DecisionTreeClassifierクラスを用いて2値分類をしてみた
以下の記事で、ロジスティック回帰分析によって、アヤメがvirginicaであるかどうかを分類していた。

LogisticRegressionクラスを用いてロジスティクス回帰分析の尤度関数の最適解を算出してみた 以下の記事で、ロジスティック回帰分析に従う、アヤメがvirginicaである確率\(p\)の計算式を算出してきた。 https...
同様の分類を行う手法には、ロジスティック回帰分析以外にも存在し、その1つに決定木分析がある。
決定木分析とは、木構造(樹形図)を用いてデータを分析する手法で、データ分析や機械学習のためのライブラリの一つであるscikit-learnに含まれている。
今回は、scikit-learnのDecisionTreeClassifierクラスを用いて、アヤメがvirginicaかどうか判定してみたので、そのサンプルプログラムを共有する。
DecisionTreeClassifierクラスを用いて、アヤメがvirginicaかどうかを判定した結果は以下の通りで、正常に判定できていることが確認できる。
import numpy as np
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
# アヤメのデータセットのデータを取得
iris = load_iris()
# 先頭51~55件目のデータ(versicolor)と、先頭101~105件目のデータ(virginica)の
# データを結合し、X1に格納
X1 = np.append(iris.data[50:55], iris.data[100:105], axis=0)
print("*** 結合した先頭51~55件目と先頭101~105件目のデータ ***")
print(X1)
print()
# 先頭51~55件目のデータ(versicolor)と、先頭101~105件目のデータ(virginica)の
# データを結合し、petal length(cm), petal width(cm)のみ抽出したデータをX2に格納
X2 = np.append(iris.data[50:55, -2:], iris.data[100:105, -2:], axis=0)
print("*** 結合した先頭51~55件目と先頭101~105件目のデータ ***")
print("*** petal length(cm), petal width(cm)のみ抽出 ***")
print(X2)
print()
# 先頭51~55件目の結果(versicolor)と、先頭101~105件目の結果(virginica)の
# データを結合し、yに格納
y = np.append(iris.target[50:55], iris.target[100:105], axis=0)
# 先頭51~55件目と先頭101~105件目の結果
print("*** 先頭51~55件目の結果 ***")
print(iris.target[50:55])
print("*** 先頭101~105件目の結果 ***")
print(iris.target[100:105])
print()
# scikit-learnのDecisionTreeClassifierに適用
dtc = DecisionTreeClassifier(max_depth=2, random_state=0)
dtc.fit(X2, y)
# DecisionTreeClassifierによる算出結果
print("*** petal length(cm), petal width(cm)のみ抽出したデータからの判定 ***")
print("*** 先頭51~55件目のデータから判定した結果 ***")
print(dtc.predict(iris.data[50:55, -2:]))
print("*** 先頭101~105件目のデータから判定した結果 ***")
print(dtc.predict(iris.data[100:105, -2:]))
また、上記DecisionTreeClassifierクラスのモデルを利用した場合の木構造を表示した結果は、以下の通り。
import numpy as np from sklearn.datasets import load_iris from sklearn.tree import DecisionTreeClassifier import sklearn.tree # アヤメのデータセットのデータを取得 iris = load_iris() # 先頭51~55件目のデータ(versicolor)と、先頭101~105件目のデータ(virginica)の # データを結合し、petal length(cm), petal width(cm)のみ抽出したデータをXに格納 X = np.append(iris.data[50:55, -2:], iris.data[100:105, -2:], axis=0) # 先頭51~55件目の結果(versicolor)と、先頭101~105件目の結果(virginica)の # データを結合し、yに格納 y = np.append(iris.target[50:55], iris.target[100:105], axis=0) # scikit-learnのDecisionTreeClassifierに適用 dtc = DecisionTreeClassifier(max_depth=2, random_state=0) dtc.fit(X, y) # 決定木を可視化 # 第1引数:モデル名、第2引数:クラス名、第3引数:色付きで表示するか sklearn.tree.plot_tree(dtc, class_names=['versicolor', 'virginica'], filled=True)


「DroidKit」はAndroid端末のデータ復元や画面ロック解除等が行える便利なツールだった「DroidKit」は、画面ロック解除、FRPバイパス、データ復元、システム修復、および4つのより効果的なツールを含んでいて、ほぼすべて...
