CSVファイルの内容をDBに書き込むバッチ処理内で様々な漢字文字を取り込んでみた
日本語の文字集合としてJIS(日本産業規格)で定めた規格として「JISX0213」があり、この中に「第1水準漢字」「第2水準漢字」「第3水準漢字」「第4水準漢字」等が含まれる。
今回は、「JISX0213」に含まれる「第1水準漢字」「第2水準漢字」「第3水準漢字」「第4水準漢字」と、「IBM拡張漢字」を含むCSVファイルの内容をDBに書き込んでみたときに、文字化けしないかどうか調査してみたので、共有する。
なお、「JISX0213」や「第1水準漢字」「第2水準漢字」「第3水準漢字」「第4水準漢字」については、以下のサイトを参照のこと。
JISX0213についての説明
また、「IBM拡張漢字」については、以下のサイトを参照のこと。
IBM拡張漢字についての説明
前提条件
下記記事のサンプルプログラムを作成済であること。

作成したサンプルプログラムの修正
前提条件の記事のサンプルプログラムを、CSVファイルを読み込む際の文字コードを変更できるよう修正する。なお、下記の赤枠は、前提条件のプログラムから変更したプログラムである。

DemoBatchService.javaの変更内容は以下の通りで、CSVファイルを読み込む際の文字コードを変更できるようにしている。
package com.example.service;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URISyntaxException;
import java.security.InvalidKeyException;
import org.apache.commons.lang3.StringUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import com.example.mybatis.UserDataMapper;
import com.example.mybatis.model.UserData;
import com.example.util.DemoStringUtil;
import com.microsoft.azure.storage.CloudStorageAccount;
import com.microsoft.azure.storage.StorageException;
import com.microsoft.azure.storage.blob.CloudBlobClient;
import com.microsoft.azure.storage.blob.CloudBlobContainer;
import com.microsoft.azure.storage.blob.CloudBlockBlob;
@Service
public class DemoBatchService {
/* Spring Bootでログ出力するためのLogbackのクラスを生成 */
private static final Logger LOGGER
= LoggerFactory.getLogger(DemoBatchService.class);
/** 指定する文字コード */
private static final String CHARACTER_CODE = "UTF-8";
//private static final String CHARACTER_CODE = "Shift_JIS";
//private static final String CHARACTER_CODE = "MS932";
/** Azure Storageのアカウント名 */
@Value("${azure.storage.accountName}")
private String storageAccountName;
/** Azure Storageへのアクセスキー */
@Value("${azure.storage.accessKey}")
private String storageAccessKey;
/** Azure StorageのBlobコンテナー名 */
@Value("${azure.storage.containerName}")
private String storageContainerName;
/** USER_DATAテーブルにアクセスするマッパー */
@Autowired
private UserDataMapper userDataMapper;
/**
* BlobStorageからファイル(user_data.csv)を読み込み、USER_DATAテーブルに書き込む
*/
@Transactional
public void readUserData() {
// BlobStorageからファイル(user_data.csv)を読み込む
try (BufferedReader br = new BufferedReader(
new InputStreamReader(getBlobCsvData(), CHARACTER_CODE))) {
String lineStr = null;
int lineCnt = 0;
// 1行目(タイトル行)は読み飛ばし、2行目以降はチェックの上、
// USER_DATAテーブルに書き込む
// チェックエラー時はエラーログを出力の上、DB更新は行わず先へ進む
while ((lineStr = br.readLine()) != null) {
// 1行目(タイトル行)は読み飛ばす
lineCnt++;
if (lineCnt == 1) {
continue;
}
// 引数のCSVファイル1行分の文字列を受け取り、エラーがあればNULLを、
// エラーがなければUserDataオブジェクトに変換し返す
UserData userData = checkData(lineStr, lineCnt);
// 読み込んだファイルをUSER_DATAテーブルに書き込む
if (userData != null) {
userDataMapper.upsert(userData);
}
}
} catch (Exception ex) {
LOGGER.error(ex.getMessage());
throw new RuntimeException(ex);
}
}
/**
* Blobストレージからファイルデータ(user_data.csv)を取得する.
