SQL Server上で英大文字小文字を区別して検索できるようにしてみた
以下の記事に記載したように、SQL Serverの場合、デフォルトの設定だと英大文字小文字を区別しないで検索を行う。

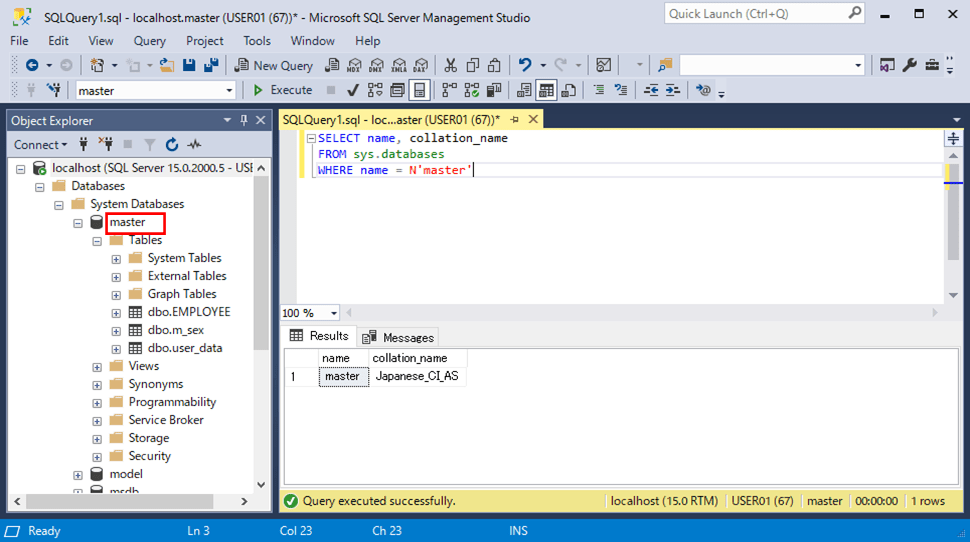
その理由は、以下のSQLで、user_dataテーブルの入っているmasterデータベースの照合順序(Collation)を確認したとき、「Japanese_CI_AS」という大文字小文字を区別しない設定になっているためである。
SELECT name, collation_name FROM sys.databases WHERE name = N'master'
なお、照合順序「Japanese_CI_AS」の意味については、以下のサイトを参照のこと。
http://www.innoya.com/board/ViewTip.aspx?menuID=4&page=2&idx=666
今回は、照合順序を、「Japanese_CS_AS」という大文字小文字を区別する設定に、SQL・テーブルの列・データベース単位で変更してみたので、その結果を共有する。
