重回帰分析を行うデータを読み込んでみた
以下の「カリフォルニアの住宅価格データ」で、所得・築年数・部屋数・寝室数・人口・世帯人数・緯度・経度を元に、住宅価格を決めるモデルを考える。
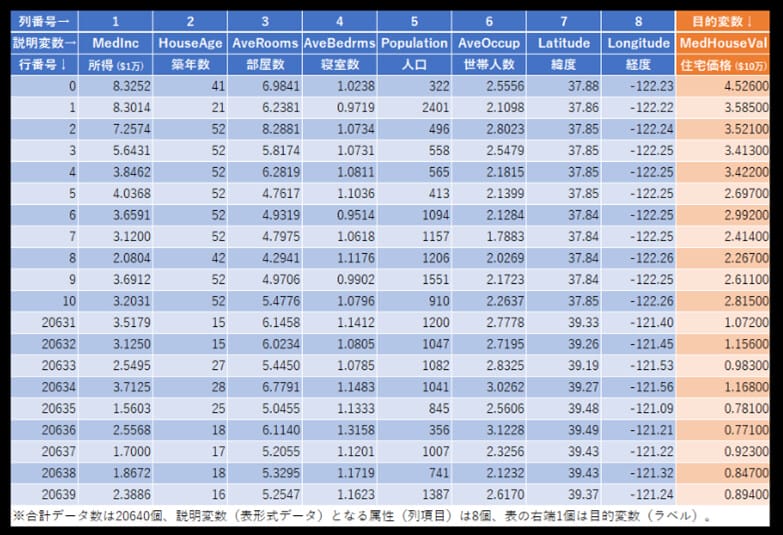
上記データは、代表的な機械学習フレームワークであるscikit-learnのデータセットに含まれているため、これをPythonで読み込むことができる。その結果は、以下の通り。
from sklearn.datasets import fetch_california_housing
# カリフォルニアの住宅価格データセットを取得
housing = fetch_california_housing()
print("*** データの構造 ***")
print(housing.feature_names)
print("*** 結果の構造 ***")
print(housing.target_names)
print()
print("*** データ、結果の要素数 ***")
print("データの要素数:" + str(len(housing.data)))
print("結果の要素数:" + str(len(housing.target)))
print()
print("*** データ、結果の型 ***")
print("データの型:" + str(type(housing.data)))
print("結果の型:" + str(type(housing.target)))
print()
print("*** 先頭5件のデータ ***")
print(housing.data[0:5])
print("*** 先頭5件の結果 ***")
print(housing.target[0:5])
上記結果を確認すると、「先頭5件のデータ」が分かりにくいため、表示形式を変更して表示する。その結果は、以下の通り。
import numpy as np
from sklearn.datasets import fetch_california_housing
# カリフォルニアの住宅価格データセットを取得
housing = fetch_california_housing()
print("*** データの構造 ***")
print(housing.feature_names)
print("*** 結果の構造 ***")
print(housing.target_names)
print()
print("*** データ、結果の要素数 ***")
print("データの要素数:" + str(len(housing.data)))
print("結果の要素数:" + str(len(housing.target)))
print()
print("*** データ、結果の型 ***")
print("データの型:" + str(type(housing.data)))
print("結果の型:" + str(type(housing.target)))
print()
# print(data)を表示する際、小数点以下3桁まで+指数表記しない形式に設定
np.set_printoptions(precision=3, suppress=True)
print("*** 先頭5件のデータ ***")
print(housing.data[0:5])
print("*** 先頭5件の結果 ***")
print(housing.target[0:5])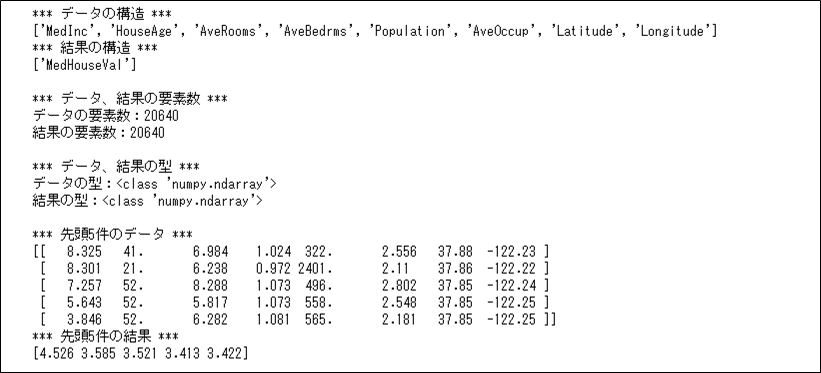

例えば先頭行のデータの場合、\(x_{11}\)(MedInc(所得))=\(8.325\)、\(x_{12}\)(HouseAge(築年数))=\(41.0\)、\(x_{13}\)(AveRooms(部屋数))=\(6.984\)、\(x_{14}\)(AveBedrms(寝室数))=\(1.024\)、\(x_{15}\)(Population(人口))=\(322.0\)、\(x_{16}\)(AveOccup(世帯人数))=\(2.556\)、\(x_{17}\)(Latitude(緯度))=\(37.88\)、\(x_{18}\)(Longitude(経度))=\(-122.23\)で、\(y_{1}\)(MedHouseVal(住宅価格))=\(4.526\)と読み取れる。
