SQLのWHERE句でインデックスを利用して検索すると、インデックスを利用しない場合に比べて、処理が速くなることが多い。
今回は、WHERE句内でインデックスを利用した場合と利用しなかった場合それぞれで、SQLの実行速度を測定するプログラムを作成してみたので、共有する。
なお、SQL文の性能改善を行う方法については、以下のサイトを参照のこと。
https://sites.google.com/site/orapeform/sql_minaoshi
前提条件
下記記事の実装が完了していること。

インデックスの追加
USER_DATAテーブルのnameに、インデックスを追加する。その手順は、以下の通り。
1) USER_DATAテーブルのnameにインデックスを追加する前に、USER_DATAテーブルに設定されているインデックスを確認すると、以下のように、USER_DATAテーブルのidに主キーが設定されていることが確認できる。
SELECT ui.INDEX_NAME, ui.INDEX_TYPE, uc.CONSTRAINT_TYPE
, ui.TABLE_NAME, ui.UNIQUENESS, uic.COLUMN_NAME, ui.STATUS
FROM USER_INDEXES ui
INNER JOIN USER_IND_COLUMNS uic ON ui.INDEX_NAME = uic.INDEX_NAME
LEFT JOIN USER_CONSTRAINTS uc ON ui.INDEX_NAME = uc.CONSTRAINT_NAME
WHERE ui.TABLE_NAME = 'USER_DATA'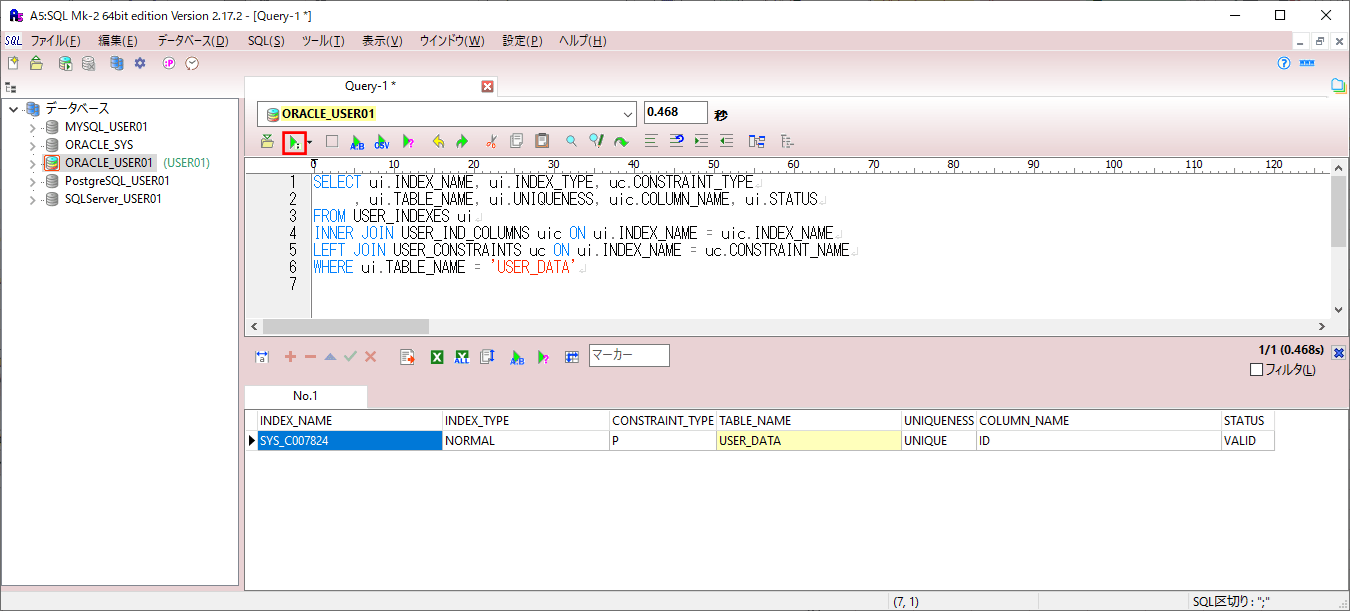