前提条件
下記記事の前提条件を満たしていること。
やってみたこと
SQLによる照合順序変更指定
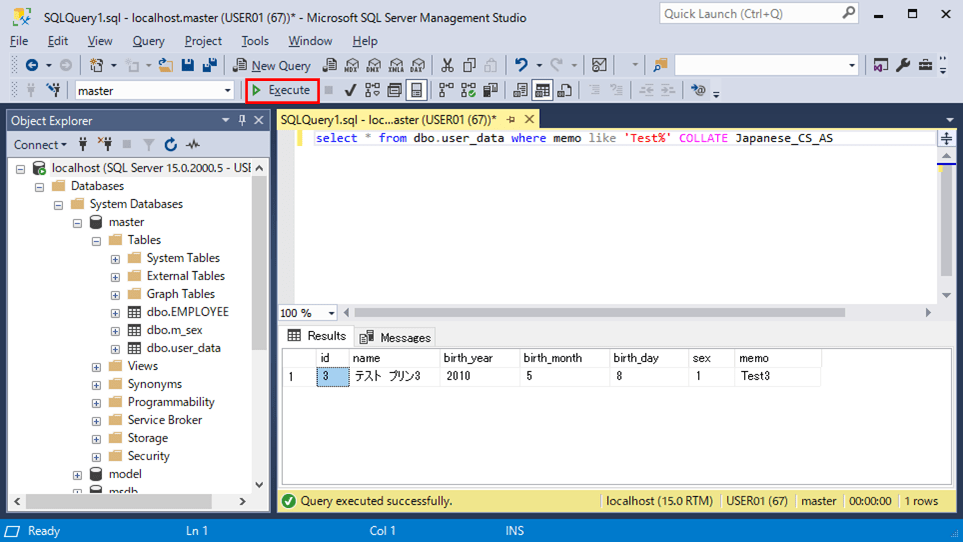
SQL文で英大文字小文字を区別するよう変更するには、照合順序を変更したい条件句の末尾に「 COLLATE Japanese_CS_AS」を付与する。その実行結果は以下の通りで、英大文字小文字を区別して検索することが確認できる。
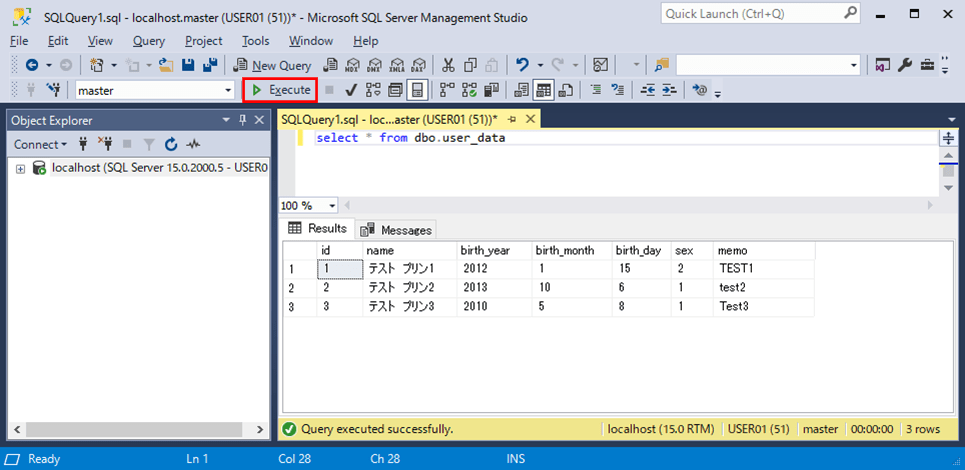
1) 抽出対象となるテーブルのデータは、以下の通り。
select * from dbo.user_data
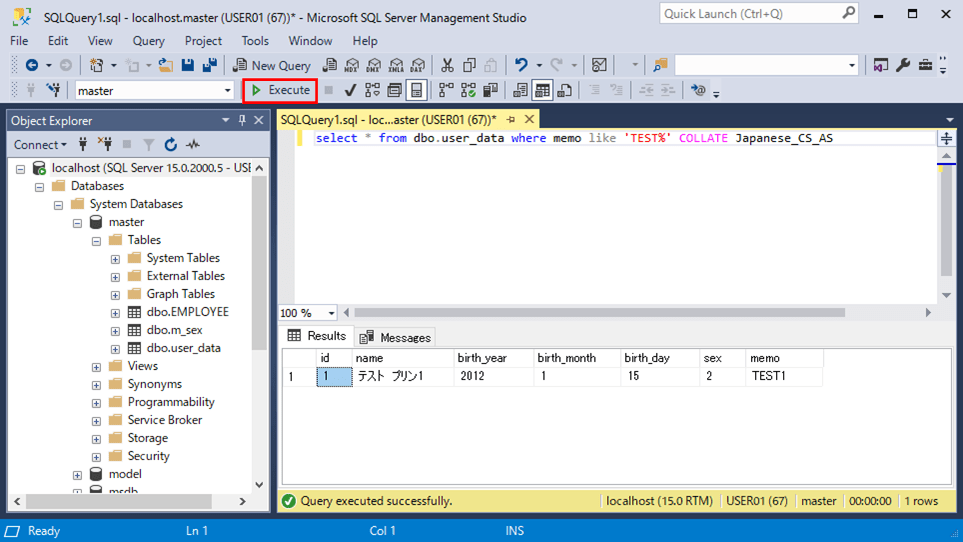
2) 照合順序を変更したい条件句の末尾に「 COLLATE Japanese_CS_AS」を付与して実行した結果は、以下の通り。
