Pythonでデータの取り込みや加工・集計、分析処理に利用できるライブラリの一つにPandasがあり、これを利用すると、SQLのSelect文に該当する、データ抽出・列選択・ソート・グループ化を行える。
今回は、Pandasを利用してSQLのSelect文に該当する処理を実行してみたので、そのサンプルプログラムを共有する。
前提条件
下記記事の、Pandasを利用したOracle DBのデータ取得ができていること。

Pandasを利用してOracle DBのデータを取得してみたPythonでデータの取り込みや加工・集計、分析処理に利用できるライブラリの一つにPandasがあり、これを利用するとCSVファイルの読...
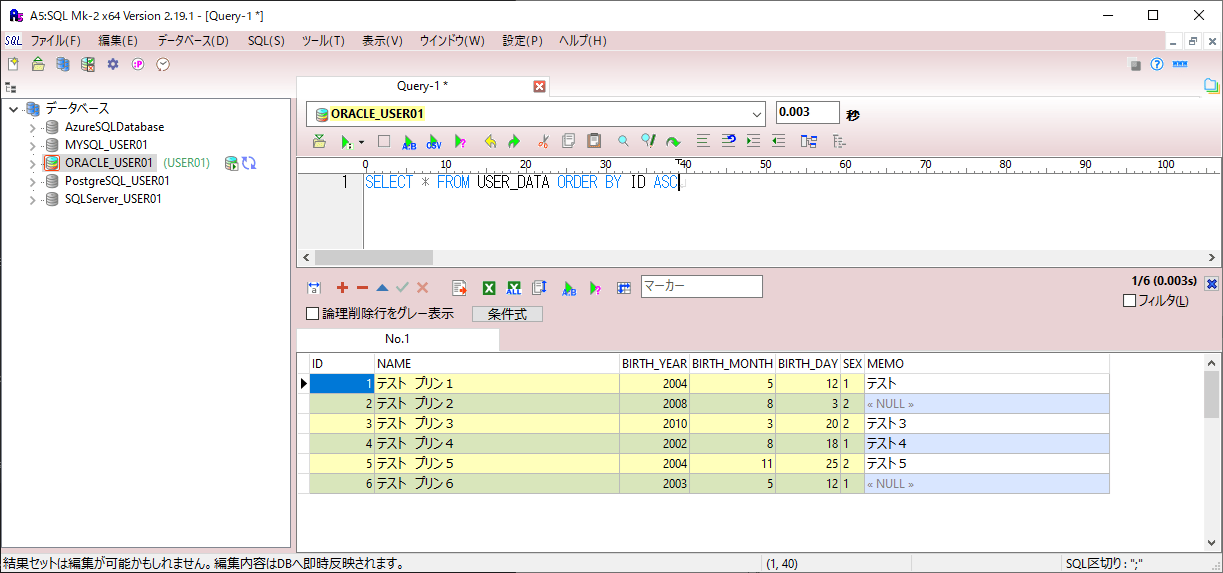
また、USER_DATAテーブルに、以下のデータが作成されていること。

Androidロックを解除する裏ワザ「4uKey for Android」をご紹介Android端末では、以下の画像のような画面ロックパスワードを設定することができますが、このパスワードを忘れてしまうと、Android...
サンプルプログラムの作成と実行結果
Pandasでデータ抽出・列選択・ソート・グループ化するサンプルプログラムの内容と実行結果は、それぞれ以下の通り。
1) 前提条件のUSER_DATAテーブルのデータを取得するプログラムとその実行結果は、以下の通りとなる。
import oracledb
import pandas as pd
from sqlalchemy.engine.url import URL
from sqlalchemy.engine.create import create_engine
from IPython.display import display
# OracleDBへの接続情報
oracle_user = "USER01"
oracle_passwd = "USER01"
oracle_hostname = "localhost"
oracle_sid = "xe"
# OracleDBへの接続URLを生成
oracle_url = URL.create(
drivername='oracle+cx_oracle',
username=oracle_user,
password=oracle_passwd,
host=oracle_hostname,
database=oracle_sid
)
# OracleDBを初期化
oracledb.init_oracle_client()
# SQLAlchemyを使ってOracleDBに接続する際のエンジンを定義
engine = create_engine(oracle_url)
# SELECT文を定義
sql_query = "SELECT * FROM USER_DATA ORDER BY ID ASC"
print("*** 実行SQL ***")
print(sql_query)
# SELECT文を実行し、DataFrame(df)に格納
df = pd.read_sql(sql_query, con=engine)
display(df)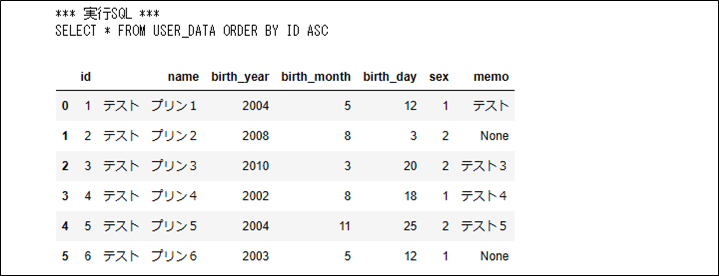
2) 1)の取得データを、条件を絞って表示するプログラムとその実行結果は、以下の通りとなる。
from IPython.display import display