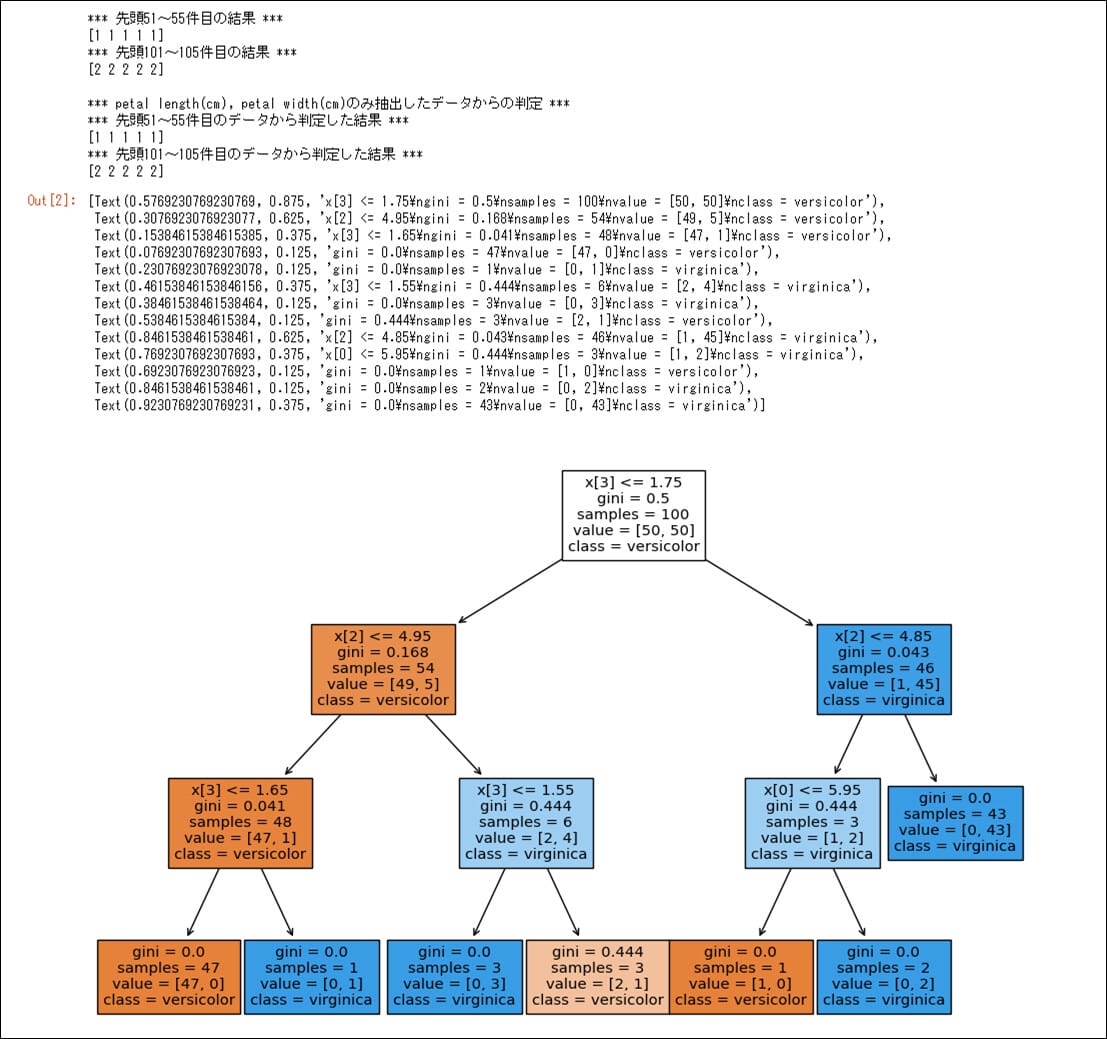
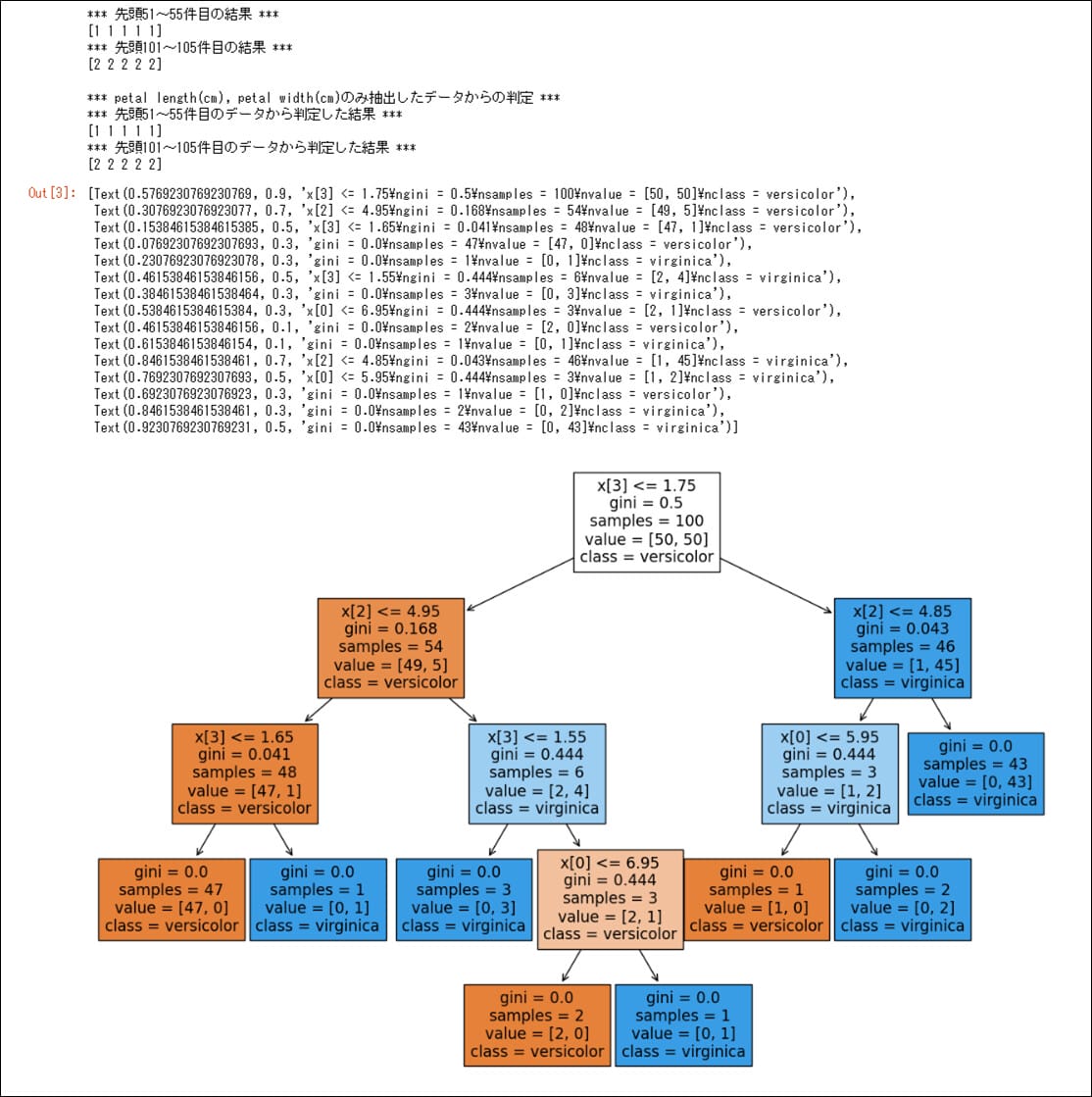
さらに、DecisionTreeClassifierクラスのmax_depthによって、作成される木構造の構造(深さ)が異なる。その結果を確認した内容は、以下の通り。
%matplotlib inline
import numpy as np
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pyplot as plt
import sklearn.tree
# 実行時に使用する定数を定義
# MAX_DEPTH=2の場合、FIGSIZE_X=9、FIGSIZE_Y=6を指定
# MAX_DEPTH=3の場合、FIGSIZE_X=12、FIGSIZE_Y=8を指定
# MAX_DEPTH=4の場合、FIGSIZE_X=15、FIGSIZE_Y=10を指定
MAX_DEPTH = 2
FIGSIZE_X = 9
FIGSIZE_Y = 6
# アヤメのデータセットのデータを取得
iris = load_iris()
# 先頭51~55件目のデータ(versicolor)と、先頭101~105件目のデータ(virginica)の
# データを結合し、Xに格納
X = np.append(iris.data[50:100], iris.data[100:150], axis=0)