select * from dbo.user_data where memo like 'TEST%' COLLATE Japanese_CS_AS
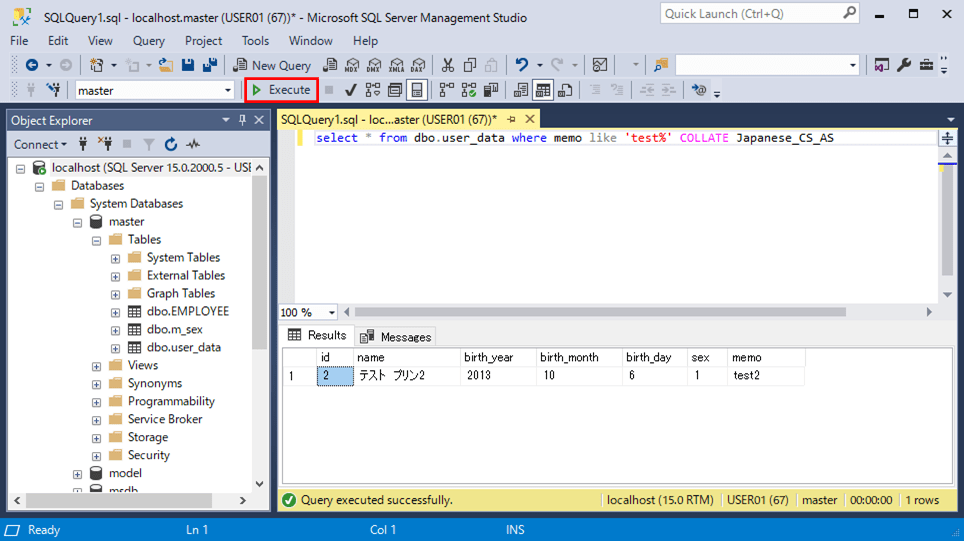
select * from dbo.user_data where memo like 'test%' COLLATE Japanese_CS_AS
select * from dbo.user_data where memo like 'Test%' COLLATE Japanese_CS_AS

テーブルの列による照合順序変更指定
テーブルの列定義で英大文字小文字を区別するよう変更するには、alter column句の末尾に「 COLLATE Japanese_CS_AS」を付与する。その実行結果は以下の通りで、英大文字小文字を区別して検索することが確認できる。なお、テーブルに対しては照合順序変更指定ができないので注意すること。
1) 抽出対象となるテーブルのデータは、以下の通り。
select * from dbo.user_data