# DataSet(df)を、sex='1'のデータに絞って表示
df1 = df.query('sex == "1"')
print("*** df1(sex='1') ***")
display(df1)
print()
# DataSet(df)を、sex='1'かつmemo≠Noneのデータに絞って表示
df2 = df.query('sex == "1" and memo.notna()')
print("*** df2(sex='1' and memo≠None) ***")
display(df2)
print()
# DataSet(df)を、sex='1'またはmemo=Noneまたはid=5のデータに絞って表示
df3 = df.query('sex == "1" or memo.isna() or id == 5')
print("*** df3(sex='1' or memo=None or id=5) ***")
display(df3)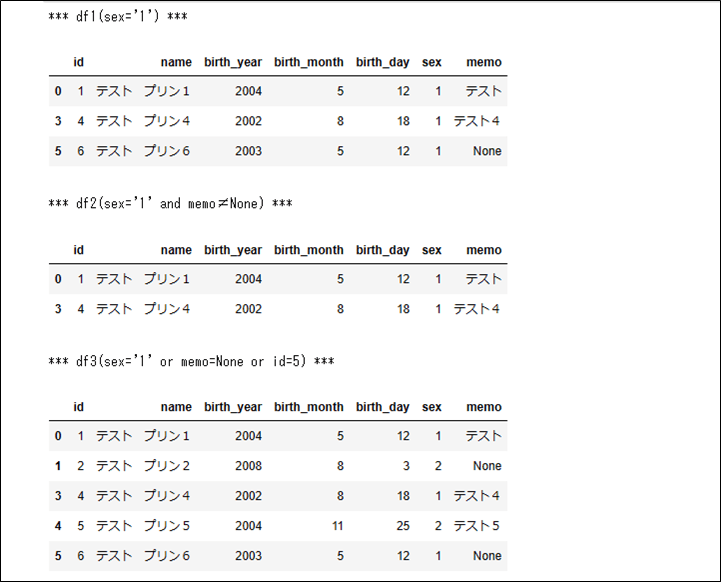
3) 1)の取得データを、カラム指定して表示するプログラムとその実行結果は、以下の通りとなる。
from IPython.display import display
# DataSet(df)から、id,nameのみを抽出し表示
df4 = df.loc[:, ['id','name']]
print("*** df4(id,nameのみを抽出) ***")
display(df4)
print()
# DataSet(df)から、memo以外の項目を抽出し表示
df5 = df.copy()
df5 = df5.drop(['memo'], axis=1)
print("*** df5(memo以外の全項目を抽出) ***")
display(df5)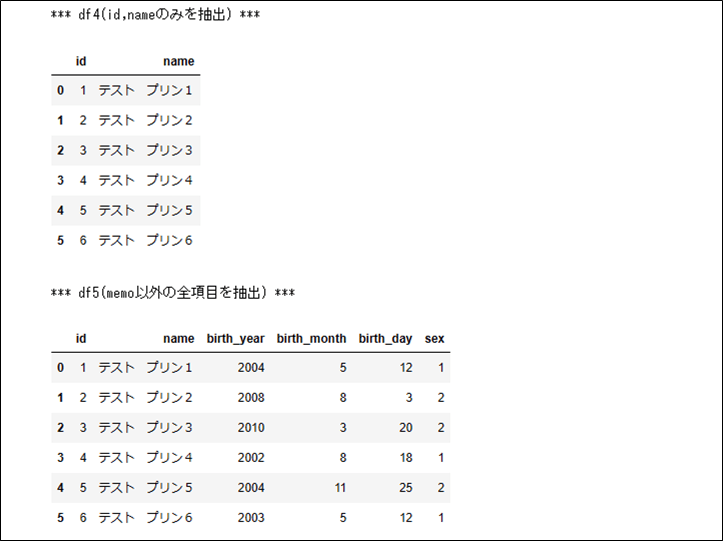
4) 1)の取得データを、ソート・グループ化して表示するプログラムとその実行結果は、以下の通りとなる。
from IPython.display import display
# DataSet(df)を、birth_year, birth_month, birth_dayそれぞれの降順に表示
df6 = df.copy()
df6 = df6.sort_values(by=['birth_year', 'birth_month', 'birth_day']
, ascending=[False, False, False])
print("*** df6(birth_year, birth_month, birth_dayそれぞれの降順にソート) ***")
display(df6)
print()
# DataSet(df)から、sex毎の件数を表示
df7 = df.copy()
df7['count'] = 1
df7 = df7.loc[:, ['sex','count']].groupby('sex').count()
print("*** df7(sex毎の件数を表示) ***")
display(df7)
print()
print("*** value_counts()を利用してsex毎の件数を表示 ***")
df["sex"].value_counts()
要点まとめ
- Pandasを利用すると、CSV読み込みやデータ加工に加え、SQLのSelect文に該当するデータ抽出・列選択・ソート・グループ化を行うことができる。