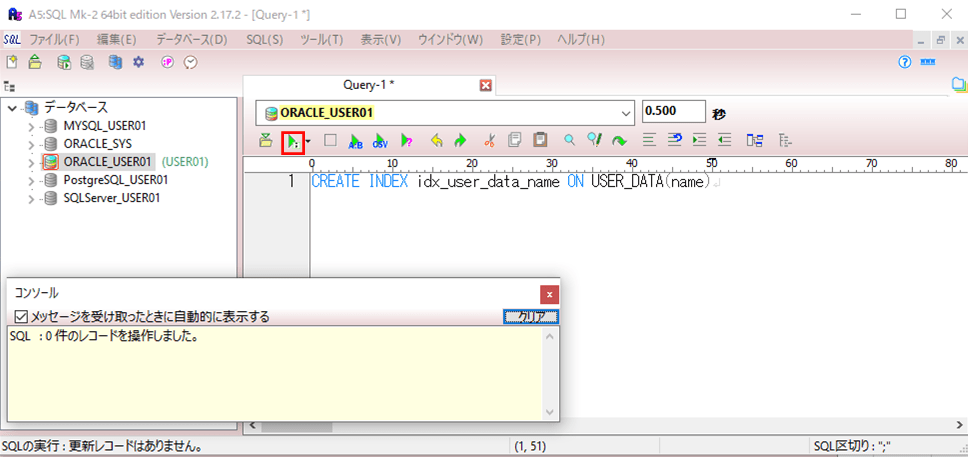
2) USER_DATAテーブルのnameにインデックスを追加する。
CREATE INDEX idx_user_data_name ON USER_DATA(name)
3) USER_DATAテーブルのインデックスを確認すると、以下のように、USER_DATAテーブルのnameにインデックス(IDX_USER_DATA_NAME)が設定されていることが確認できる。
SELECT ui.INDEX_NAME, ui.INDEX_TYPE, uc.CONSTRAINT_TYPE
, ui.TABLE_NAME, ui.UNIQUENESS, uic.COLUMN_NAME, ui.STATUS
FROM USER_INDEXES ui
INNER JOIN USER_IND_COLUMNS uic ON ui.INDEX_NAME = uic.INDEX_NAME
LEFT JOIN USER_CONSTRAINTS uc ON ui.INDEX_NAME = uc.CONSTRAINT_NAME
WHERE ui.TABLE_NAME = 'USER_DATA'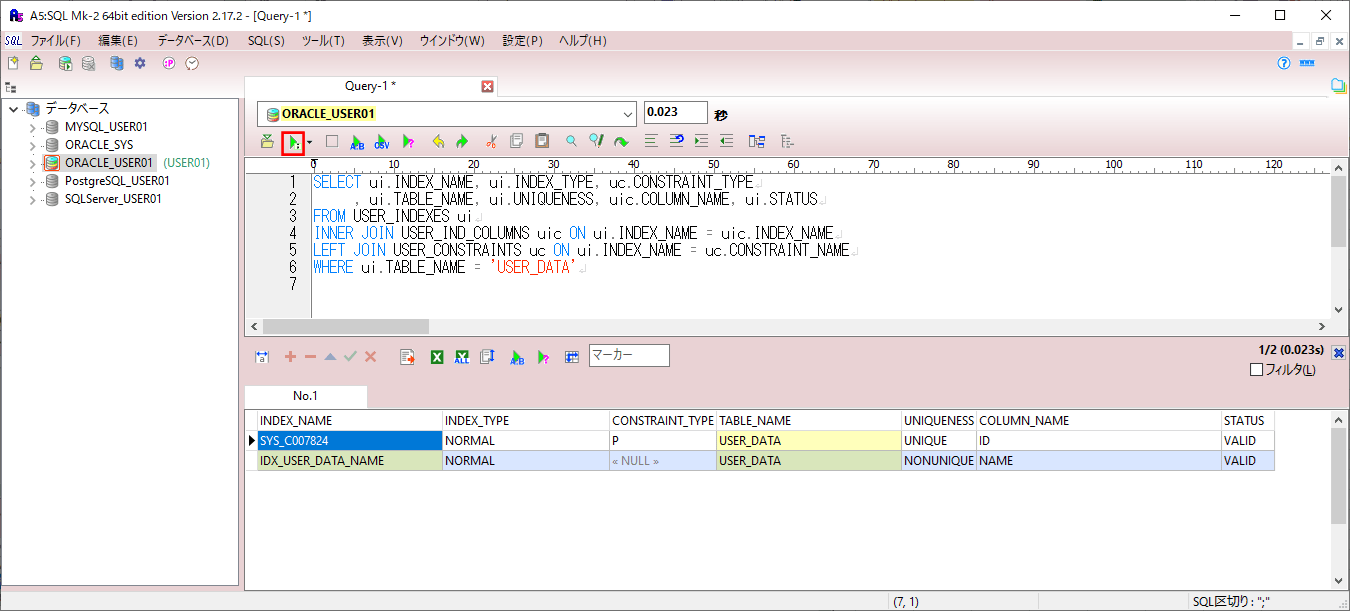

サンプルプログラムの作成
作成したサンプルプログラムの構成は、以下の通り。
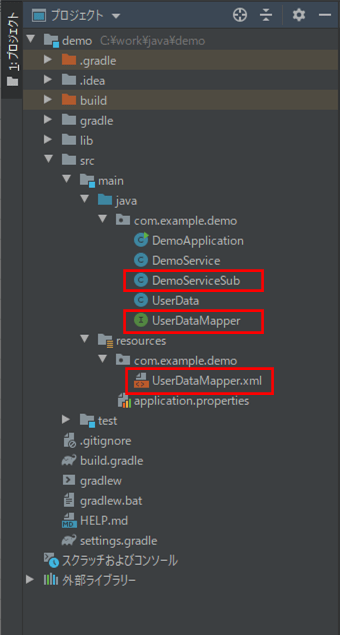
なお、上記の赤枠は、前提条件のプログラムから変更したプログラムである。
Mapperインタフェース・Mapper XMLの内容は以下の通りで、インデックスの無い項目(memo)で検索した場合、インデックスのある項目(name)で検索した場合それぞれのデータを取得するSQLを用意している。