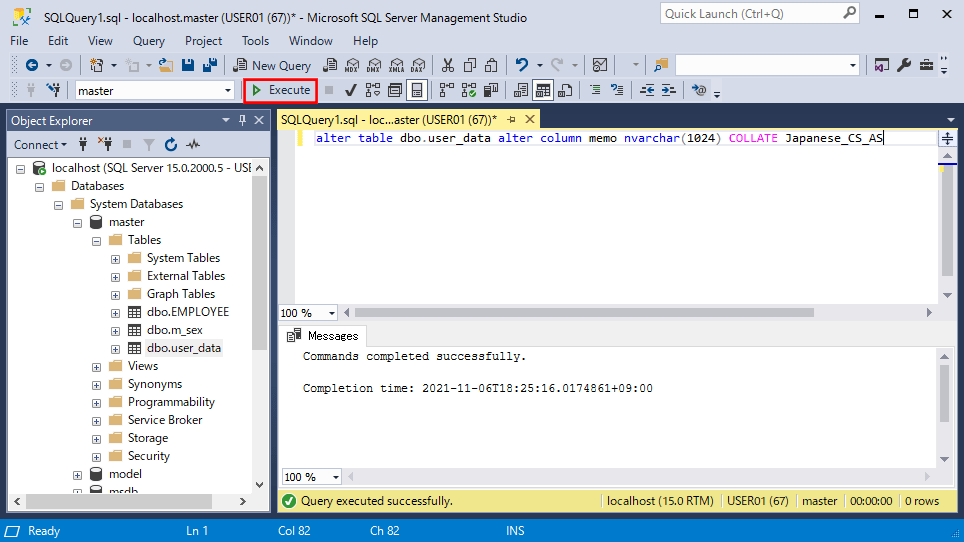
2) テーブルの列定義で英大文字小文字を区別するよう変更するSQLの実行結果は、以下の通り。
alter table dbo.user_data alter column memo nvarchar(1024) COLLATE Japanese_CS_AS
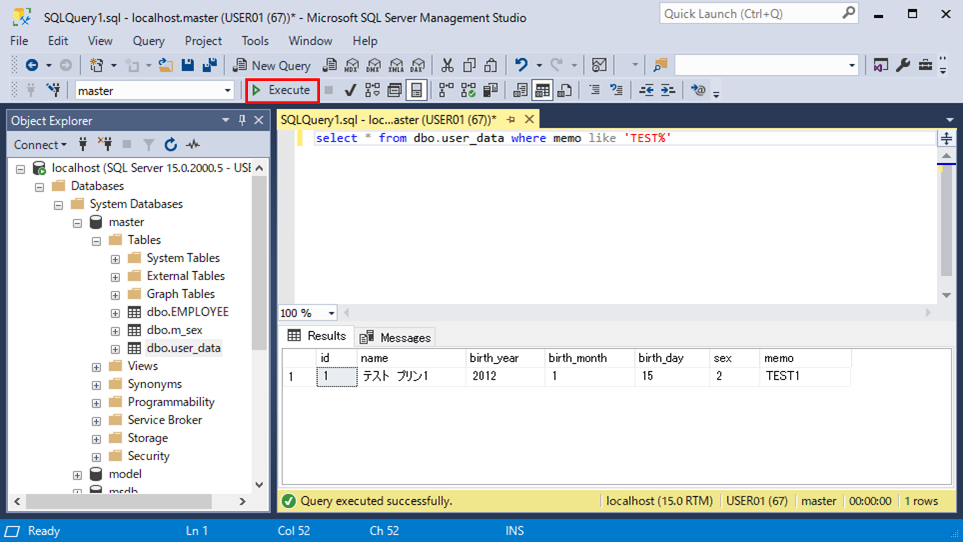
3) テーブルの列定義変更後のSQL実行結果は、以下の通り。
select * from dbo.user_data where memo like 'TEST%'
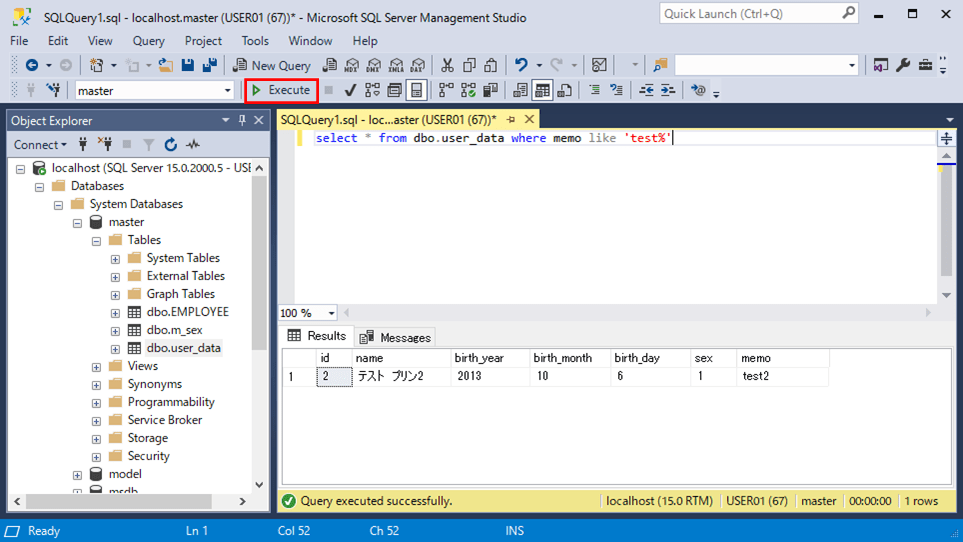
select * from dbo.user_data where memo like 'test%'
select * from dbo.user_data where memo like 'Test%'
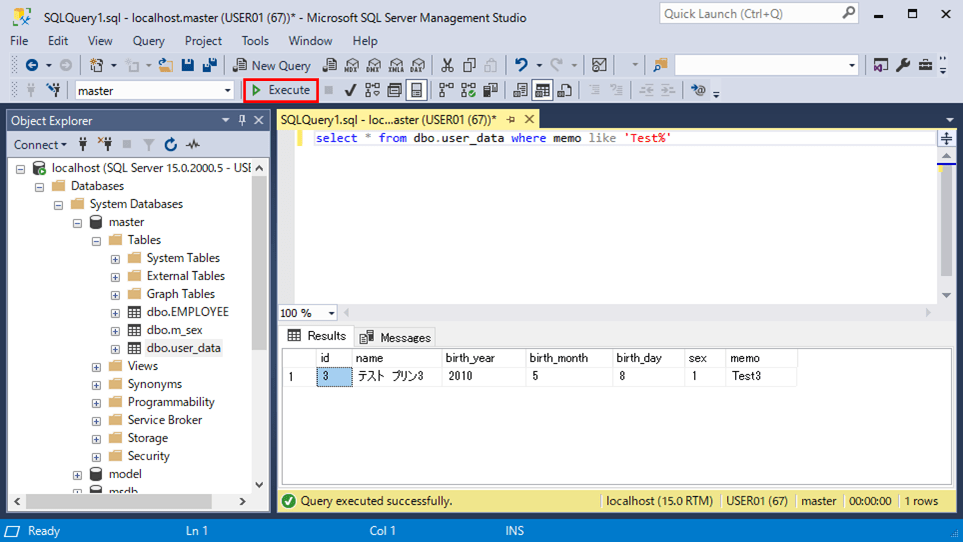

データベースによる照合順序変更指定