* @return ファイルデータ(user_data.csv)の入力ストリーム
* @throws URISyntaxException
* @throws InvalidKeyException
* @throws StorageException
*/
private InputStream getBlobCsvData()
throws URISyntaxException, InvalidKeyException, StorageException {
// Blobストレージへの接続文字列
String storageConnectionString = "DefaultEndpointsProtocol=https;"
+ "AccountName=" + storageAccountName + ";"
+ "AccountKey=" + storageAccessKey + ";";
// ストレージアカウントオブジェクトを取得
CloudStorageAccount storageAccount
= CloudStorageAccount.parse(storageConnectionString);
// Blobクライアントオブジェクトを取得
CloudBlobClient blobClient
= storageAccount.createCloudBlobClient();
// Blob内のコンテナーを取得
CloudBlobContainer container
= blobClient.getContainerReference(storageContainerName);
// BlobStorageからファイル(user_data.csv)を読み込む
CloudBlockBlob blob = container.getBlockBlobReference("user_data.csv");
return blob.openInputStream();
}
/**
* 引数のCSVファイル1行分の文字列を受け取り、エラーがあればNULLを、
* エラーがなければUserDataオブジェクトに変換し返す.
* @param lineStr CSVファイル1行分の文字列
* @param lineCnt 行数
* @return 変換後のUserData
*/
private UserData checkData(String lineStr, int lineCnt) {
// 引数のCSVファイル1行分の文字列をカンマで分割
String[] strArray = lineStr.split(",");
