データ分析や機械学習のためのライブラリの一つであるscikit-learnには、評価モデルを作成後、正答率・適合率・再現率・F値等の評価指標を出力する機能がある。
今回は、決定木分析やロジスティクス回帰分析のモデルの評価指標を出力してみたので、そのサンプルプログラムを共有する。
なお、決定木分析やロジスティクス回帰分析を利用したモデルについては、以下の記事も参照のこと。


決定木分析で、max_depth=2の場合に、正答率・適合率・再現率・F値等の評価指標を出力した結果は、以下の通り。
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn import metrics
# アヤメのデータセットのデータを取得
iris = load_iris()
# 先頭51~55件目のデータ(versicolor)と、先頭101~105件目のデータ(virginica)の
# データを結合し、Xに格納
X = np.append(iris.data[50:100], iris.data[100:150], axis=0)
# 先頭51~55件目の結果(versicolor)と、先頭101~105件目の結果(virginica)の
# データを結合し、yに格納
y = np.append(iris.target[50:100], iris.target[100:150], axis=0)
# 訓練用データとテスト用データに分割
X_train, X_test, y_train, y_test \
= train_test_split(X, y, test_size=0.2, random_state=0)
# scikit-learnのDecisionTreeClassifierに適用
dtc = DecisionTreeClassifier(max_depth=2, random_state=0)
dtc.fit(X_train, y_train)
# テスト用データで検証
print("*** テスト用データの結果 ***")
print(y_test)
print("*** テスト用データから、作成済モデルで算出した結果 ***")
pred_test = dtc.predict(X_test)
print(pred_test)
print()
# 正答率を算出
print("*** 正答率 ***")
print(dtc.score(X_test, y_test))
print()
# 評価指標をまとめて出力
# precision:適合率、recall:再現率、f1-score:f1スコア、support:正解データ数
print("*** 評価指標 ***")
print(metrics.classification_report(y_test, pred_test))
print()
# 混合行列を出力
print("*** 混合行列 ***")
print(metrics.confusion_matrix(y_test, pred_test))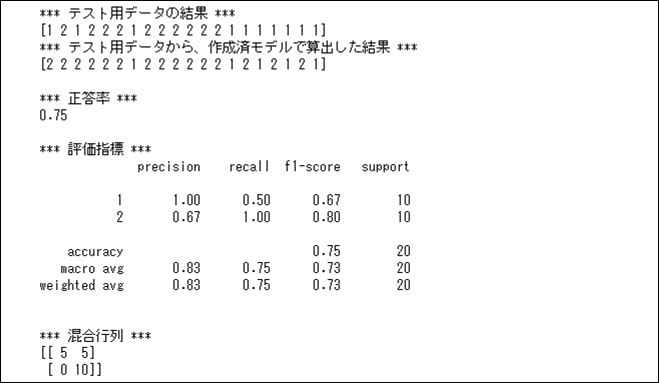
正答率および評価指標のaccuracyは、作成済モデルで算出した結果が、テスト用データの結果と一致する割合を計算したもので、\(\displaystyle \frac{15}{20}=0.75\) と計算される。
また、評価指標のprecision(適合率)は、予測した中で正解した割合を計算したもので、結果\(=1\)の場合は\(\displaystyle \frac{5}{5}=1.0\)、結果\(=2\)の場合は\(\displaystyle \frac{10}{15}≒0.67\) と計算される。
さらに、評価指標のrecall(再現率)は、テスト用データの中から正解した割合を計算したもので、結果\(=1\)の場合は\(\displaystyle \frac{5}{10}=0.5\)、結果\(=2\)の場合は\(\displaystyle \frac{10}{10}=1.0\) と計算される。
また、評価指標のf1-score(F値)は、適合率と再現率の調和平均で、結果\(=1\)の場合は\(\displaystyle \frac{2 \times 1 \times 0.5}{1+0.5}≒0.67\)、結果\(=2\)の場合は\(\displaystyle \frac{2 \times \displaystyle \frac{10}{15} \times 1}{\displaystyle \frac{10}{15}+1}=0.8\) と計算される。
さらに、評価指標のsupportは正解データの個数で、結果\(=1\)と結果\(=2\)の場合のいずれも、\(10\)となる。
その他の評価指標や混合行列については、以下のサイトを参照のこと。
https://note.nkmk.me/python-sklearn-confusion-matrix-score/

同様の決定木分析で、max_depth=4の場合に、正答率・適合率・再現率等の評価指標を出力した結果は以下の通りで、正答率が少し上昇していることが確認できる。
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn import metrics