データベース単位で英大文字小文字を区別するよう変更するには、alter database文で照合順序を変更する。その実行結果は以下の通りで、英大文字小文字を区別して検索することが確認できる。なお、masterデータベース等のシステムデータベース上では照合順序の変更が行えないため、独自データベース上で結果を確認している。
1) データベース変更前の照合順序の設定は、以下の通り。
SELECT name, collation_name FROM sys.databases WHERE name = N'AzureStorageEmulatorDb510'
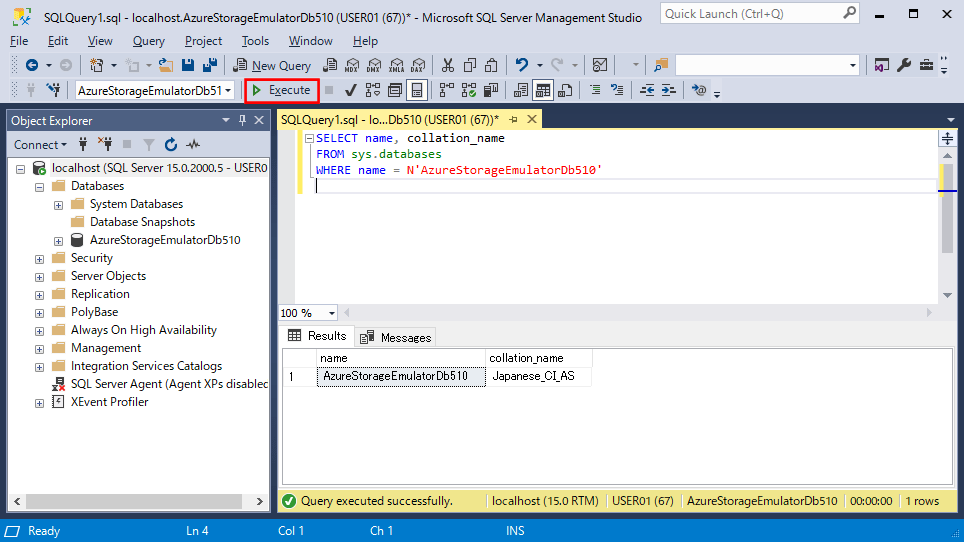
2) データベースの照合順序を変更するSQLの実行結果は、以下の通り。
alter database AzureStorageEmulatorDb510 COLLATE Japanese_CS_AS
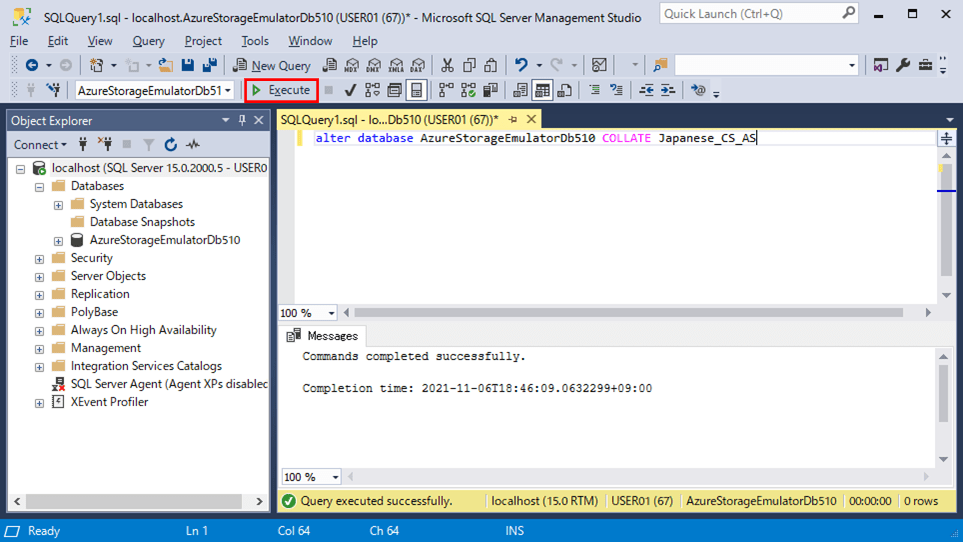