package com.example.demo;
import org.apache.ibatis.annotations.Mapper;
import java.util.List;
@Mapper
public interface UserDataMapper {
/**
* 指定したIDをもつユーザーデータテーブル(user_data)のデータを取得する
* @param id ID
* @return ユーザーデータテーブル(user_data)の指定したIDのデータ
*/
UserData findById(Long id);
/**
* メモを条件にユーザーデータテーブル(user_data)のデータを取得する
* @return ユーザーデータテーブル(user_data)のリスト
*/
List<UserData> findByMemo();
/**
* 名前を条件にユーザーデータテーブル(user_data)のデータを取得する
* @return ユーザーデータテーブル(user_data)のリスト
*/
List<UserData> findByName();
}<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.demo.UserDataMapper">
<resultMap id="userDataResultMap" type="com.example.demo.UserData" >
<id column="id" property="id" jdbcType="BIGINT" />
<result column="name" property="name" jdbcType="VARCHAR" />
<result column="birth_year" property="birthY" jdbcType="VARCHAR" />
<result column="birth_month" property="birthM" jdbcType="VARCHAR" />
<result column="birth_day" property="birthD" jdbcType="VARCHAR" />
<result column="sex" property="sex" jdbcType="VARCHAR" />
<result column="memo" property="memo" jdbcType="VARCHAR" />
</resultMap>
<select id="findById" parameterType="java.lang.Long" resultMap="userDataResultMap">
SELECT id, name, birth_year, birth_month, birth_day, sex, memo FROM USER_DATA
WHERE id = #{id}
</select>
<select id="findByMemo" resultMap="userDataResultMap">
SELECT id, name, birth_year, birth_month, birth_day, sex, memo FROM USER_DATA
WHERE memo BETWEEN 'テスト1001' AND 'テスト1005'
</select>
<select id="findByName" resultMap="userDataResultMap">