// 桁数不正の場合はエラー
if (strArray == null || strArray.length != 7) {
LOGGER.info(lineCnt + "行目: 桁数が不正です。");
return null;
}
// 文字列前後のダブルクォーテーションを削除する
for (int i = 0; i < strArray.length; i++) {
strArray[i] = DemoStringUtil.trimDoubleQuot(strArray[i]);
}
// 1列目が空またはNULLの場合はエラー
if (StringUtils.isEmpty(strArray[0])) {
LOGGER.info(lineCnt + "行目: 1列目が空またはNULLです。");
return null;
}
// 1列目が数値以外の場合はエラー
if (!StringUtils.isNumeric(strArray[0])) {
LOGGER.info(lineCnt + "行目: 1列目が数値以外です。");
return null;
}
// 1列目の桁数が不正な場合はエラー
if (strArray[0].length() > 6) {
LOGGER.info(lineCnt + "行目: 1列目の桁数が不正です。");
return null;
}
// 2列目が空またはNULLの場合はエラー
if (StringUtils.isEmpty(strArray[1])) {
LOGGER.info(lineCnt + "行目: 2列目が空またはNULLです。");
return null;
}
// 2列目の桁数が不正な場合はエラー
if (strArray[1].length() > 40) {
LOGGER.info(lineCnt + "行目: 2列目の桁数が不正です。");
return null;
}
// 3列目が空またはNULLの場合はエラー
if (StringUtils.isEmpty(strArray[2])) {
LOGGER.info(lineCnt + "行目: 3列目が空またはNULLです。");
return null;
}
// 3列目が数値以外の場合はエラー
if (!StringUtils.isNumeric(strArray[2])) {
LOGGER.info(lineCnt + "行目: 3列目が数値以外です。");
return null;
}
// 3列目の桁数が不正な場合はエラー
if (strArray[2].length() > 4) {