3) データベース変更後の照合順序の設定は、以下の通り。
SELECT name, collation_name FROM sys.databases WHERE name = N'AzureStorageEmulatorDb510'
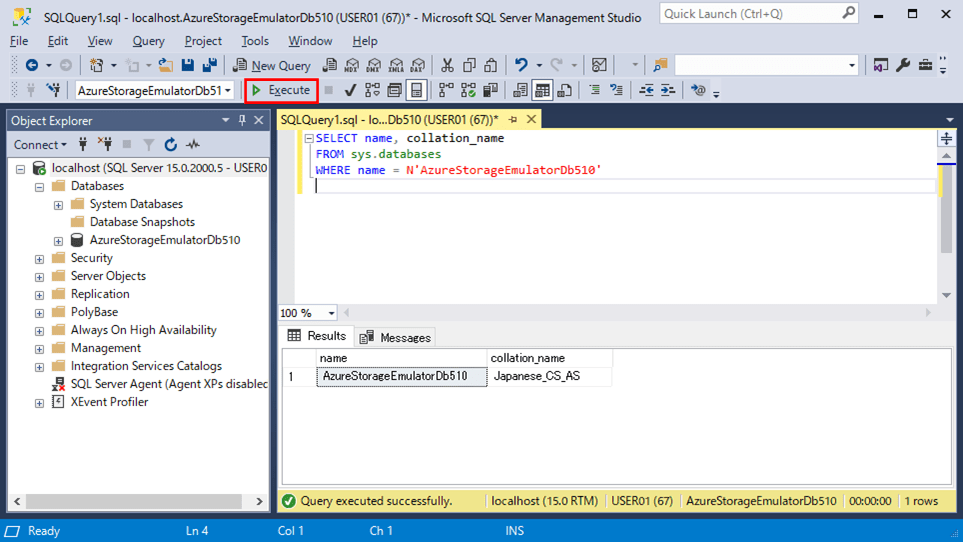
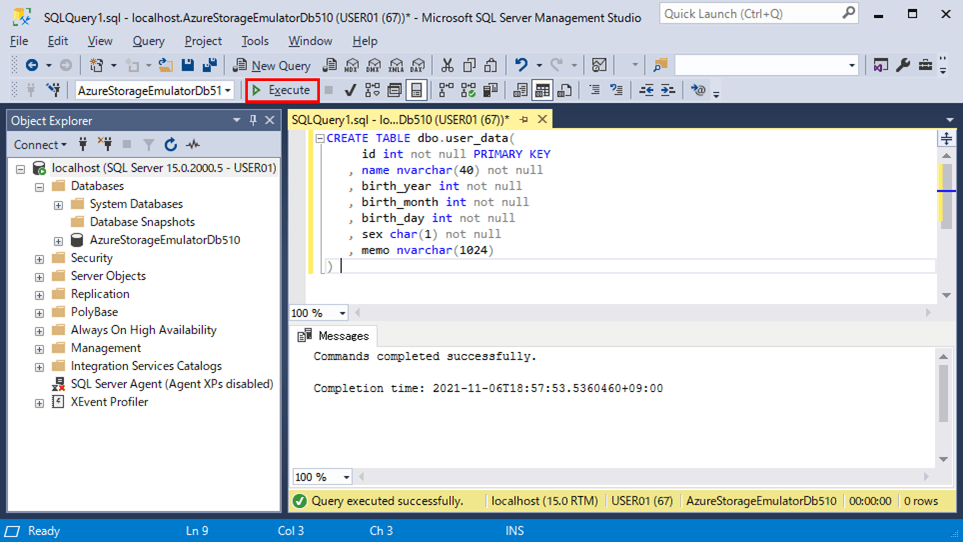
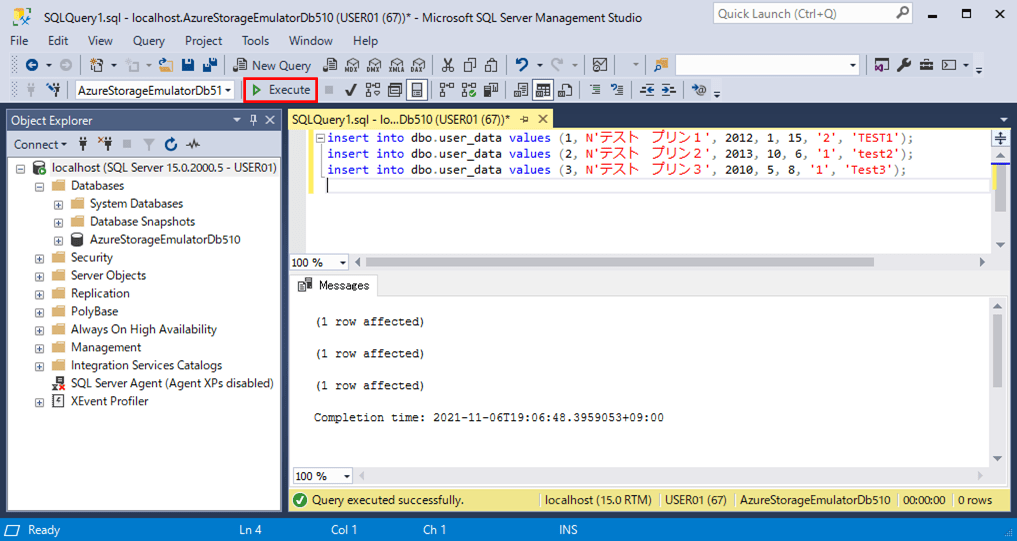
4) user_dataテーブルを新設し、データを追加した結果は、以下の通り。
CREATE TABLE dbo.user_data(
id int not null PRIMARY KEY
, name nvarchar(40) not null
, birth_year int not null
, birth_month int not null
, birth_day int not null
, sex char(1) not null
, memo nvarchar(1024)