SELECT id, name, birth_year, birth_month, birth_day, sex, memo FROM USER_DATA
WHERE name BETWEEN 'テスト プリン1001' AND 'テスト プリン1005'
</select>
</mapper>また、サービスクラスのサブクラスの内容は以下の通りで、それぞれのSQLを呼び出し、それぞれの実行時間を表示するようにしている。
package com.example.demo;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class DemoServiceSub {
/**
* ユーザーデータテーブル(user_data)へアクセスするマッパー
*/
@Autowired
private UserDataMapper userDataMapper;
/**
* 性能検証を行うための個別サービス
*/
public void verifyPerformanceEach() {
// 初回DB接続時は時間がかかるため、あえて性能測定対象外のSQLを1度実行しておく
userDataMapper.findById(Long.valueOf(1));
System.out.println("--- メモを条件にユーザーデータテーブル(user_data)の"
+ "データを取得するSQLを実行します start. ---");
// 処理前の現在時刻を取得
long startTime = System.currentTimeMillis();
// メモを条件にユーザーデータテーブルのデータを取得
List<UserData> userDataList = userDataMapper.findByMemo();
// 処理後の現在時刻を取得
long endTime = System.currentTimeMillis();
System.out.println("取得件数 : " + userDataList.size());
System.out.println("処理時間:" + (endTime - startTime) + " ms");
System.out.println("--- メモを条件にユーザーデータテーブル(user_data)の"
+ "データを取得するSQLを実行します end. ---");
System.out.println();
System.out.println("--- 名前を条件にユーザーデータテーブル(user_data)の"
+ "データを取得するSQLを実行します start. ---");
// 処理前の現在時刻を取得
startTime = System.currentTimeMillis();
// 名前を条件にユーザーデータテーブルのデータを取得
userDataList = userDataMapper.findByName();
// 処理後の現在時刻を取得
endTime = System.currentTimeMillis();
System.out.println("取得件数 : " + userDataList.size());
System.out.println("処理時間:" + (endTime - startTime) + " ms");
System.out.println("--- 名前を条件にユーザーデータテーブル(user_data)の"
+ "データを取得するSQLを実行します end. ---");
System.out.println();
}
}その他のソースコード内容は、以下のサイトを参照のこと。