# アヤメのデータセットのデータを取得
iris = load_iris()
# 先頭51~55件目のデータ(versicolor)と、先頭101~105件目のデータ(virginica)の
# データを結合し、Xに格納
X = np.append(iris.data[50:100], iris.data[100:150], axis=0)
# 先頭51~55件目の結果(versicolor)と、先頭101~105件目の結果(virginica)の
# データを結合し、yに格納
y = np.append(iris.target[50:100], iris.target[100:150], axis=0)
# 訓練用データとテスト用データに分割
X_train, X_test, y_train, y_test \
= train_test_split(X, y, test_size=0.2, random_state=0)
# scikit-learnのDecisionTreeClassifierに適用
dtc = DecisionTreeClassifier(max_depth=4, random_state=0)
dtc.fit(X_train, y_train)
# テスト用データで検証
print("*** テスト用データの結果 ***")
print(y_test)
print("*** テスト用データから、作成済モデルで算出した結果 ***")
pred_test = dtc.predict(X_test)
print(pred_test)
print()
# 正答率を算出
print("*** 正答率 ***")
print(dtc.score(X_test, y_test))
print()
# 評価指標をまとめて出力
# precision:適合率、recall:再現率、f1-score:f1スコア、support:正解データ数
print("*** 評価指標 ***")
print(metrics.classification_report(y_test, pred_test))
print()
# 混合行列を出力
print("*** 混合行列 ***")
print(metrics.confusion_matrix(y_test, pred_test))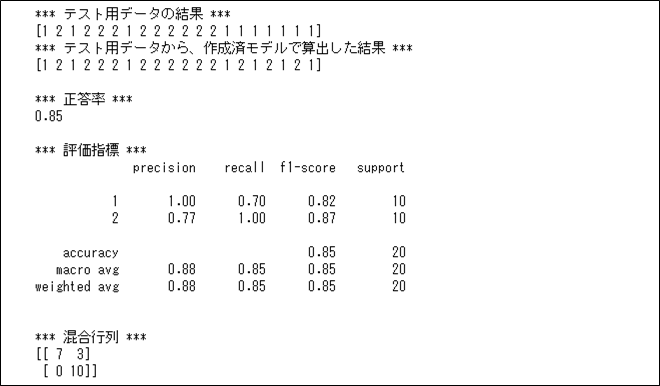
また、ロジスティクス回帰分析で、正答率・適合率・再現率等の評価指標を出力した結果は以下の通りで、90%の正答率になっていることが確認できる。
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
# アヤメのデータセットのデータを取得
iris = load_iris()
# 先頭51~55件目のデータ(versicolor)と、先頭101~105件目のデータ(virginica)の
# データを結合し、Xに格納
X = np.append(iris.data[50:100], iris.data[100:150], axis=0)
# 先頭51~55件目の結果(versicolor)と、先頭101~105件目の結果(virginica)の
# データを結合し、yに格納
y = np.append(iris.target[50:100], iris.target[100:150], axis=0)
# 訓練用データとテスト用データに分割
X_train, X_test, y_train, y_test = \
train_test_split(X, y, test_size=0.2, random_state=0)
# scikit-learnのLogisticRegressionに適用
lr = LogisticRegression()
lr.fit(X_train, y_train)
# テスト用データで検証
print("*** テスト用データの結果 ***")
print(y_test)
print("*** テスト用データから、作成済モデルで算出した結果 ***")
pred_test = lr.predict(X_test)
print(pred_test)
print()
# 正答率を算出
print("*** 正答率 ***")
print(lr.score(X_test, y_test))
print()
# 評価指標をまとめて出力
# precision:適合率、recall:再現率、f1-score:f1スコア、support:正解データ数
print("*** 評価指標 ***")
print(metrics.classification_report(y_test, pred_test))
print()
# 混合行列を出力
print("*** 混合行列 ***")
print(metrics.confusion_matrix(y_test, pred_test))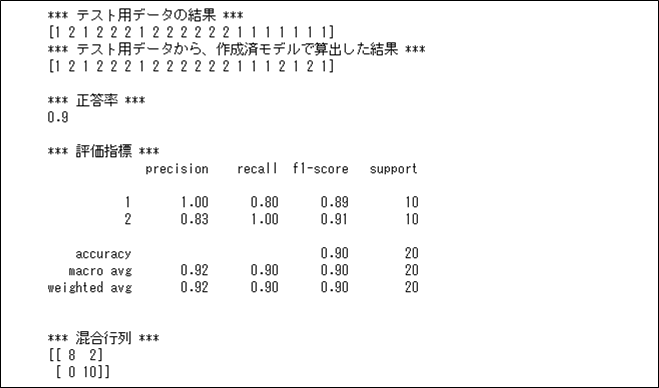
要点まとめ
- データ分析や機械学習のためのライブラリの一つであるscikit-learnには、評価モデルを作成後、正答率・適合率・再現率・F値等の評価指標を出力する機能がある。