) 
insert into dbo.user_data values (1, N'テスト プリン1', 2012, 1, 15, '2', 'TEST1'); insert into dbo.user_data values (2, N'テスト プリン2', 2013, 10, 6, '1', 'test2'); insert into dbo.user_data values (3, N'テスト プリン3', 2010, 5, 8, '1', 'Test3');
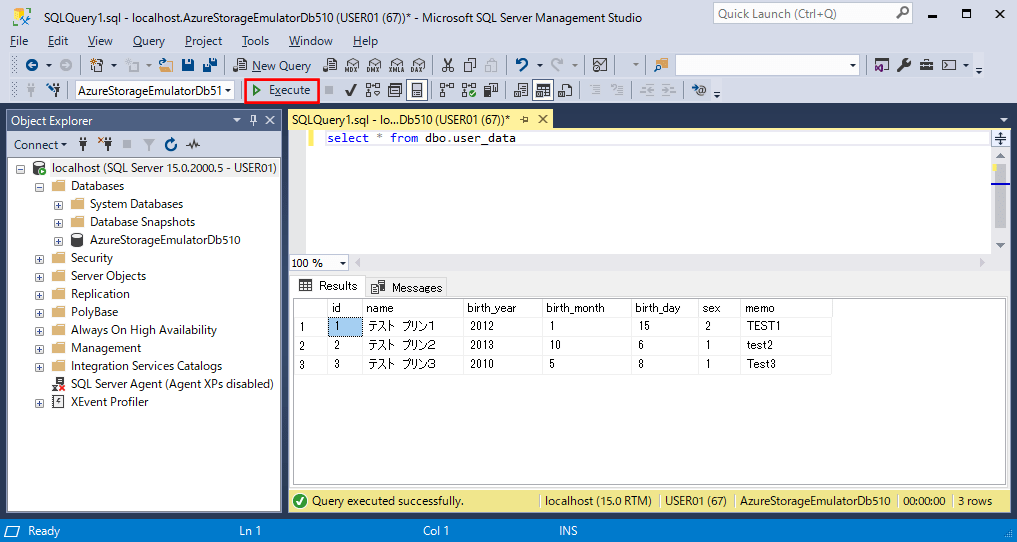
select * from dbo.user_data
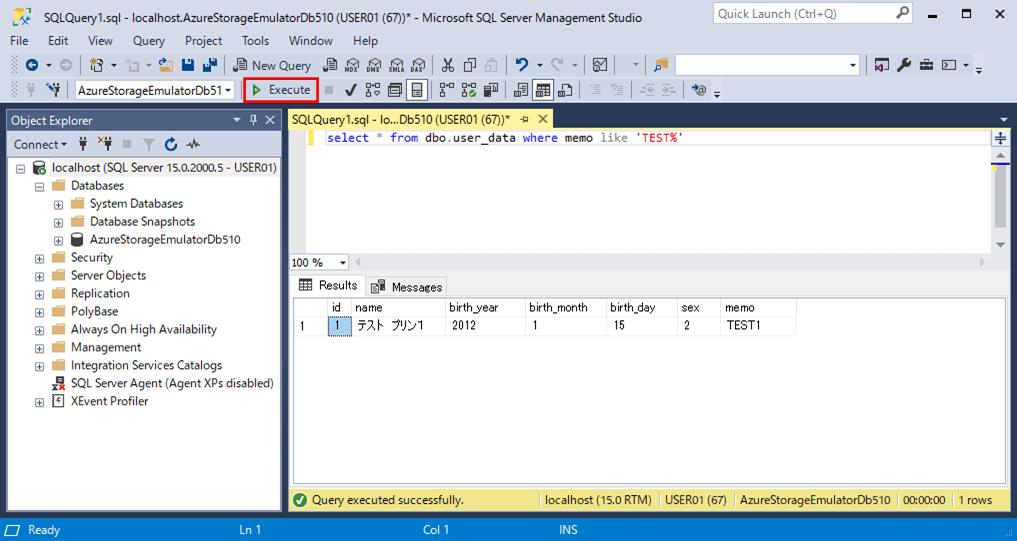
5) データベース定義変更し、テーブル追加後のSQL実行結果は、以下の通り。
select * from dbo.user_data where memo like 'TEST%'
select * from dbo.user_data where memo like 'test%'