LOGGER.info(lineCnt + "行目: 3列目の桁数が不正です。");
return null;
}
// 4列目が空またはNULLの場合はエラー
if (StringUtils.isEmpty(strArray[3])) {
LOGGER.info(lineCnt + "行目: 4列目が空またはNULLです。");
return null;
}
// 4列目が数値以外の場合はエラー
if (!StringUtils.isNumeric(strArray[3])) {
LOGGER.info(lineCnt + "行目: 4列目が数値以外です。");
return null;
}
// 4列目の桁数が不正な場合はエラー
if (strArray[3].length() > 2) {
LOGGER.info(lineCnt + "行目: 4列目の桁数が不正です。");
return null;
}
// 5列目が空またはNULLの場合はエラー
if (StringUtils.isEmpty(strArray[4])) {
LOGGER.info(lineCnt + "行目: 5列目が空またはNULLです。");
return null;
}
// 5列目が数値以外の場合はエラー
if (!StringUtils.isNumeric(strArray[4])) {
LOGGER.info(lineCnt + "行目: 5列目が数値以外です。");
return null;
}
// 5列目の桁数が不正な場合はエラー
if (strArray[4].length() > 2) {
LOGGER.info(lineCnt + "行目: 5列目の桁数が不正です。");
return null;
}
// 3列目・4列目・5列目から生成される日付が不正であればエラー
String birthDay = strArray[2] + DemoStringUtil.addZero(strArray[3])
+ DemoStringUtil.addZero(strArray[4]);
if (!DemoStringUtil.isCorrectDate(birthDay, "uuuuMMdd")) {
LOGGER.info(lineCnt + "行目: 3~5列目の日付が不正です。");
return null;
}
// 6列目が1,2以外の場合はエラー
if (!("1".equals(strArray[5])) && !("2".equals(strArray[5]))) {
LOGGER.info(lineCnt + "行目: 6列目の性別が不正です。");
return null;
