_var / chi2_up
up = (sample_mean_list_cnt - 1) * sample_mean_list_unbiased_var / chi2_low
print(f"*** 自由度{degree_of_freedom}のカイ二乗分布に従う95%信頼区間の母分散の下限値~上限値 ***")
print(f"下限値:{low}~上限値:{up}")
print()
なお、手動計算した場合と\(95\)%信頼区間の母分散の下限値と上限値が異なっているのは、使用している自由度9のカイ二乗分布に従う\(95\)%信頼区間の下限値と上限値の値が、手動計算の時と異なっているためである。
要点まとめ
- \(Z_1,Z_2,\cdots,Z_n\)は互いに独立で各\(i\)で\(Z_i~N(0,1)\)のとき、
\(X={Z_1}^2+{Z_2}^2+\cdots+{Z_n}^2\)で定義される確率変数\(X\)が従う分布を
自由度\(n\)のカイ二乗分布といい、\(χ^2(n)\)と表す。 - 確率変数\(X_1,X_2,\cdots,X_n\)は互いに独立で、平均\(μ\)、分散\(σ^2\)の正規分布に従う場合、標本平均との偏差の平方和は、自由度\(n-1\)の\(χ^2\)分布と呼ばれる分布に従うことが知られている。
これを式で表すと、標本不偏分散\(U^2=\displaystyle \frac{1}{n-1}\sum_{i=1}^{n} (X_i-\bar{X})^2\)を利用して、
\(\displaystyle \sum_{i=1}^{n} \frac{(X_i-\bar{X})^2}{σ^2}=\frac{(n-1)U^2}{σ^2}~χ^2(n-1)\)となる。 - 母分散の\(95\)%信頼区間を計算するには、自由度\(n-1\)のカイ二乗分布の上側\(0.975,0.025\)である値\(α,β\)を読み取り、\(\displaystyle \frac{(n-1)U^2}{σ^2}\)が\(α\)以上\(β\)以下の範囲に収まる\(σ^2\)を計算すればよい。