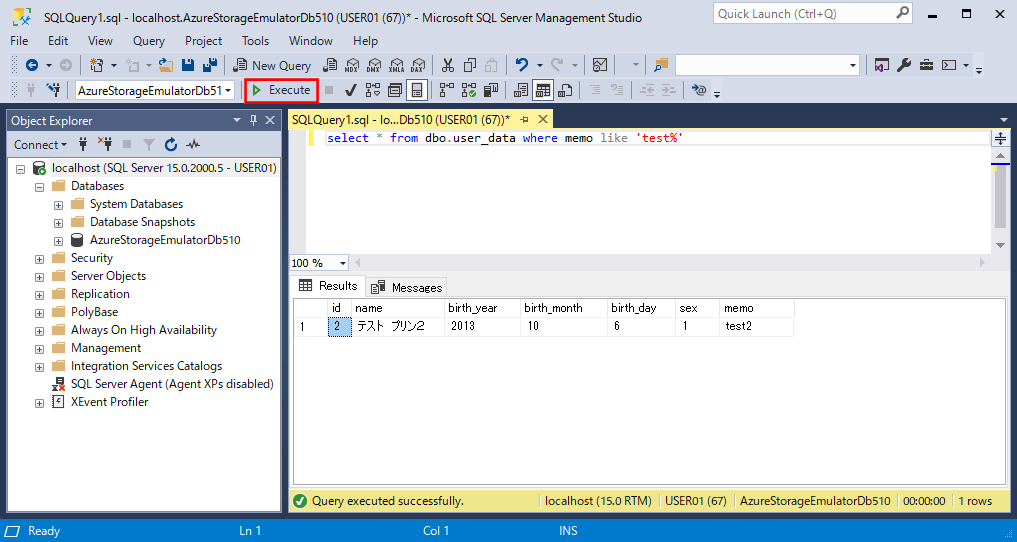
select * from dbo.user_data where memo like 'Test%'
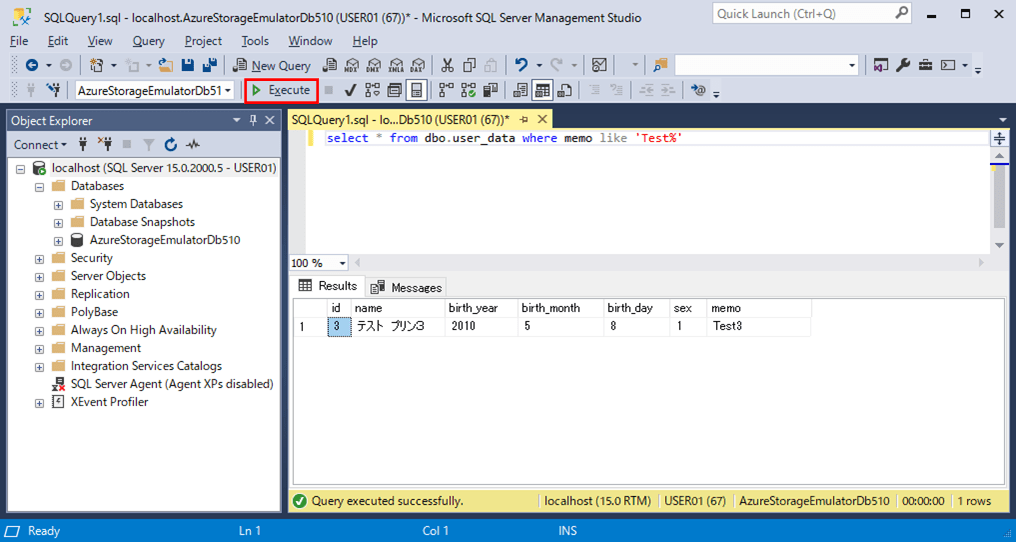
なお、データベースの照合順序を変更しても、既存のテーブルの照合順序は変更されないので、注意すること。照合順序についての詳細は、以下の公式サイトを参照のこと。
https://docs.microsoft.com/ja-jp/sql/relational-databases/collations/collation-and-unicode-support?view=sql-server-ver15
要点まとめ
- デフォルトの設定だと、SQL Serverでは英大文字小文字を区別しないで検索するが、SQL・テーブルの列・データベース単位で、照合順序を「Japanese_CS_AS」と変更することで、英大文字小文字を区別して検索を行うようになる。