}
// 7列目の桁数が不正な場合はエラー
if (!StringUtils.isEmpty(strArray[6])
&& strArray[6].length() > 1024) {
LOGGER.info(lineCnt + "行目: 7列目の桁数が不正です。");
return null;
}
// エラーがなければUserDataオブジェクトに変換し返す
UserData userData = new UserData();
userData.setId(Integer.parseInt(strArray[0]));
userData.setName(strArray[1]);
userData.setBirth_year(Integer.parseInt(strArray[2]));
userData.setBirth_month(Integer.parseInt(strArray[3]));
userData.setBirth_day(Integer.parseInt(strArray[4]));
userData.setSex(strArray[5]);
userData.setMemo(strArray[6]);
return userData;
}
}その他のソースコード内容は、以下のサイトを参照のこと。
https://github.com/purin-it/azure/tree/master/timer-trigger-batch-many-chinese-character/demoAzureFunc
サンプルプログラムの実行結果
サンプルプログラムの実行結果は、以下の通り。
1) 取り込むCSVファイルの内容を以下の通りとする。なお、このファイルは、文字コードがUTF-8で、「第1水準漢字」「第2水準漢字」「第3水準漢字」「第4水準漢字」「IBM拡張漢字」を全て含んでいる。
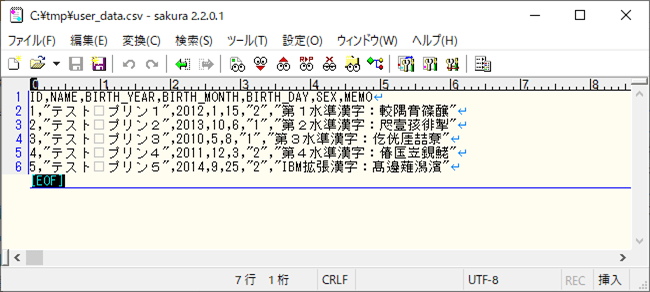
なお、上記ファイルの「第1水準漢字」「第2水準漢字」「第3水準漢字」「第4水準漢字」「IBM拡張漢字」は、以下のサイトから抜粋したものとなる。
●第1水準漢字
http://www13.plala.or.jp/bigdata/jis_1.html
●第2水準漢字
http://www13.plala.or.jp/bigdata/jis_2.html
●第3水準漢字
http://www13.plala.or.jp/bigdata/jis_3.html
●第4水準漢字
http://www13.plala.or.jp/bigdata/jis_4.html