https://github.com/purin-it/java/tree/master/spring-boot-oracle-performance-index/demo

サンプルプログラムの実行結果
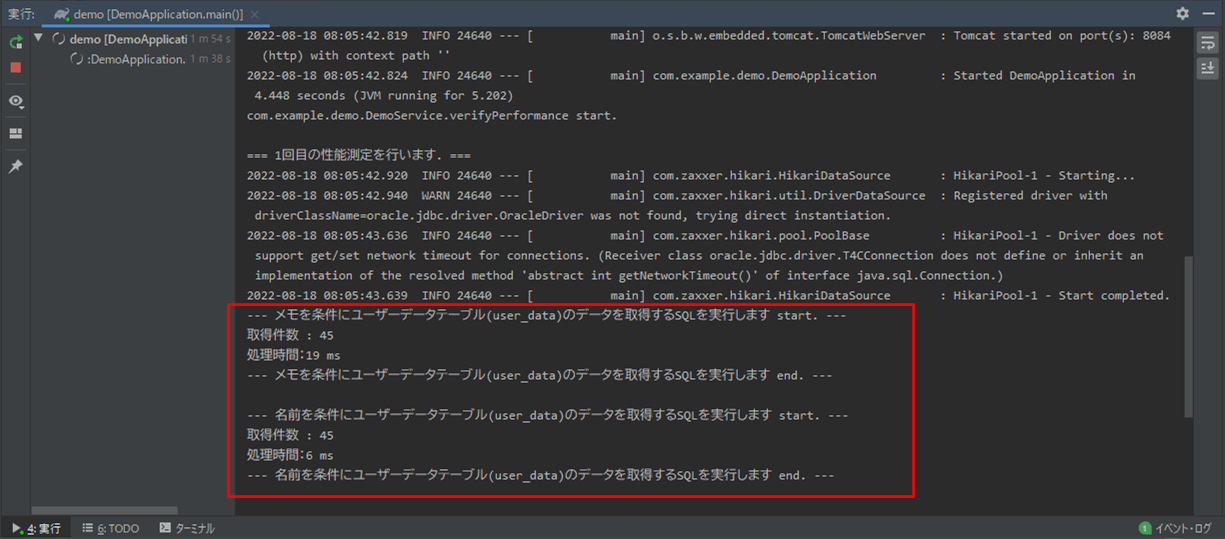
サンプルプログラムの実行結果は以下の通りで、検索項目にインデックスを利用した方が、SQLが速くなることが確認できる。
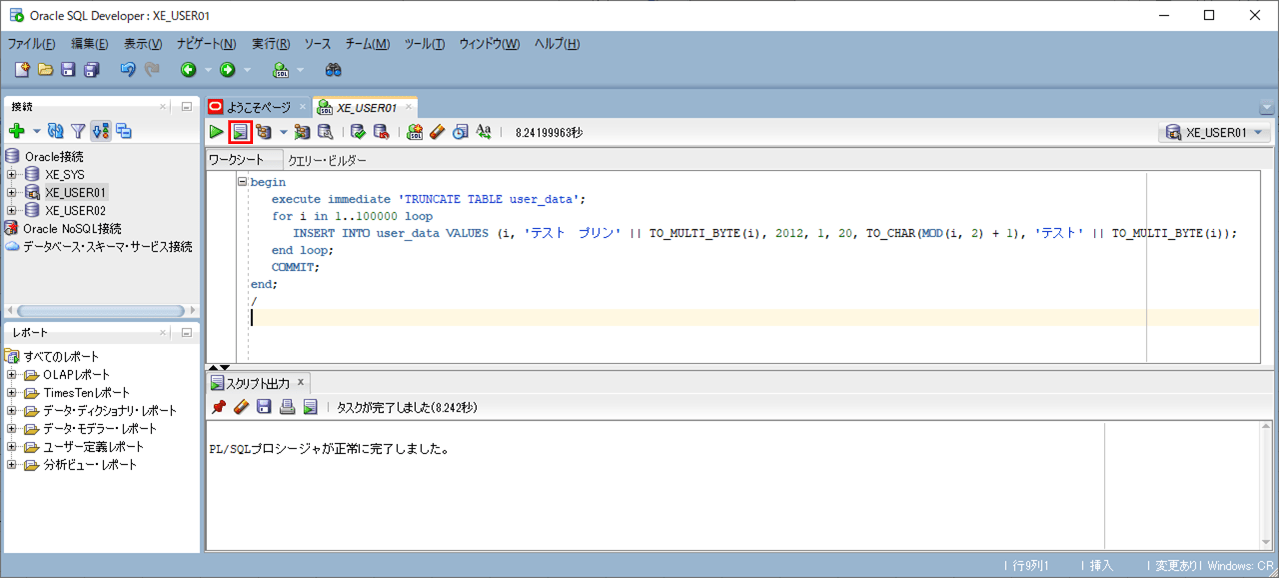
1) 以下を実行し、USER_DATAテーブルに100,000件のデータを追加する。
begin
execute immediate 'TRUNCATE TABLE user_data';
for i in 1..100000 loop
INSERT INTO user_data VALUES (i, 'テスト プリン' || TO_MULTI_BYTE(i), 2012, 1, 20
, TO_CHAR(MOD(i, 2) + 1), 'テスト' || TO_MULTI_BYTE(i));
end loop;
COMMIT;
end;
/
実行後、以下のように、レコード数が100,000件になっていることが確認できる。
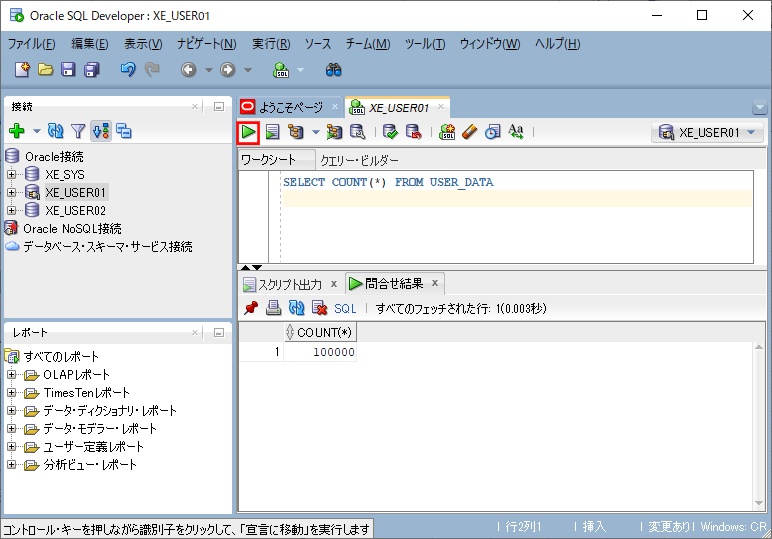
2) 1)の状態でSpring Bootのメインクラス(DemoApplication.java)を実行した結果、コンソールログに出力される内容は以下の通り。
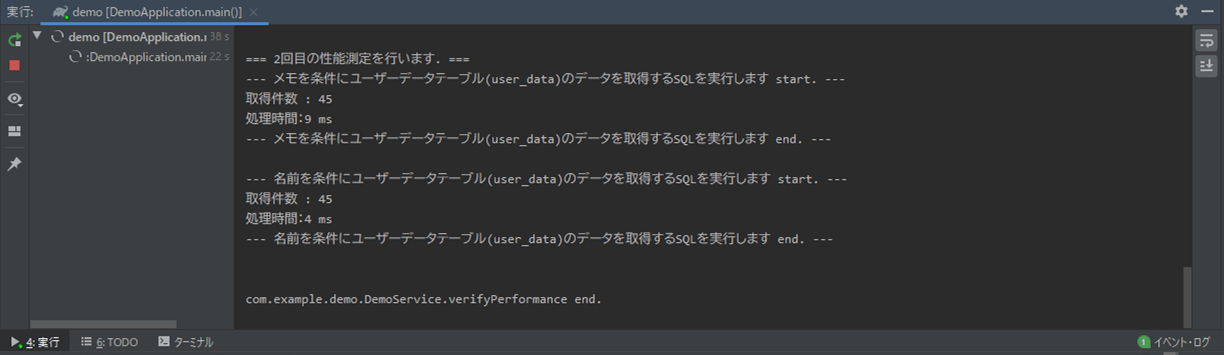
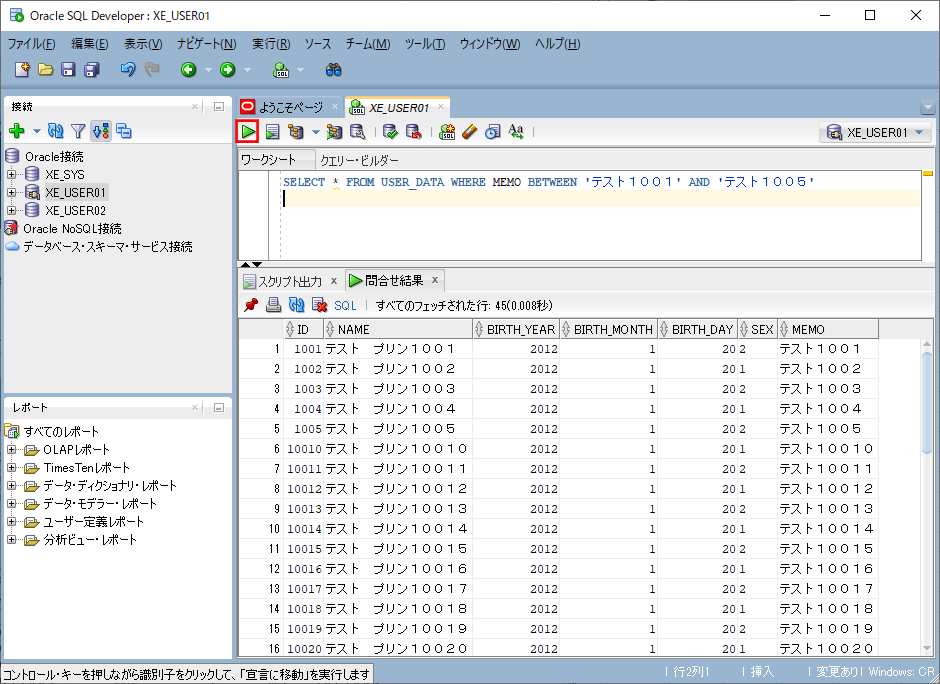