# 先頭51~55件目の結果(versicolor)と、先頭101~105件目の結果(virginica)の
# データを結合し、yに格納
y = np.append(iris.target[50:100], iris.target[100:150], axis=0)
print("*** 先頭51~55件目の結果 ***")
print(iris.target[50:55])
print("*** 先頭101~105件目の結果 ***")
print(iris.target[100:105])
print()
# scikit-learnのDecisionTreeClassifierに適用
dtc = DecisionTreeClassifier(max_depth=MAX_DEPTH, random_state=0)
dtc.fit(X, y)
# DecisionTreeClassifierによる算出結果
print("*** petal length(cm), petal width(cm)のみ抽出したデータからの判定 ***")
print("*** 先頭51~55件目のデータから判定した結果 ***")
print(dtc.predict(iris.data[50:55]))
print("*** 先頭101~105件目のデータから判定した結果 ***")
print(dtc.predict(iris.data[100:105]))
# 決定木を可視化
# 画像の表示サイズを変更
plt.figure(figsize=(FIGSIZE_X, FIGSIZE_Y))
# 第1引数:モデル名、第2引数:クラス名、第3引数:色付きで表示するか
sklearn.tree.plot_tree(dtc, class_names=['versicolor', 'virginica'], filled=True)●実行結果(max_depth=2の場合)
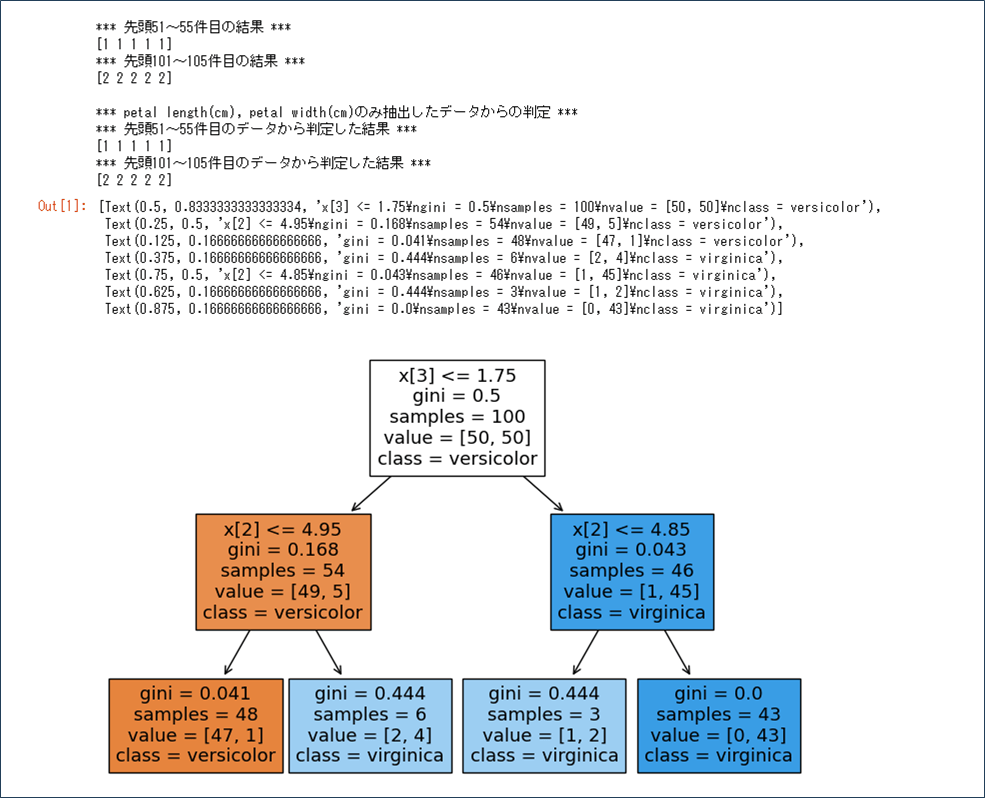
●実行結果(max_depth=3の場合)
●実行結果(max_depth=4の場合)
要点まとめ
- 決定木分析とは、木構造(樹形図)を用いてデータを分析する手法で、ロジスティック回帰分析のような2値分類に利用できる。
- 決定木分析を行うライブラリは、データ分析や機械学習のためのライブラリの一つであるscikit-learnに含まれていて、DecisionTreeClassifierクラスを利用して実施できる。
- 決定木の深さは、DecisionTreeClassifierクラスのmax_depthで指定する。