●IBM拡張漢字
http://www13.plala.or.jp/bigdata/kanji_2.html
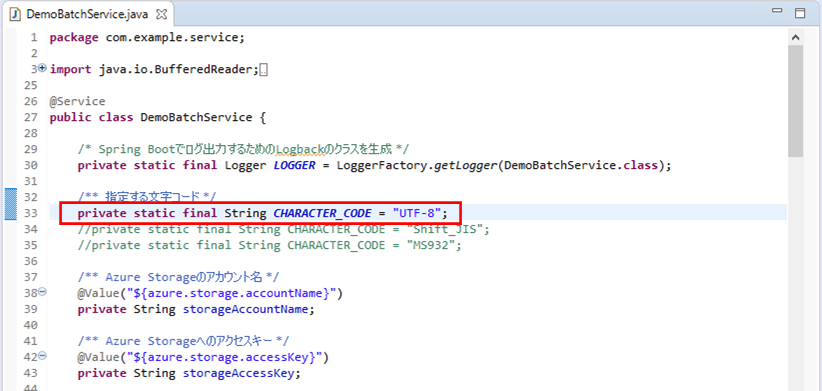
2) DemoBatchService.javaを以下のように修正し、文字コード=UTF-8で、1)のファイルを取り込むものとする。なお、下図ではimport文の多くを省略している。
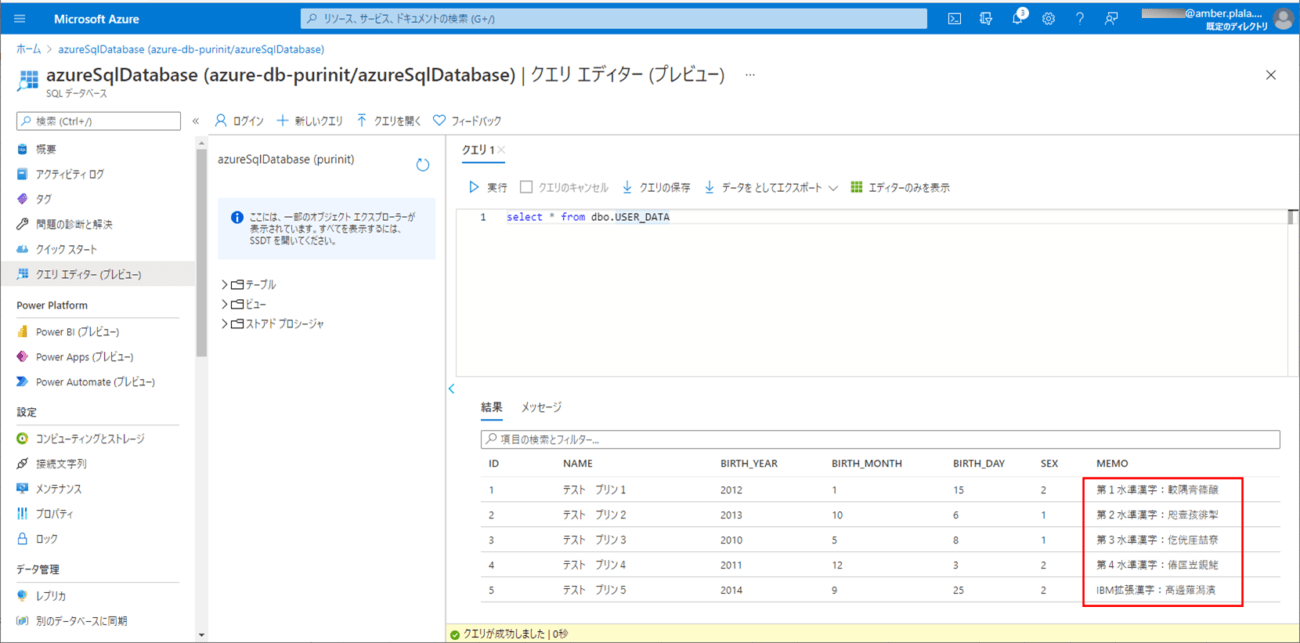
3) 1)のファイルをDBに取り込んだ結果は以下の通りで、文字化けしていないことが確認できる。

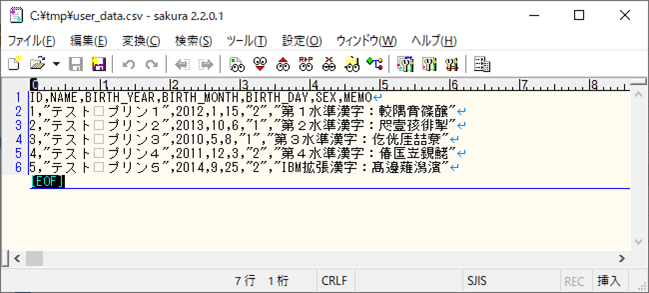
4) 取り込むCSVファイルの内容を以下の通りとする。なお、このファイルは、文字コードがShift_JISで、「第1水準漢字」「第2水準漢字」「第3水準漢字」「第4水準漢字」「IBM拡張漢字」を全て含んでいる。
5) DemoBatchService.javaを以下のように修正し、文字コード=Shift_JISで、4)のファイルを取り込むものとする。なお、下図ではimport文の多くを省略している。
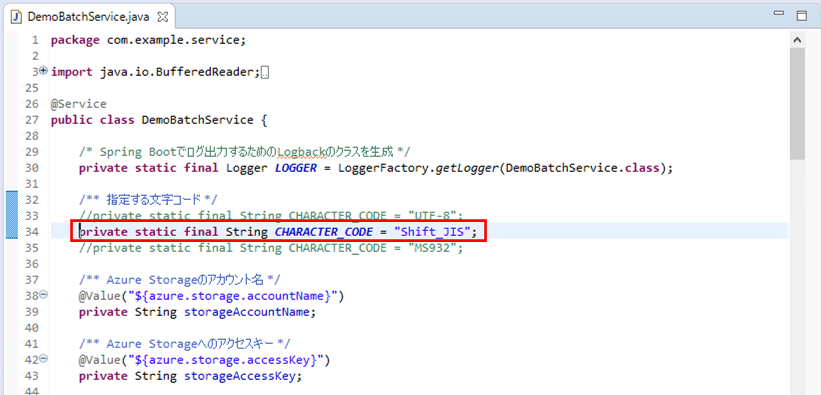
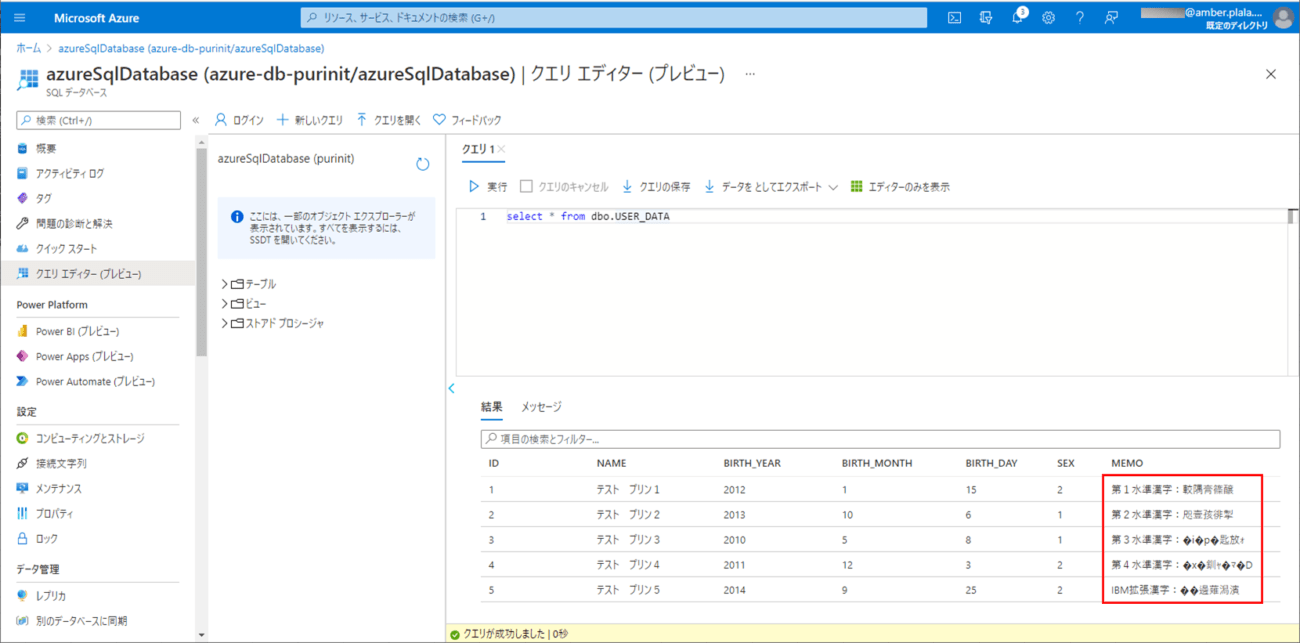
6) 4)のファイルをDBに取り込んだ結果は、以下の通りで、「第3水準漢字」「第4水準漢字」「IBM拡張漢字」が文字化けしていることが確認できる。
![]()
![]()

7) DemoBatchService.javaを以下のように修正し、文字コード=MS932で、4)のファイルを取り込むものとする。なお、下図ではimport文の多くを省略している。
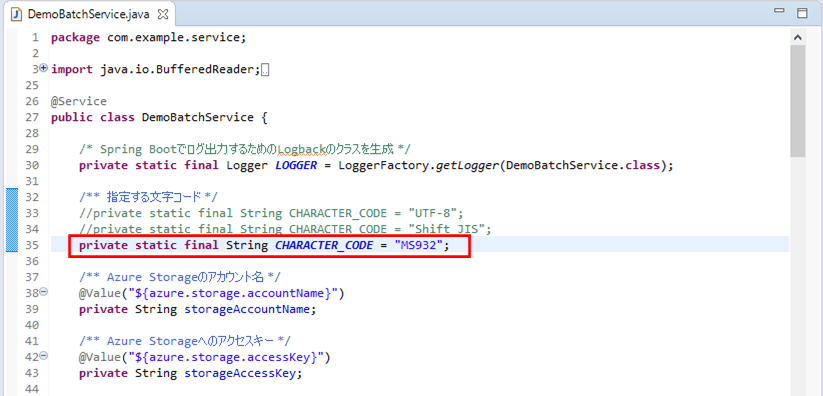
8) 4)のファイルをDBに取り込んだ結果は、以下の通りで、「第3水準漢字」「第4水準漢字」「IBM拡張漢字」の文字化けが解消されていることが確認できる。
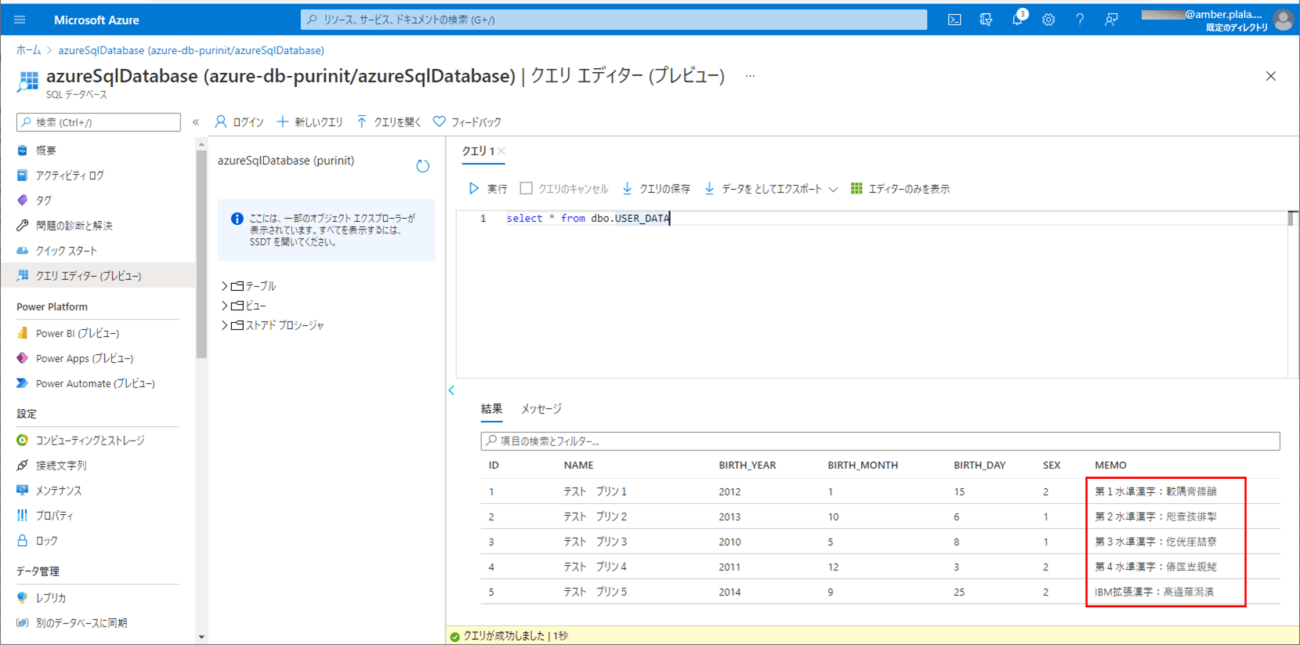
これは、MS932がShift_JIS を拡張した文字コードであるためである。詳細は以下のサイトを参照のこと。
https://weblabo.oscasierra.net/shift_jis-windows31j/
要点まとめ
- 漢字データを正しく取り込むには、CSVファイルがUTF-8の場合は「UTF-8」を、CSVファイルがShift_JISの場合は「MS932」を、指定する必要がある。