3) インデックスの無い項目(memo)で検索した場合のSQL実行結果と実行計画は以下の通りで、インデックスを利用しないで検索していることが確認できる。
SELECT * FROM USER_DATA WHERE MEMO BETWEEN 'テスト1001' AND 'テスト1005'
EXPLAIN PLAN FOR SELECT * FROM USER_DATA
WHERE MEMO BETWEEN 'テスト1001' AND 'テスト1005';
SELECT PLAN_TABLE_OUTPUT FROM TABLE(DBMS_XPLAN.DISPLAY());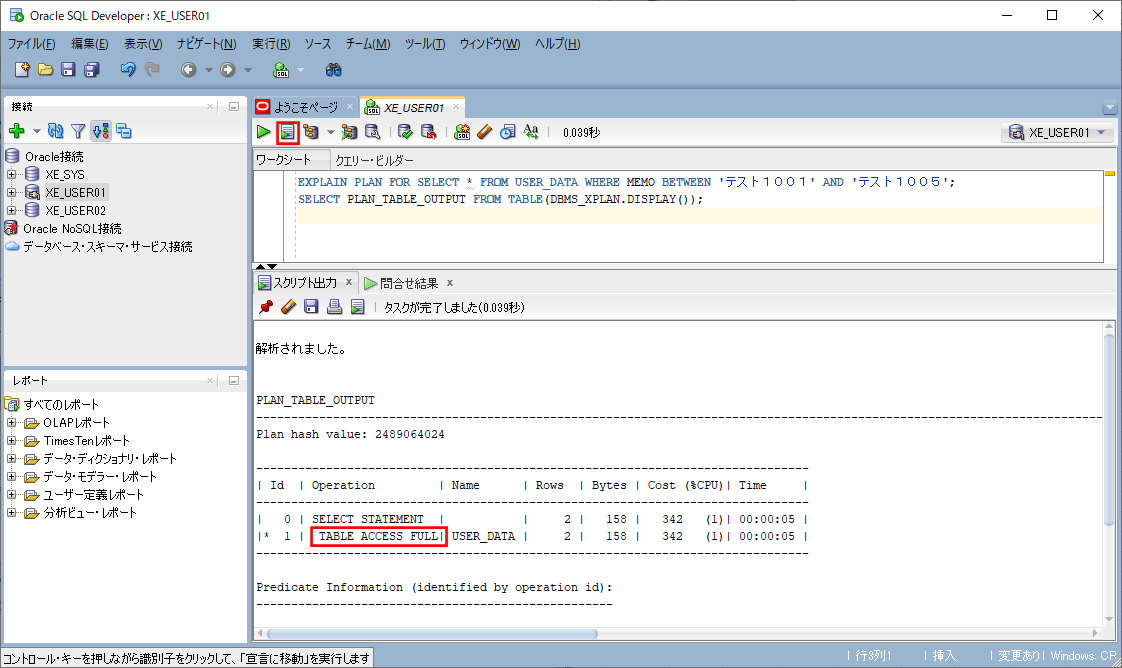
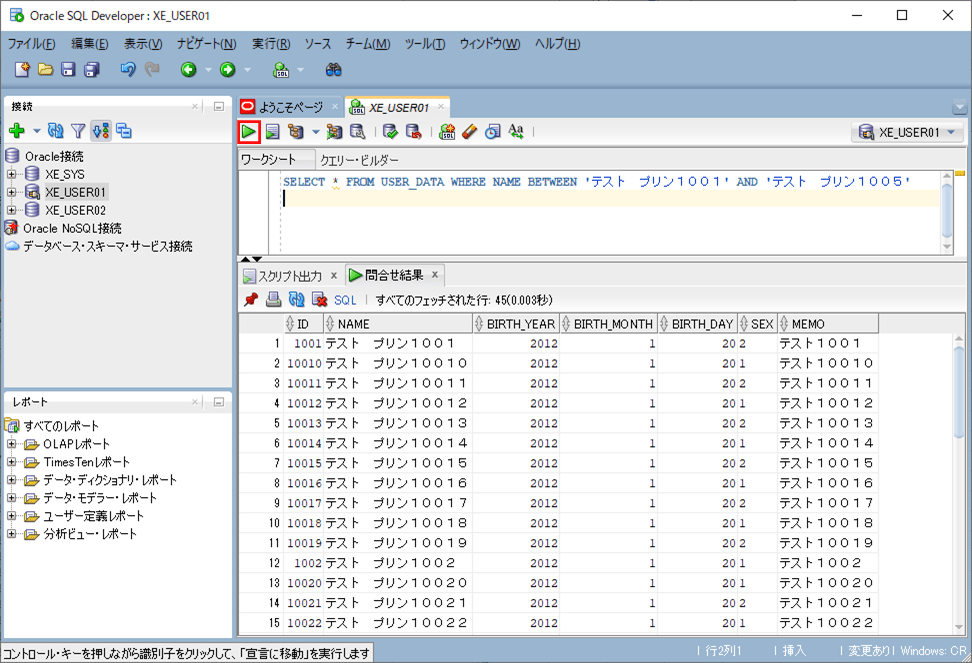
4) インデックスの有る項目(name)で検索した場合のSQL実行結果と実行計画は以下の通りで、インデックスを利用して検索していることが確認できる。
SELECT * FROM USER_DATA WHERE NAME BETWEEN 'テスト プリン1001' AND 'テスト プリン1005'
EXPLAIN PLAN FOR SELECT * FROM USER_DATA
WHERE NAME BETWEEN 'テスト プリン1001' AND 'テスト プリン1005';
SELECT PLAN_TABLE_OUTPUT FROM TABLE(DBMS_XPLAN.DISPLAY());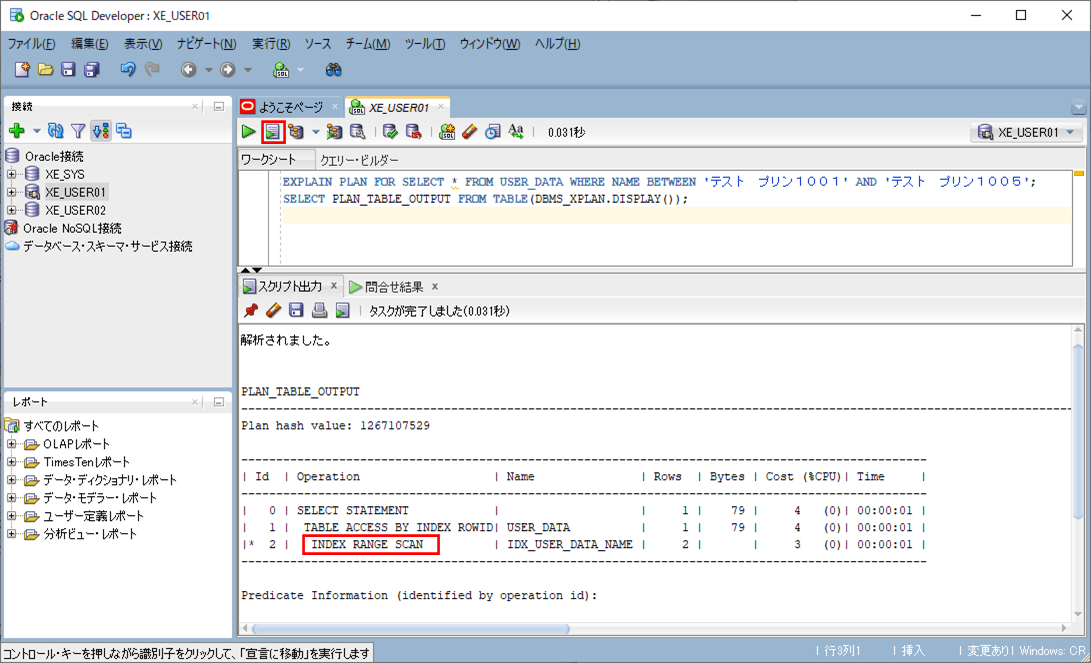
要点まとめ
- SQLのWHERE句でインデックスを利用して検索すると、インデックスを利用しない場合に比べて、処理が速くなることが多い。