ここで、上記\(x_{11}\)~\(x_{18}\)を利用し、各係数の重みを\(w_{1}\)~\(w_{8}\)、バイアスを\(b\)とすると、\(y_{1}\)(MedHouseVal(住宅価格))の予測値\(\hat y_{1}\)は、以下の重回帰式で表現できる。
\[
\begin{eqnarray}
\hat y_{1} &=& w_{1}x_{11} + w_{2}x_{12} + w_{3}x_{13} + w_{4}x_{14} + w_{5}x_{15} + w_{6}x_{16} + w_{7}x_{17} + w_{8}x_{18} + b \\
&=& w_{1}x_{11} + w_{2}x_{12} + \ldots + w_{8}x_{18} + b
\end{eqnarray}
\]
また、\(b = w_{0} \times 1 = w_{0}x_{10}\) と定義すると、以下のように式変形できる。
\[
\begin{eqnarray}
\hat y_{1} &=& w_{1}x_{11} + w_{2}x_{12} + \ldots + w_{8}x_{18} + w_{0}x_{10} \\
&=& w_{0}x_{10} + w_{1}x_{11} + w_{2}x_{12} + \ldots + w_{8}x_{18} \\
&=& x_{10}w_{0} + x_{11}w_{1} + x_{12}w_{2} + \ldots + x_{18}w_{8} \\
&=& \begin{pmatrix} x_{10} & x_{11} & x_{12} & \ldots & x_{18} \end{pmatrix} \begin{pmatrix} w_{0} \\ w_{1} \\ w_{2} \\ \vdots \\ w_{8} \end{pmatrix}
= {}^t \! \boldsymbol x \boldsymbol w
\end{eqnarray}
\]
先頭5件分のデータから、上記式の( \(x_{i0} x_{i1} x_{i2} ・・・ x_{i8}\) ) (\(i=1~5\)、\(x_{i0}=1\))の部分を抜き出した結果は、以下の通り。
import numpy as np
import pandas as pd
from sklearn.datasets import fetch_california_housing
# カリフォルニアの住宅価格データセットを取得
housing = fetch_california_housing()
# print(data)を表示する際、小数点以下3桁まで+指数表記しない形式に設定
np.set_printoptions(precision=3, suppress=True)
# 先頭5件のデータをXとする
X = housing.data[0:5]
print("*** 先頭5件のデータ(Numpy.ndarray) ***")
print(X)
print()
# Xの先頭にバイアス(1)を追加するため、DataFrameに変換
Xdf = pd.DataFrame(X, columns=housing.feature_names)
print("*** 先頭5件のデータ(DataFrame) ***")
print(Xdf)
print()
# Xの先頭にバイアス(1)を追加
Xdf.insert(0, 'bias', 1)
print("*** バイアス追加後の先頭5件のデータ(DataFrame) ***")
print(Xdf)
print()
# 先頭5件のデータをNumpy.ndarrayに変換
X = Xdf.values
print("*** バイアス追加後の先頭5件のデータ(Numpy.ndarray) ***")
print(X)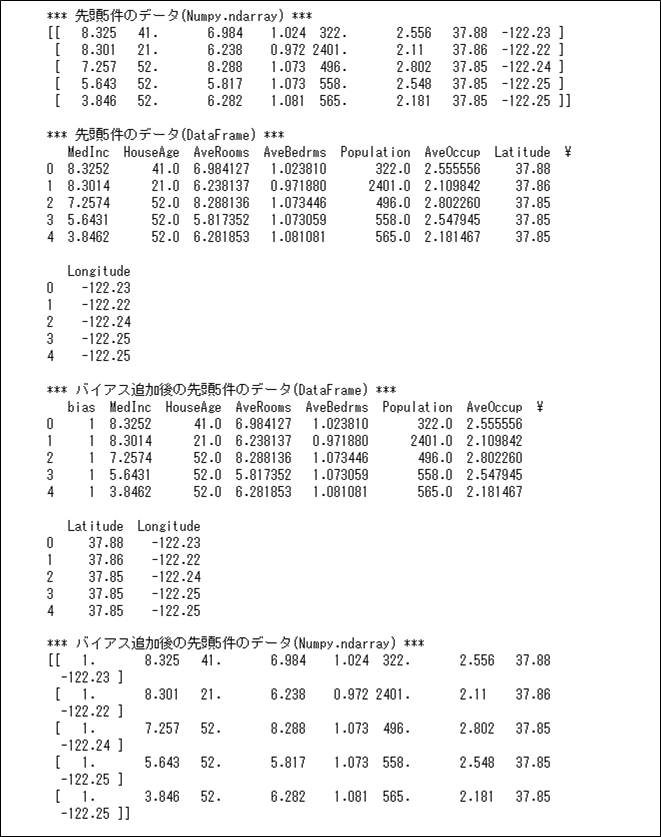
要点まとめ
- カリフォルニアの住宅価格データは、代表的な機械学習フレームワークであるscikit-learnのデータセットに含まれているため、これをPythonで読み込むことができる。





